【conda虚拟环境安装CUDA路径】_conda cuda 安装目录_一苇以航_aw的博客-CSDN博客
(在大部分的场景我们都需要查看自己配置的环境)
这里给了python检测环境的方法:
import torch
import tensorrt
print(torch.__version__)# 1.7.1
print(torch.version.cuda)# 11.0
print(torch.backends.cudnn.version())# 8005
print(tensorrt.__version__)8.4.3.1
输入conda list命令也可以看环境的配置:


【conda虚拟环境安装CUDA路径】_conda cuda 安装目录_一苇以航_aw的博客-CSDN博客
1.TensorRT安装:
快速入门指南 :: NVIDIA 深度学习 TensorRT 文档
python下的安装TensorRTwin10/linux超简单安装TensorRT 在python使用_cuda initialization failure with error: 100. pleas_凌十一的博客-CSDN博客
我是用的是python安装,因此要验证TensorRT是否安装正确,命令如下:
# 导入tensorrt模块
import tensorrt
# 确定TensorRT安装的版本
print(tensorrt.__version__)
# 创建一个Builder对象来验证CUDA安装是否工作
print(tensorrt.__version__)2.基本TensorRT的工作流程
TensorRT 提供了多个部署选项,但所有工作流都涉及将模型转换为优化表示,TensorRT 将其称为引擎。
构建一个TensorRT工作流程包含两个方面:
1.选择正确的部署选项
2.选择正确的引擎参数组合
必须遵循五个基本步骤来转换和部署模型:

TensorRT生态系统分为两部分:
1.用户可以通过允许的各种路径转换成TensorRT engine(引擎)
2.在部署优化的TensorRT引擎时,不同的运行时用户可以使用TensorRT进行目标定位。

2.1 转换
TensorRT转换模型有三个主要选项:
- 使用 TF-TRT
- 从文件自动转换 ONNX.onnx
- 使用 TensorRT API 手动构建网络(C++ 或 蟒蛇)
由于我使用的是pytorch,因此转换的步骤选择了ONNX选项。
官方文档中是这样解释的:
自动模型转换和部署的一个更有效的选择是使用ONNX进行转换。ONNX是与框架无关的选项,适用于TensorFlow、PyTorch等中的模型。TensorRT支持使用TensorRT API从ONNX文件自动转换,或者使用 trtexec -我们将在本指南中使用trtexec。ONNX转换是全有或全无,即模型中的所有操作都必须由TensorRT (或者必须为不支持的操作提供自定义插件)支持。ONNX转换的结果是一个单一的TensorRT引擎,它允许比使用TF - TRT更少的开销。
2.2 部署
使用 TensorRT 部署模型有三个选项:
- 在 TensorFlow 中部署
- 使用独立的 TensorRT runtime API
- 使用 NVIDIA Triton 推理服务器
这里使用的是TensorRT runtime API进行部署。
官网解释如下:
TensorRT运行时API允许最低的开销和最细粒度的控制,但是TensorRT不支持的操作符必须以插件(这里提供了一个预写的插件库)的形式实现。TensorRT/plugin at main · NVIDIA/TensorRT · GitHub
使用运行时API进行部署的最常见路径是使用框架中的ONNX导出,这将在下一节中介绍。
2.3 选择一个正确的工作流程
选择如何转换和部署模型的两个重要的因素在于:
1.你框架的选择
2.your preferred TensorRT runtime to target(你想要TensortRT runtime 达到的目标)
有关可用的runtime选项的信息,可以参阅Jupyter notebook里的指南:
TensorRT/5. Understanding TensorRT Runtimes.ipynb at main · NVIDIA/TensorRT · GitHub

(这里的每一个流程都有链接可以链接)
3. 使用ONNX部署的示例
ONNX交换格式提供了一种从许多框架导出模型的方法,包括PyTorch与TensorFlow。
3.1 从PyTorch导出到ONNX
将 PyTorch 模型转换为 TensorRT 的一种方法是将 PyTorch 模型导出到 ONNX,然后转换为TensorRT引擎

服务器安装的onnx版本号为1.12.0:

自己电脑上安装的出现了error,但是好像也可以用。

安装onnxruntime,版本为1.14.1(对onnx进行推理加速,如果只用tensorRT的画其实不需要安装)
pip install onnxruntime -i https://pypi.tuna.tsinghua.edu.cn/simple
此时出现报错,你按照要求改就行了:

卸载了pip uninstall protobuf
原本安装protobuf版本为3.12.0,但是onnx要求更高版本:

于是随便换了个3.15版本
检查onnxruntime是否安装成功
由于水平的有限,代码是借鉴Bubbliiiing大佬的代码,大佬已经写好了convert_to_onnx函数。
训练好的.pth模型转为.onnx模型_conda install onnx_Bianca989898的博客-CSDN博客
因此我只需调用一下即可,在这里感谢博主所做的工作。
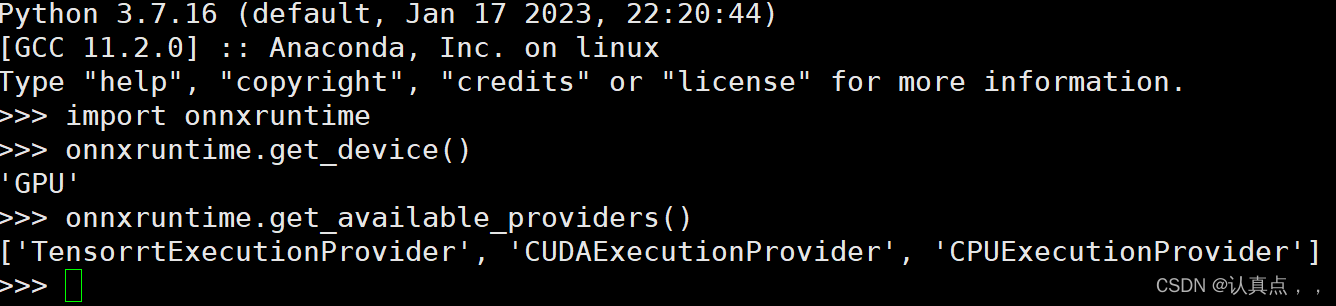
Netron在Netron可以查看导出的onnx可视化结果。
3.2 将ONNX转换成一个TensorRT engine
将 ONNX 文件转换为 TensorRT 引擎有两种主要方法:
- 用trtexec
- 使用 TensorRT API
本来按照网上的方法,trtexec放在安装包的位置
python pip安装的包放在哪里(site-packages目录的位置)_pip安装的包在哪里_西京刀客的博客-CSDN博客

但是我使用python pip安装的,没找到:
问题出在了pip安装,通过pip安装方式只是安装了TensorRT的运行时,没有提供trtexec工具。
TensorRT安装记录(8.2.5)_trtexec 安装_太阳花的小绿豆的博客-CSDN博客
因此重新用tar下载了,具体的安装步骤参考官方文档,博主和我安装的时间类似,因此我直接看了博主的(英文水平差), 跟着博主做没有任何问题。


由于使用的是学校的服务器,因此,只能添加临时的环境变量
添加的一个是TensorRT的lib文件以及
cudnn和cuda的lib
涉及到学校服务器内容被隐藏了。
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/mnt/inspurfs/user-fs/用户名/anaconda3/envs/虚拟环境名/lib
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/mnt/inspurfs/user-fs/用户名/anaconda3/envs/TensorRT-8.4.3.1/targets/x86_64-linux-gnu/lib在该目录下运行代码:
trtexec --onnx=ResNet50.onnx --saveEngine=trt_output/ResNet50.trt
运行结果如下:

这里给出trtexec的各种参数:
TensorRT - 自带工具trtexec的参数使用说明_HW140701的博客-CSDN博客
代码阅读help:
PyTorch:如何加载预训练参数?_fhcfhc1112的博客-CSDN博客
TensorRT(一)Windows+Anaconda配置TensorRT环境 (Python版 )TensorRT(二)TensorRT使用教程(Python版)Shell使用基础: