参考:DSSM双塔模型取user、item侧模型单独保存
https://blog.csdn.net/olizxq/article/details/118068337
大体结构
dict_trained = model.state_dict() # trained model
trained_lst = list(dict_trained.keys())
# user tower
model_user = DSSM(user_feature_columns, [], task='binary', device=device)
dict_user = model_user.state_dict()
for key in dict_user:
dict_user[key] = dict_trained[key]
model_user.load_state_dict(dict_user)
1、pytorch 多路模型分布保存
本例是想使用clip模型(https://github.com/openai/CLIP)的encode_text这侧模型进行保存使用,因为双路模型torch暂时不支持保存onnx,所以取单路
TextModel.py(model.py单独复制一份更改)
class CLIP(nn.Module):
def __init__(self,
embed_dim:int,
context_length: int,
vocab_size: int,
transformer_width: int,
transformer_heads: int,
transformer_layers: int
):
super().__init__()
self.context_length = context_length
# if isinstance(vision_layers, (tuple, list)):
# vision_heads = vision_width * 32 // 64
# self.visual = ModifiedResNet(
# layers=vision_layers,
# output_dim=embed_dim,
# heads=vision_heads,
# input_resolution=image_resolution,
# width=vision_width
# )
# else:
# vision_heads = vision_width // 64
# self.visual = VisualTransformer(
# input_resolution=image_resolution,
# patch_size=vision_patch_size,
# width=vision_width,
# layers=vision_layers,
# heads=vision_heads,
# output_dim=embed_dim
# )
self.visual=None
self.transformer = Transformer(
width=transformer_width,
layers=transformer_layers,
heads=transformer_heads,
attn_mask=self.build_attention_mask()
)
self.vocab_size = vocab_size
self.token_embedding = nn.Embedding(vocab_size, transformer_width)
self.positional_embedding = nn.Parameter(torch.empty(self.context_length, transformer_width))
self.ln_final = LayerNorm(transformer_width)
self.text_projection = nn.Parameter(torch.empty(transformer_width, embed_dim))
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))
self.initialize_parameters()
def initialize_parameters(self):
nn.init.normal_(self.token_embedding.weight, std=0.02)
nn.init.normal_(self.positional_embedding, std=0.01)
if isinstance(self.visual, ModifiedResNet):
if self.visual.attnpool is not None:
std = self.visual.attnpool.c_proj.in_features ** -0.5
nn.init.normal_(self.visual.attnpool.q_proj.weight, std=std)
nn.init.normal_(self.visual.attnpool.k_proj.weight, std=std)
nn.init.normal_(self.visual.attnpool.v_proj.weight, std=std)
nn.init.normal_(self.visual.attnpool.c_proj.weight, std=std)
for resnet_block in [self.visual.layer1, self.visual.layer2, self.visual.layer3, self.visual.layer4]:
for name, param in resnet_block.named_parameters():
if name.endswith("bn3.weight"):
nn.init.zeros_(param)
proj_std = (self.transformer.width ** -0.5) * ((2 * self.transformer.layers) ** -0.5)
attn_std = self.transformer.width ** -0.5
fc_std = (2 * self.transformer.width) ** -0.5
for block in self.transformer.resblocks:
nn.init.normal_(block.attn.in_proj_weight, std=attn_std)
nn.init.normal_(block.attn.out_proj.weight, std=proj_std)
nn.init.normal_(block.mlp.c_fc.weight, std=fc_std)
nn.init.normal_(block.mlp.c_proj.weight, std=proj_std)
if self.text_projection is not None:
nn.init.normal_(self.text_projection, std=self.transformer.width ** -0.5)
def build_attention_mask(self):
# lazily create causal attention mask, with full attention between the vision tokens
# pytorch uses additive attention mask; fill with -inf
mask = torch.empty(self.context_length, self.context_length)
mask.fill_(float("-inf"))
mask.triu_(1) # zero out the lower diagonal
return mask
@property
def dtype(self):
return next(self.parameters()).dtype
# return self.visual.conv1.weight.dtype
def encode_image(self, image):
return self.visual(image.type(self.dtype))
def encode_text(self, text):
x = self.token_embedding(text).type(self.dtype) # [batch_size, n_ctx, d_model]
x = x + self.positional_embedding.type(self.dtype)
x = x.permute(1, 0, 2) # NLD -> LND
x = self.transformer(x)
x = x.permute(1, 0, 2) # LND -> NLD
x = self.ln_final(x).type(self.dtype)
# x.shape = [batch_size, n_ctx, transformer.width]
# take features from the eot embedding (eot_token is the highest number in each sequence)
x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)] @ self.text_projection
return x
def forward(self, text):
# image_features = self.encode_image(image)
text_features = self.encode_text(text)
# normalized features
# image_features = image_features / image_features.norm(dim=-1, keepdim=True)
text_features = text_features / text_features.norm(dim=-1, keepdim=True)
# cosine similarity as logits
# logit_scale = self.logit_scale.exp()
# logits_per_image = logit_scale * image_features @ text_features.t()
# logits_per_text = logit_scale * text_features @ image_features.t()
# shape = [global_batch_size, global_batch_size]
# return logits_per_image, logits_per_text
return text_features
save.py 保存单路encode_text
import torch
from torch import nn
import clip
from clip.TextModel import CLIP
# from clip.model import CLIP
import torch.onnx
from PIL import Image
# 加载模型
device = "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
# text1 = clip.tokenize(["hello"]).to(device)
# print(text1)
# print(type(text1))
dict_trained = model.state_dict() # trained model
trained_lst = list(dict_trained.keys())
# print(dict_trained)
print(trained_lst)
# image1 = preprocess(Image.open(r"D:\openai\game_imgs\208462401.jpg")).unsqueeze(0)
model_txt = CLIP(embed_dim=512,context_length=77,vocab_size=49408,transformer_width=512,transformer_heads=16,transformer_layers=6)
dict_txt = model_txt.state_dict()
print(dict_txt)
for key in dict_txt:
dict_txt[key] = dict_trained[key]
model_txt.load_state_dict(dict_txt)
print(model_txt)
# # 保存整个网络
torch.save(model_txt, "./single_model_text1.pkl")
# model_dict=torch.load(PATH)
# del model_txt
# # 加载
# model_txt = torch.load('./single_model_text1.pkl')
text1 = clip.tokenize(["hello"]).to(device)
print(text1)
print(text1.shape)
with torch.no_grad():
text_features = model_txt.encode_text(text1)
print(text_features.shape)
print(text_features)
2、转onnx再pb再tf serving使用
a、转onnx
import torch
import torchvision
import torch.onnx
import torch.nn as nn
import clip
device = "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
text1 = clip.tokenize(["hello"]).to(device)
print(text1)
print(type(text1))
# 加载
model_txt = torch.load('./single_model_text1.pkl')
torch.onnx.export(model_txt, text1, "./single_model_text.onnx")
b、onnx再转pb
tf2版本里、!pip install onnx onnx_tf
import onnx
import numpy as np
from onnx_tf.backend import prepare
model = onnx.load(r'D:\ope**8L1\single_model_text.onnx')
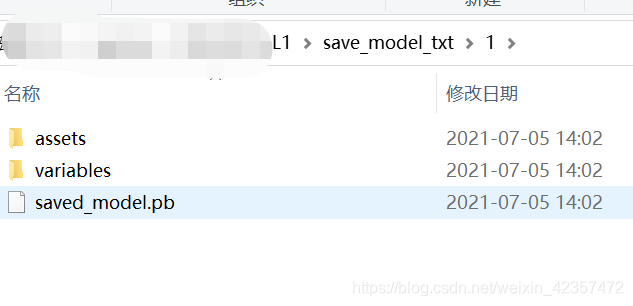
tf_model = prepare(model)
tf_model.export_graph(r'D:\op***L1\save_model_txt\1')
c、tf serving加载
docker run -p 8080:8080 -p 8081:8081 --mount type=bind,source=D:/ope***L1/save_model_txt/,target=/models/my_model -e MODEL_NAME=my_model -t tensorflow/serving --port=8080 --rest_api_port=8081
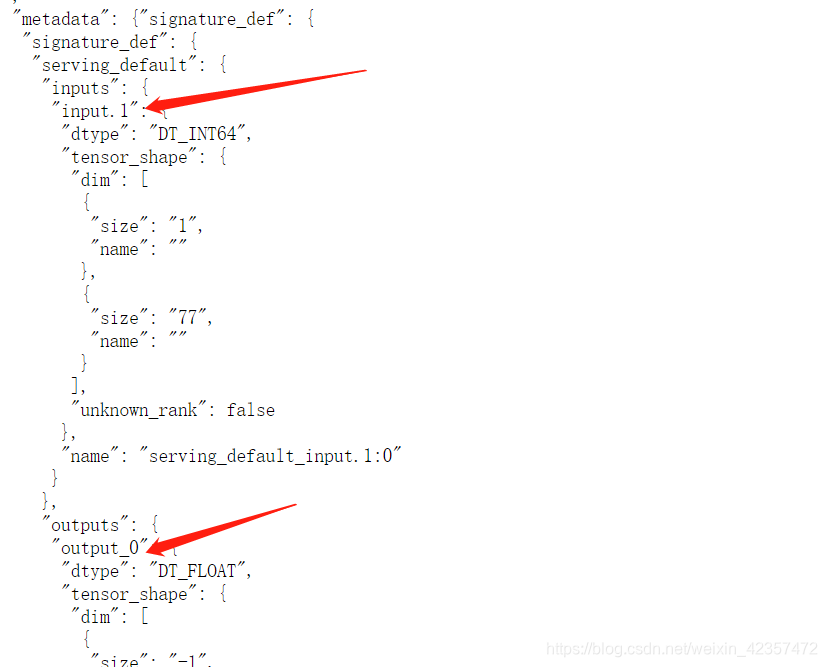
#查看模型输入输出结构
http://localhost:8081/v1/models/my_model/metadata
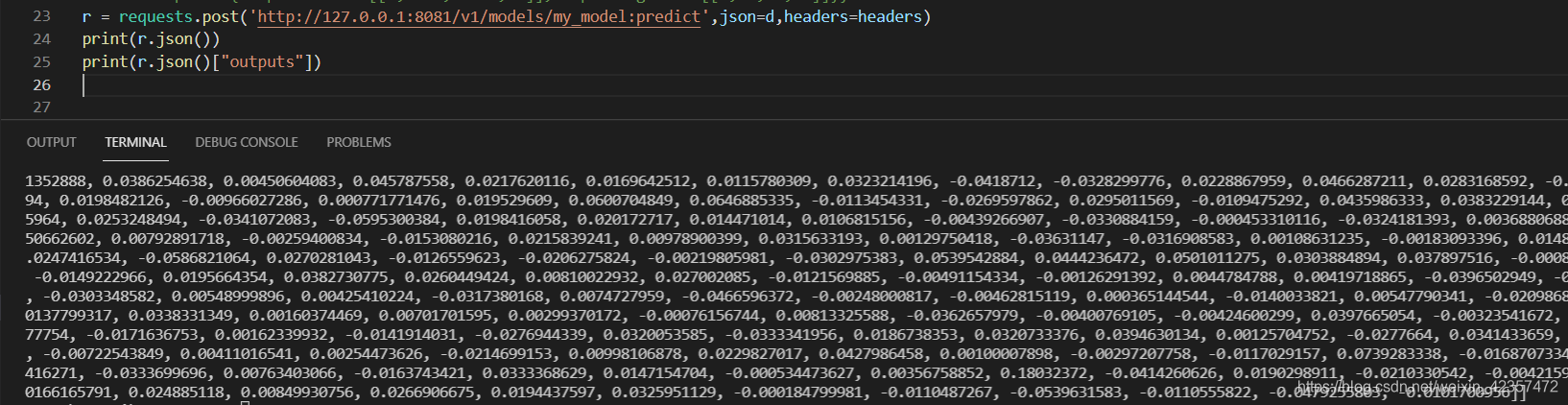
d、request请求查看
##运行测试(text是hello)
import requests
import json
import torch
import clip
device = "cpu"
text1 = clip.tokenize(["hello"]).to(device)
aa = text1.numpy().tolist()
print(aa)
headers = {"content-type": "application/json"}
d = {"signature_name": "serving_default",
"inputs":{"input.1":aa}}
r = requests.post('http://127.0.0.1:8081/v1/models/my_model:predict',json=d,headers=headers)
print(r.json())
print(r.json()["outputs"])