1 onnx模型的保存
在网络训练结束之后,通常会将模型的权重参数保存到.pth或.pt文件中,如果部署环境中有pytorch,那么直接新建一个模型类对象,然后导入权重参数即可,但如果部署环境中只有OpenCV,没有pytorch,那么该如何部署呢?
答:先在训练环境中将.pth文件转成onnx文件,再将onnx文件部署到最终的环境中,导出onnx文件的命令为torch.onnx.export即可。
import torch
import torchvision as tv
from torch.utils.data import DataLoader
class CNN_Mnist(torch.nn.Module):
def __init__(self):
super(CNN_Mnist, self).__init__()
self.cnn_layers = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=1, out_channels=8, kernel_size=3, padding=1, stride=1),
torch.nn.MaxPool2d(kernel_size=2, stride=2),
torch.nn.ReLU(),
torch.nn.Conv2d(in_channels=8, out_channels=32, kernel_size=3, padding=1, stride=1),
torch.nn.MaxPool2d(kernel_size=2, stride=2),
torch.nn.ReLU()
)
self.fc_layers = torch.nn.Sequential(
torch.nn.Linear(7 * 7 * 32, 200),
torch.nn.ReLU(),
torch.nn.Linear(200, 100),
torch.nn.ReLU(),
torch.nn.Linear(100, 10),
torch.nn.LogSoftmax(dim=1)
)
def forward(self, x):
out = self.cnn_layers(x)
out = out.view(-1, 7 * 7 * 32)
out = self.fc_layers(out)
return out
def train_and_test():
model = CNN_Mnist().cuda()
print("Model's state_dict:")
for param_tensor in model.state_dict():
print(param_tensor, "\t", model.state_dict()[param_tensor].size())
loss = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
for s in range(5):
print("run in epoch : %d" % s)
for i, (x_train, y_train) in enumerate(train_dl):
x_train = x_train.cuda()
y_train = y_train.cuda()
y_pred = model.forward(x_train)
train_loss = loss(y_pred, y_train)
if (i + 1) % 100 == 0:
print(i + 1, train_loss.item())
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
torch.save(model.state_dict(), './cnn_mnist_model.pt')
model.eval()
total = 0
correct_count = 0
for test_images, test_labels in test_dl:
pred_labels = model(test_images.cuda())
predicted = torch.max(pred_labels, 1)[1]
correct_count += (predicted == test_labels.cuda()).sum()
total += len(test_labels)
print("total acc : %.2f\n" % (correct_count / total))
if __name__ == '__main__':
# 数据预处理方法
transform = tv.transforms.Compose([tv.transforms.ToTensor(),
tv.transforms.Normalize((0.5,), (0.5,)),
])
# 数据集
train_ts = tv.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_ts = tv.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
# 数据集导入器
train_dl = DataLoader(train_ts, batch_size=32, shuffle=True, drop_last=False)
test_dl = DataLoader(test_ts, batch_size=64, shuffle=True, drop_last=False)
# 训练与测试
train_and_test()
# 模型的导入
model = CNN_Mnist()
model.load_state_dict(torch.load('cnn_mnist_model.pt'))
"""下面演示将模型转化为onnx格式文件"""
# 要把模型切换到评估状态,这样可以让某些层(如drop_out失效)
model.eval()
# 随机一个输入张量,这个张量的作用是告诉onnx框架,输入张量的shape是什么样的
dummy_input = torch.randn(1, 1, 28, 28)
# 导出onnx文件
torch.onnx.export(model, (dummy_input), 'cnn_mnist.onnx', verbose=True) # onnx文件可以通过netron查看结构
# verbose=True,则打印一些转换日志,并且onnx文件中会包含doc_string,即用于说明模型的文档字符串
这段程序执行完成后,就会在当前目录下得到一个名为“cnn_mnist.onnx”的文件
2 在OpenCV中调用onnx模型文件
OpenCV自3.3开始,加入了对深度学习网络的支持(即dnn模块),但只能提供推理预测,不能训练。OpenCV调用onnx文件也很方便,只需要cv.dnn.readNetFromONNX即可,剩下的部分就是调用OpenCV的相关API进行相关的前处理和设置。
import cv2 as cv
import numpy as np
def mnist_onnx_demo():
# 从onnx文件中读取网络
mnist_net = cv.dnn.readNetFromONNX("cnn_mnist.onnx")
# 读取图片并做相应的预处理
image = cv.imread("test.png")
gray = cv.cvtColor(image, cv.COLOR_BGR2GRAY)
cv.imshow("input", gray)
blob = cv.dnn.blobFromImage(gray, 0.00392, (28, 28), (127.0)) / 0.5 # 这个API稍后会讲
"""上面对应图像在pytorch中的变换
tv.transforms.Compose([tv.transforms.ToTensor(),
tv.transforms.Normalize((0.5,), (0.5,)),])
ToTensor()是将图像的每个像素(或灰度)值压缩在[0,1]之间;
Normalize((0.5,), (0.5,))是对图像中每个像素进行运算:(x-0.5)/0.5,这里x的值在0-1之间;
cv.dnn.blobFromImage的第一个输入参数是要处理的图像,可以是二维(灰度图),也可以是三维(彩色图),
但必须是np.uint8类型,否则报错;
第二个参数0.00392是1.0/255,因为ToTensor()是把图像压缩到0-1,所以要乘以1/255,即0.00392,
当然,这个因子需要在图像整体减去平均值之后再乘,而这个平均值,就是第四个参数(127.0),
虽然真实的均值未必是127,但Normalize中就是这么指定的,OpenCV的接口也只能这么写;
因此,第二个和第四个参数,代表的变换是图像中的每个像素:(X-127)/255.0,
在cv.dnn.blobFromImage接口外面又出了一次0.5,则相当于:(X-127)/255.0/0.5=(X/255 - 0.5)/0.5,
此时与ToTensor()和Normalize((0.5,), (0.5,))对应起来了;
(28, 28)是将图片resize到(28, 28),这是模型的输入尺寸;
(127.0)"""
print(blob.shape)
# 前向传播,OpenCV的dnn模块,前向传播需要先设置网络的输入
mnist_net.setInput(blob)
result = mnist_net.forward()
# 后处理
pred_label = np.argmax(result, 1)
print("predit label : %d" % pred_label)
cv.waitKey(0)
cv.destroyAllWindows()
# 整个过程没有调用pytorch框架,也没使用模型对应的类,也就是说,onnx文件可以摆脱对框架的依赖
if __name__ == '__main__':
mnist_onnx_demo()
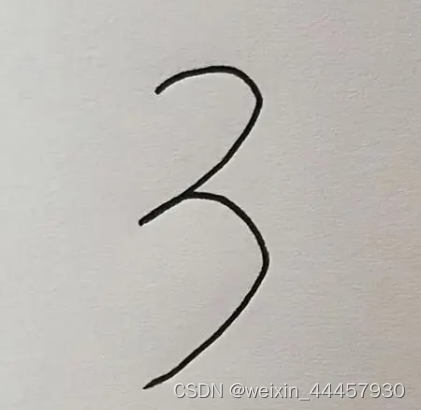
输出:
(1, 1, 28, 28)
predit label : 3
可以看到,部署的过程中,完全拜托了对pytorch框架的依赖。
这里面比较重要的是cv2.dnn.blobFromImage这个函数,它的作用是将图像转化为网络模型的输入,API如下:
cv2.dnn.blobFromImage(image[, scalefactor[, size[, mean[, swapRB[, crop[, ddepth]]]]]])
作用:
对图像进行预处理,包括减均值,比例缩放,裁剪,交换通道等,返回一个4通道的blob(blob可以简单理解为一个N维的数组,用于神经网络的输入)
参数:
image:输入图像(1、3或者4通道),因为OpenCV默认其是图像,因此其类型必须是np.uint8,否则报错
可选参数
scalefactor:图像各通道数值的缩放比例(图像减去mean之后缩放的比例)
size:图像要转化成的空间尺寸,如size=(200,300)表示高h=300,宽w=200,相当于resize
mean:用于各通道减去的值,以降低光照的影响(e.g. image为BGR3通道的图像,mean=[104.0, 177.0, 123.0],表示b通道的值-104,g-177,r-123)
scalefactor和mean如果是一个值,则是同时对各个通道都使用
swapRB:交换RB通道,默认为False.(cv2.imread读取的是彩图是bgr通道)
crop:图像裁剪,默认为False.
当值为True时,先按保持原来的高宽比缩放,直到其中一条边等于对应方向的长度,另一条边大于对应方向长度,然后从中心裁剪成size尺寸;
如果值为False,则不管高宽比,直接缩放成指定尺寸(即size参数)。
e.g.原图(300, 200),目标尺寸(400, 300)
若crop=True, (300, 200) --resize-->(450, 300)--crop-->(400, 300)
若crop=False, (300, 200) --resize-->(400, 300)
ddepth:输出的图像深度,可选CV_32F 或者 CV_8U.