豆瓣电影爬虫和分析
引言
最近做了一个豆瓣电影的爬虫并且进行了简单的数据分析,我会在博客里面记录下来。其实之前也做过一些爬虫,但一直没有写博客的习惯,太懒了。所以决定以后写得一些小爬虫或者什么demo都记录下来。
1.程序环境
本文使用Python 3,用到了re,requests,json,csv,time,matplotlib,pandas这些库。过程可能写得不一定会很细致。如果问题希望大家指出。也希望我这篇博客对于初学者能有一定的帮助。
2.程序目的
本文主要是对豆瓣电影选取豆瓣高分,按评价排序的顺序进行电影信息的爬取,如下图。
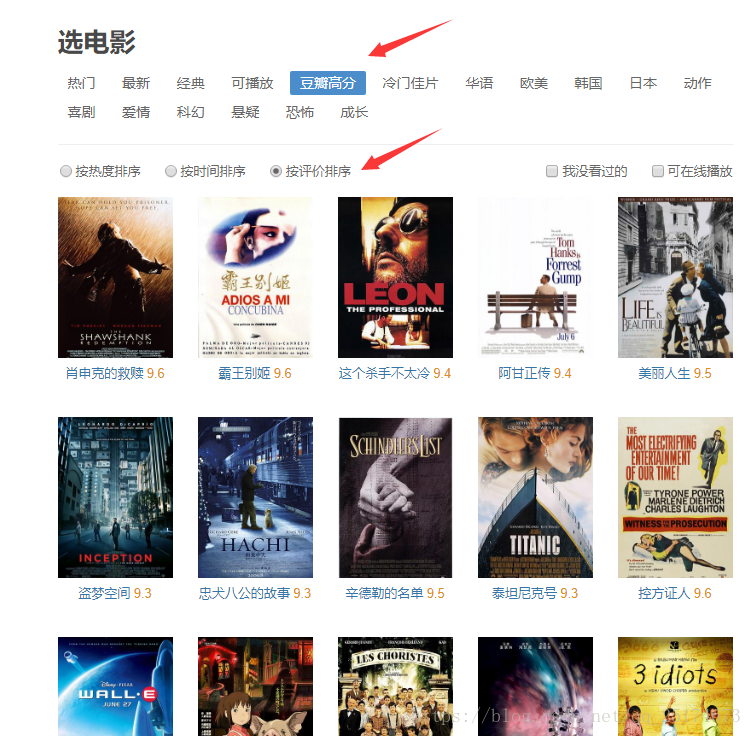
我们需要对该页面的电影信息进行爬取,获得电影名称,评分,地区,语言,导演,演员,时长,评价人数,电影类型等信息。这只是一个索引页,完整的电影信息在每一个电影链接里面。我们需要通过获取该索引页,然后解析索引页获取每个电影的详细链接,然后再从详细链接中获取电影信息。首先分析索引页。
3.索引页分析
在索引页我们按F12打开开发者工具,点击XHR标签,因为他是通过ajax加载获取更多的电影信息的。在开发者工具中我们可以看到索引页中的信息是一个json格式的数据。里面包含了每部电影详情的链接。所以先获取这些链接。
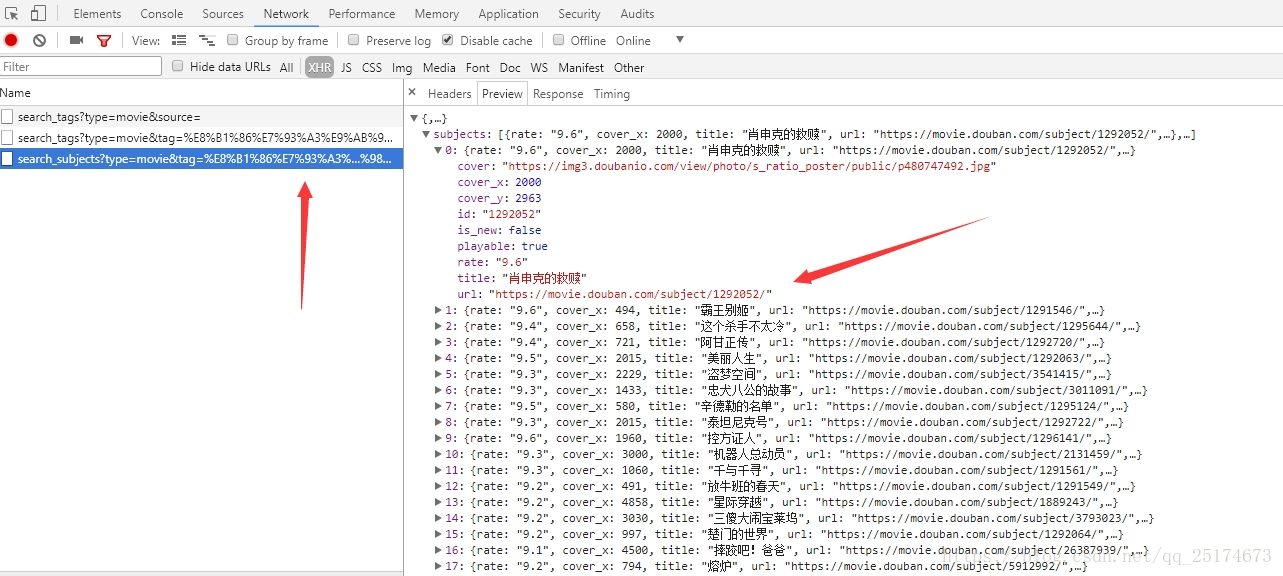
Python代码如下
# 获取索引页
def get_index_page(html):
try:
response = requests.get(url=html, headers=headers, cookies=cookies)
response.encoding = 'utf-8'
if response.status_code == 200:
return response.text
return None
except RequestException:
print('获取索引页错误')
time.sleep(3)
return get_index_page(html)
# 解析索引页
def parse_index_page(html):
html = get_index_page(html)
html = html[12:-1]
data = json.loads(html)
id_list = []
if data:
for item in data:
id_list.append(item['url'])
return id_list运行此段代码即可获得一个包含电影详情链接的列表id_lis。如需加载更多电影信息,点击加载更多查看XHR网址变化。我们点击发现只需要
https://movie.douban.com/j/search_subjects?type=movie&tag=%E8%B1%86%E7%93%A3%E9%AB%98%E5%88%86&sort=rank&page_limit=20&page_start=把这段网址后面加上20的倍数即可加载下一页。
4.详情页分析
获得了电影详情链接之后,即可进行解析详情页信息。详情页我们需要的信息都在网页源码中,我们只需要对网页源码使用正则提取我们需要的信息即可。
Python代码如下
# 获取详情页
def get_detail_page(html):
try:
response = requests.get(url=html, headers=headers, cookies=cookies)
response.encoding = 'utf-8'
if response.status_code == 200:
return response.text
return None
except RequestException:
print('获取详情页错误')
time.sleep(3)
return get_detail_page(html)
# 解析详情页
def parse_detail_page(data):
html = get_detail_page(data)
info = []
# 获取电影名称
name_pattern = re.compile('<span property="v:itemreviewed">(.*?)</span>')
name = re.findall(name_pattern, html)
info.append(name[0])
# 获取评分
score_pattern = re.compile('rating_num" property="v:average">(.*?)</strong>')
score = re.findall(score_pattern, html)
info.append(score[0])
# 获取导演
director_pattern = re.compile('rel="v:directedBy">(.*?)</a>')
director = re.findall(director_pattern, html)
info.append(director)
# 获取演员
actor_pattern = re.compile('rel="v:starring">(.*?)</a>')
actor = re.findall(actor_pattern, html)
info.append(actor)
# 获取年份
year_pattern = re.compile('<span class="year">\((.*?)\)</span>')
year = re.findall(year_pattern, html)
info.append(year[0])
# 获取类型
type_pattern = re.compile('property="v:genre">(.*?)</span>')
type = re.findall(type_pattern, html)
info.append(type[0].split(' /')[0])
# 获取时长
try:
time_pattern = re.compile('property="v:runtime" content="(.*?)"')
time = re.findall(time_pattern, html)
info.append(time[0])
except:
info.append('1')
# 获取语言
language_pattern = re.compile('pl">语言:</span>(.*?)<br/>')
language = re.findall(language_pattern, html)
info.append(language[0].split(' /')[0])
# 获取评价人数
comment_pattern = re.compile('property="v:votes">(.*?)</span>')
comment = re.findall(comment_pattern, html)
info.append(comment[0])
# 获取地区
area_pattern = re.compile(' class="pl">制片国家/地区:</span>(.*?)<br/>')
area = re.findall(area_pattern, html)
info.append(area[0].split(' /')[0])
return info5.数据写入
获取到电影信息之后写入CSV文件即可
6.数据分析
在进行数据分析之前我把之前输出的CSV文件另存为了EXCEL文件,并且加了一列名次信息。数据展示如下图
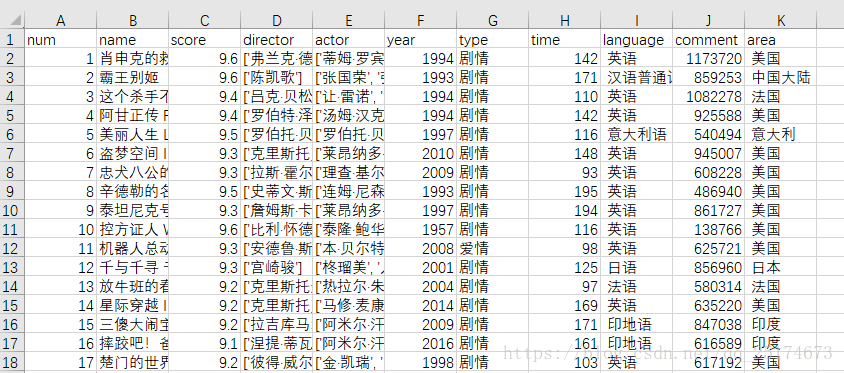
因为Matplotlib图例中显示中文有乱码,使用一下代码解决该问题
plt.rcParams['font.family'] = 'SimHei' #配置中文字体
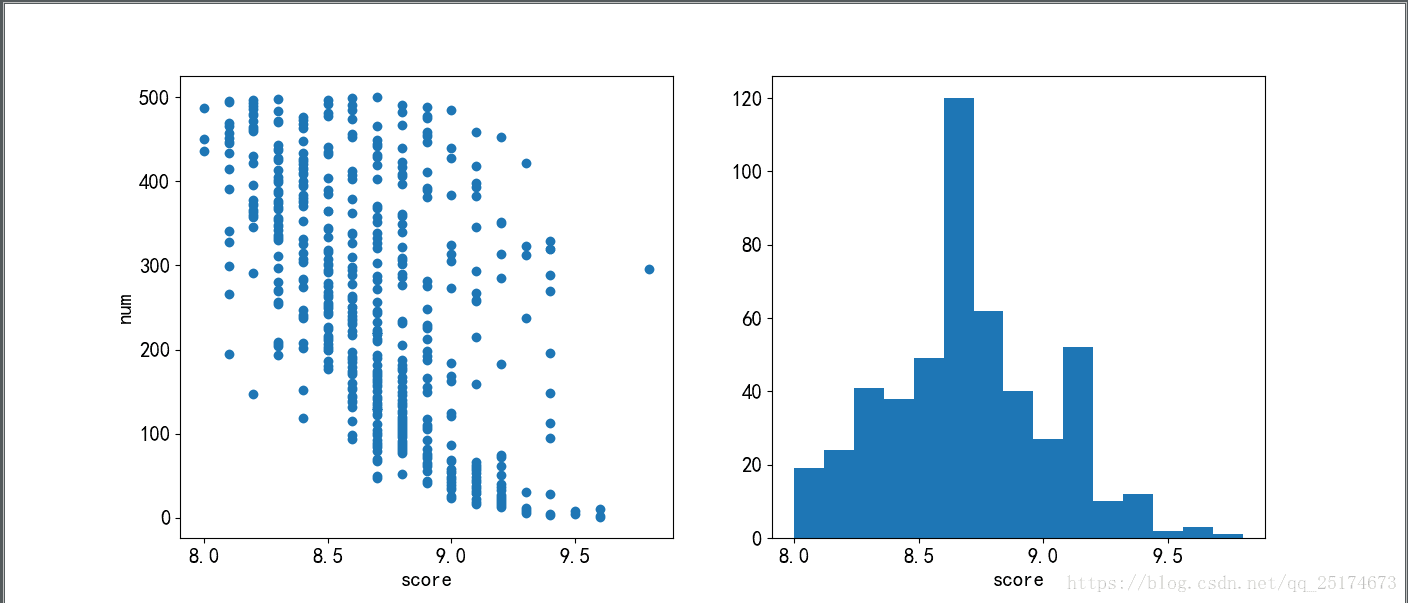
plt.rcParams['font.size'] = 15 # 更改默认字体大小制作第一部分图片,了解评分与排名的关系
#第一部分图片,评分与排名的关系图
plt.figure(figsize=(14,6))
plt.subplot(1,2,1) #一行两列第一个图
plt.scatter(score,num)
plt.xlabel('score')
plt.ylabel('num')
plt.subplot(1,2,2)
plt.hist(score,bins = 15) #bins指定有几条柱状
plt.xlabel('score')
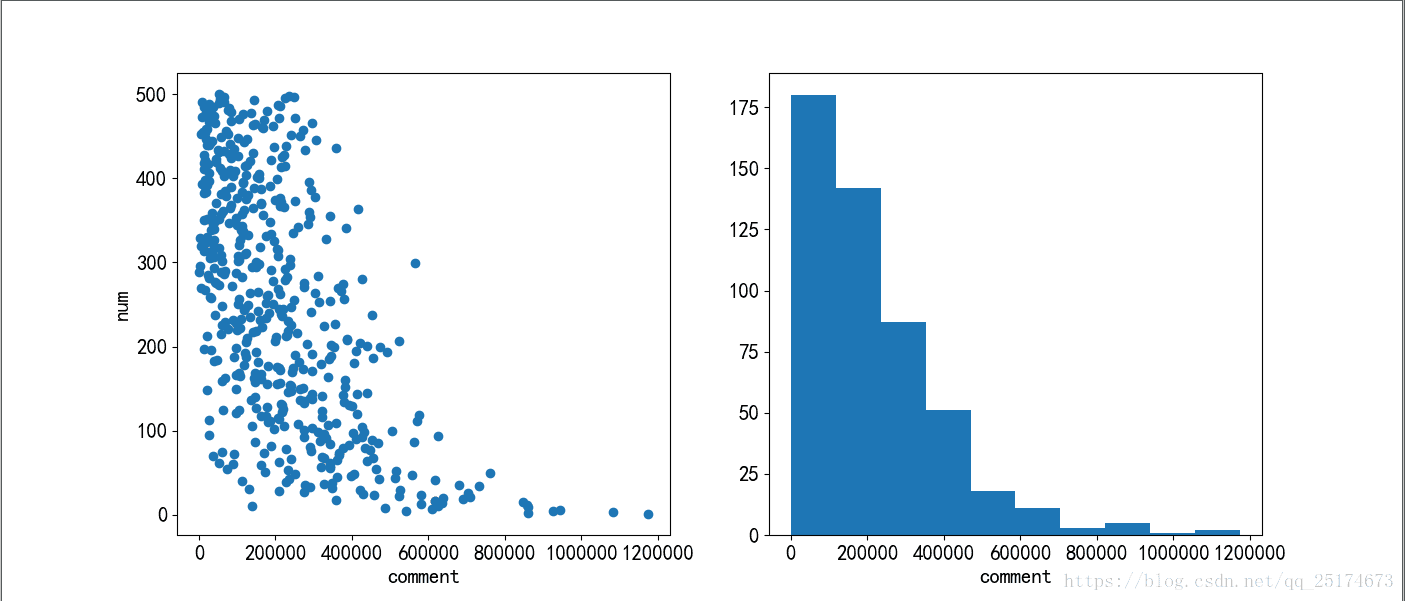
plt.show()制作第二部分图片,了解评论人数与排名的关系
#第二部分图片,评论人数与排名的关系图
plt.figure(figsize=(14,6))
plt.subplot(1,2,1) #一行两列第一个图
plt.scatter(comment,num)
plt.xlabel('comment')
plt.ylabel('num')
plt.subplot(1,2,2)
plt.hist(comment)
plt.xlabel('comment')
plt.show()制作第三部分图片,了解电影时长与排名的关系
#第三部分图片,排名与电影时长的关系图
for i in range(len(time)):
if time[i] == 60: #数据中有一个时长1分钟的,是错误数据需要剔除
del time[i]
del num[i]
plt.figure(figsize=(14,6))
plt.subplot(1,2,1) #一行两列第一个图
plt.scatter(time,num)
plt.xlabel('time')
plt.ylabel('num')
plt.subplot(1,2,2)
plt.hist(time)
plt.xlabel('time')
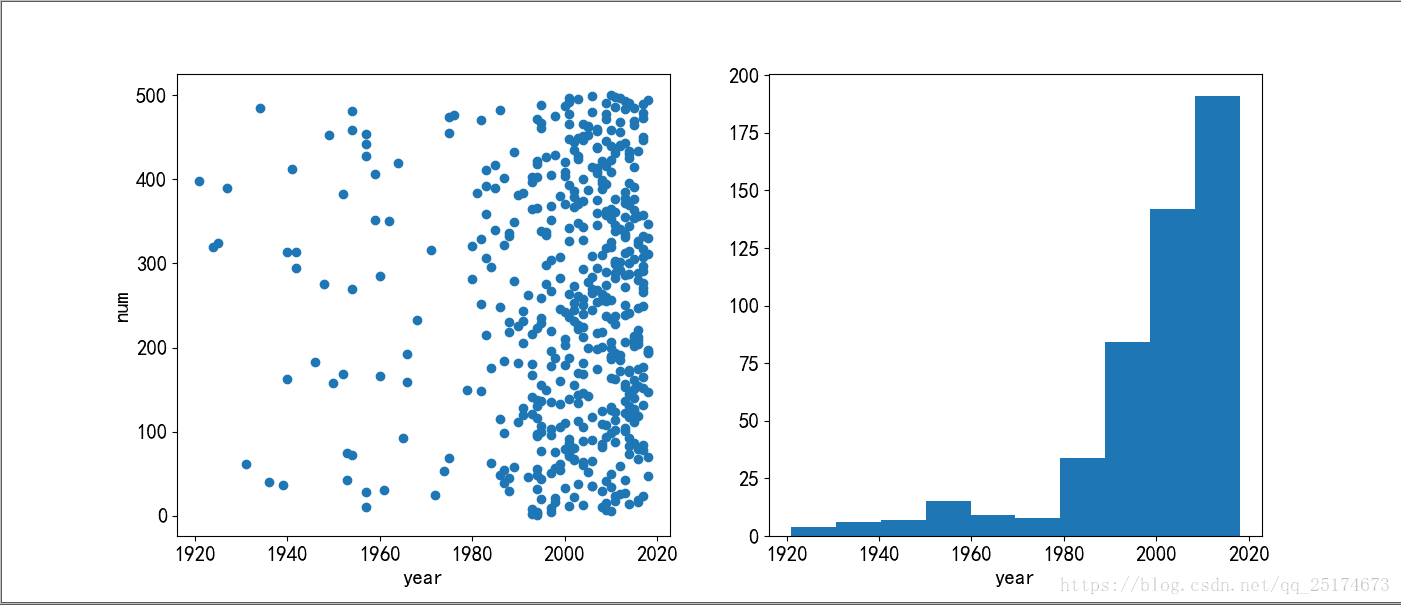
plt.show()制作第四部分图片,了解上映年份与排名的关系
#第四部分图片,上映年份与排名的关系图
plt.figure(figsize=(14,6))
plt.subplot(1,2,1) #一行两列第一个图
plt.scatter(year,num)
plt.xlabel('year')
plt.ylabel('num')
plt.subplot(1,2,2)
plt.hist(year)
plt.xlabel('year')
plt.show()制作第五部分图片,了解上映地区影片数量
# 第五部分图片,上映地区影片数量统计
area = area.apply(pd.value_counts).fillna('0')
area = area.astype(int)
area = area.apply(lambda x: x.sum(),axis = 1)
area_c = pd.DataFrame(area, columns = ['counts'])
area_c.sort_values(by = 'counts',ascending = False).plot(kind ='bar', figsize = (10,10))
plt.show()制作第六部分图片,了解语言影片数量
#第六部分图片,语言影片数量统计
language = language.apply(pd.value_counts).fillna('0')
language = language.astype(int)
language = language.apply(lambda x: x.sum(),axis = 1)
language = pd.DataFrame(language, columns = ['counts'])
language.sort_values(by = 'counts',ascending = False).plot(kind ='bar', figsize = (10,10))
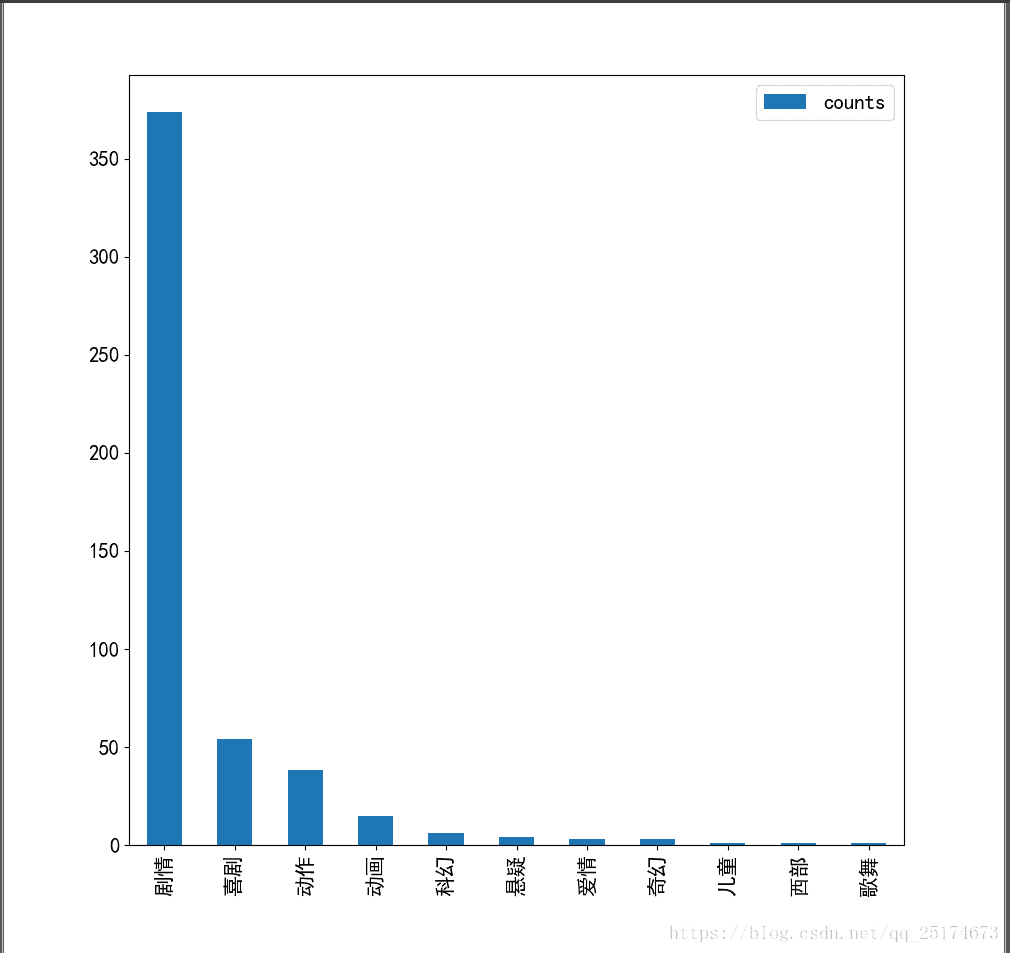
plt.show()制作第七部分图片,了解类型影片数量
#第七部分图片,类型影片数量统计
categroy = categroy.apply(pd.value_counts).fillna('0')
categroy = categroy.astype(int)
categroy = categroy.apply(lambda x: x.sum(),axis = 1)
categroy = pd.DataFrame(categroy, columns = ['counts'])
categroy.sort_values(by = 'counts',ascending = False).plot(kind ='bar', figsize = (10,10))
plt.show()将地区,语言,类型三类信息加起来制作词云
from wordcloud import WordCloud
language = language.to_string(header=False, )
area = area.to_string(header=False, )
categroy = categroy.to_string(header=False, )
data = language+area+categroy
wordcloud = WordCloud(font_path='./fonts/simhei.ttf',background_color='white',width=5000, height=3000, margin=2).generate(data)
plt.figure(figsize=(16,8))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()