1. 简介
1.1 聚类的定义
聚类(Clustering)是按照某个特定标准(如距离)把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。也即聚类后同一类的数据尽可能聚集到一起,不同类数据尽量分离。
1.2 聚类和分类的区别
- 聚类(Clustering):是指把相似的数据划分到一起,具体划分的时候并不关心这一类的标签,目标就是把相似的数据聚合到一起,聚类是一种
无监督学习(Unsupervised Learning)方法。 - 分类(Classification):是把不同的数据划分开,其过程是通过训练数据集获得一个分类器,再通过分类器去预测未知数据,分类是一种
监督学习(Supervised Learning)方法。
1.3 聚类的一般过程
- 数据准备:特征标准化和降维
- 特征选择:从最初的特征中选择最有效的特征,并将其存储在向量中
- 特征提取:通过对选择的特征进行转换形成新的突出特征
- 聚类:基于某种距离函数进行相似度度量,获取簇
- 聚类结果评估:分析聚类结果,如距离误差和(SSE)等
1.4 数据对象间的相似度度量
数值型数据,使用下表中的相似度度量方法。
| 相似度度量准则 | 相似度度量函数 |
|---|---|
| Minkowski距离 | d ( x , y ) = ∣ ∑ i = 1 n ( x i − y i ) p ∣ 1 p d(x,y) = |\sum_{i=1}^n (x_i-y_i)^p|^\frac1p d(x,y)=∣∑i=1n(xi−yi)p∣p1 |
| Manhattan距离 | d ( x , y ) = ∑ i = 1 n ∣ ∣ x i − y i ∣ ∣ d(x,y) = \sum_{i=1}^n ||x_i-y_i|| d(x,y)=∑i=1n∣∣xi−yi∣∣ |
| Euclidean距离 | d ( x , y ) = ∑ i = 1 n ( x i − y i ) 2 d(x,y) = \sqrt{\sum_{i=1}^n (x_i-y_i)^2} d(x,y)=∑i=1n(xi−yi)2 |
| Chebyshev距离 | d ( x , y ) = m a x i = 1 , 2 … , n n ∣ ∣ x i − y i ∣ ∣ d(x,y) = max_{i=1,2…,n}^n||x_i-y_i|| d(x,y)=maxi=1,2…,nn∣∣xi−yi∣∣ |
Minkowski距离就是 L p L_p Lp范数( p ≥ 1 p≥1 p≥1),其中 Manhattan距离、Euclidean距离、Chebyshev距离分别对应 p = 1 , 2 , ∞ p=1,2,∞ p=1,2,∞ 时的情形。
1.5 cluster之间的相似度度量
除了衡量对象之间的距离之外,有些聚类算法(如层次聚类)还衡量cluster之间的距离 ,假设 C i C_i Ci和 C j C_j Cj 为两个 cluster,则前四种方法定义的 C i C_i Ci 和 C j C_j Cj 之间的距离如下表所示。
| 相似度度量准则 | 相似度度量函数 |
|---|---|
| Single-link | D ( C i , C j ) = m i n x ⊆ C i , y ⊆ C j d ( x , y ) D(C_i,C_j)=min_{x\subseteq C_i,y\subseteq C_j}\ d(x,y) D(Ci,Cj)=minx⊆Ci,y⊆Cj d(x,y) |
| Complete-link | D ( C i , C j ) = m a x x ⊆ C i , y ⊆ C j d ( x , y ) D(C_i,C_j)=max_{x\subseteq C_i,y\subseteq C_j}\ d(x,y) D(Ci,Cj)=maxx⊆Ci,y⊆Cj d(x,y) |
| UPGMA | D ( C i , C j ) = 1 ∣ ∣ C i ∣ ∣ ∣ ∣ C j ∣ ∣ ∑ x ⊆ C i , y ⊆ C j d ( x , y ) D(C_i,C_j)=\frac{1}{||C_i||||C_j||}\sum_{x\subseteq C_i,y\subseteq C_j}\ d(x,y) D(Ci,Cj)=∣∣Ci∣∣∣∣Cj∣∣1∑x⊆Ci,y⊆Cj d(x,y) |
| WPGMA | − - − |
- Single-link定义的两个cluster之间的距离:两个cluster之间距离最近的两个点之间的距离;
这种方法会在聚类的过程中产生链式效应,即有可能会出现非常大的cluster。 - Complete-link定义的两个cluster之间的距离:两个cluster之间距离最远的两个点之间的距离;
这种方法可以避免链式效应`,对异常样本点(不符合数据集的整体分布的噪声点)却非常敏感,容易产生不合理的聚类; - UPGMA定义的两个cluster之间的距离:两个cluster之间所有点距离的平均值;
它是Single-link和Complete-link方法的折中; - WPGMA:两个cluster 之间两个对象之间的距离的加权平均值;
加权的目的是为了使两个 cluster 对距离的计算的影响在同一层次上,而不受 cluster 大小的影响,具体公式和采用的权重方案有关。
2. 数据聚类方法
数据聚类方法主要分类:
- 划分式聚类方法(Partition-based Methods)
k-means、k-means++、bi-kmeans、K-Medians…… - 基于滑动窗口的方法
均值偏移聚类算法 - 基于密度的聚类方法(Density-based methods)
DBSCAN、OPTICS… - 层次化聚类方法(Hierarchical Methods)
Agglomerative、Divisive… - 新方法
量子聚类、核聚类、谱聚类…
2.1 划分式聚类方法
划分式聚类方法需要事先指定簇类的数目或者聚类中心,通过反复迭代,直至最后达到簇内的点足够近,簇间的点足够远的目标。
经典的划分式聚类方法有k-means及其变体k-means++、bi-kmeans、kernel k-means等。
2.1.1 k-means 算法
经典的k-means算法的流程如下:
- 创建k个点作为初始质心(通常是随机选择)
- 当任意一个点的簇分配结果发生改变时
1. 对数据集中的每个数据点
1. 对每个质心
1.计算质心与数据点之间的距离
2. 将数据点分配到距其最近的簇
2. 对每个簇,计算簇中所有点的均值并将均值作为质心
经典k-means源代码,图1.1中,通过观察发现大致可以分为4类,所以取 k = 4 k=4 k=4,图1.2为过程演示。
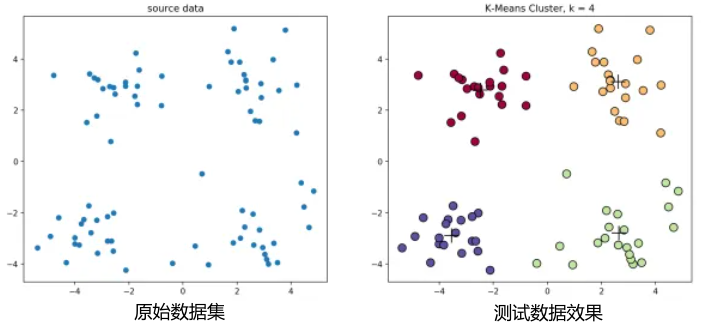
图1.1 K-Means聚类。原始数据集(左) 测试数据效果(右)
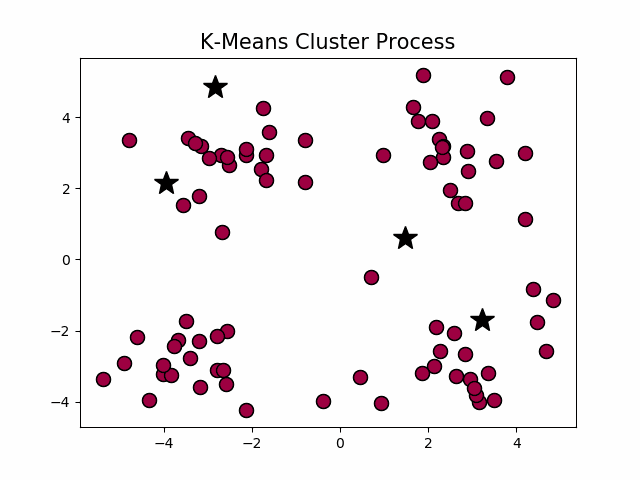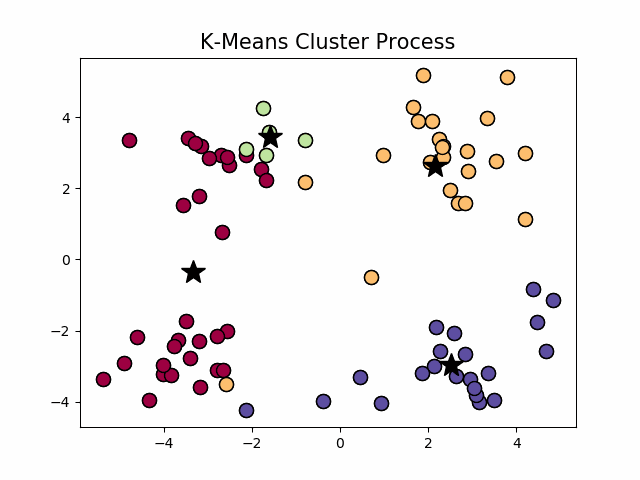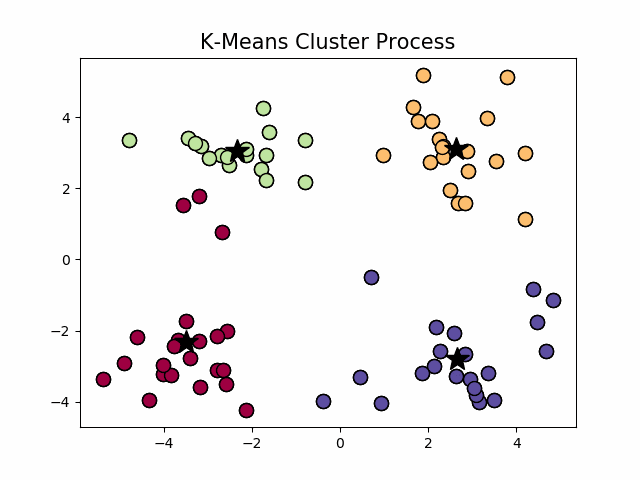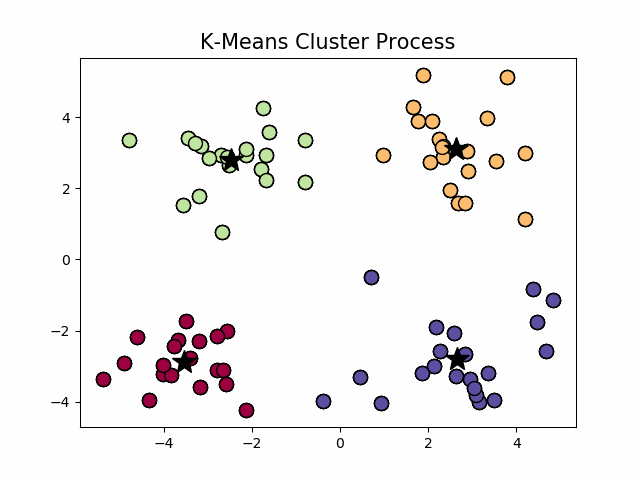
图1.2 k-means聚类过程
看起来很顺利,但事情并非如此,我们考虑k-means算法中最核心的部分,假设 x i ( i = 1 , 2 , … , n ) x_i(i=1,2,…,n) xi(i=1,2,…,n)是数据点, μ j ( j = 1 , 2 , … , k ) \mu_j(j=1,2,…,k) μj(j=1,2,…,k)是初始化的数据中心,那么目标函数为:
min ∑ i = 1 n min j = 1 , 2 , . . . , k ∣ ∣ x i − μ j ∣ ∣ 2 \min\sum_{i=1}^n \min \limits_{j=1,2,...,k}\left |\left | x_i -\mu_j\right | \right |^2 mini=1∑nj=1,2,...,kmin∣∣xi−μj∣∣2
这个函数是非凸优化函数,会收敛于局部最优解,可以参考证明过程。例如, μ 1 = [ 1 , 1 ] , μ 2 = [ − 1 , − 1 ] \mu_1=\left [ 1,1\right ] ,\mu_2=\left [ -1,-1\right ] μ1=[1,1],μ2=[−1,−1],则目标函数为:
z = min j = 1 , 2 ∣ ∣ x i − μ j ∣ ∣ 2 z=\min \limits_{j=1,2}\left |\left | x_i -\mu_j\right | \right |^2 z=j=1,2min∣∣xi−μj∣∣2
该函数的曲线如图1.3所示,可以发现该函数有两个局部最优点:
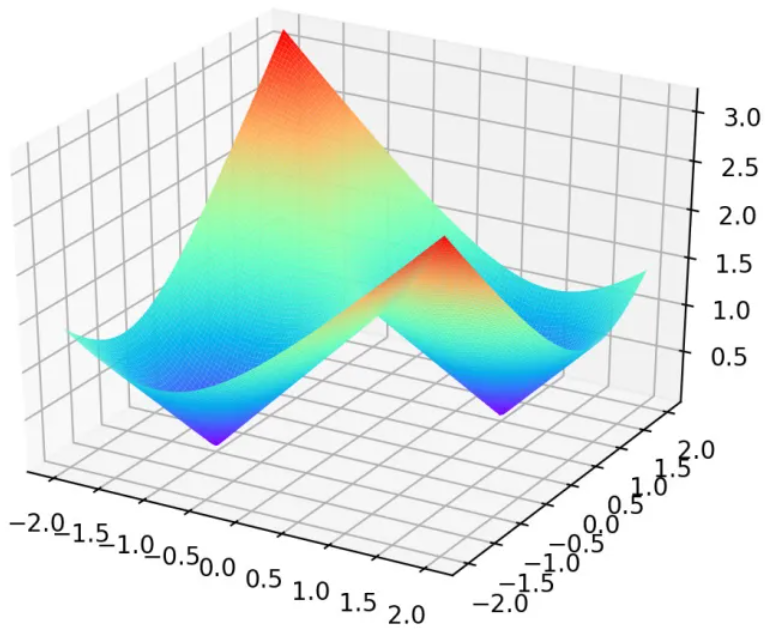
图1.3 目标函数曲线
当初始质心点取值不同的时候,最终的聚类效果也不一样。举一个具体的实例,根据图1.4(左),下方的数据应该归为一类,而上方的数据应该归为两类。图1.4(右)是由于初始质心点选取的不合理造成的误分。
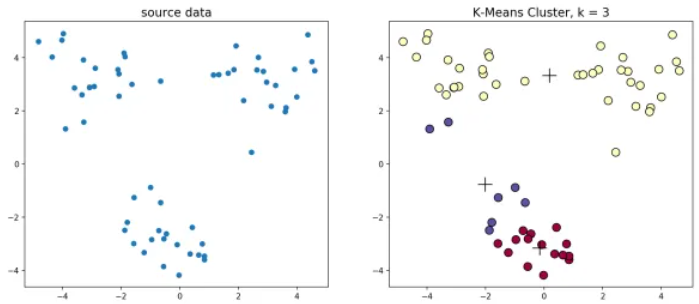
图1.4 初始质心点选取的不合理
k k k值的选取对结果的影响也非常大,同样取上图中数据集,取 k = 2 , 3 , 4 k=2,3,4 k=2,3,4可以得到如 图1.5 的聚类结果:

图1.5 不同 k 值
优点:
- 速度非常快,只是计算点和簇中心之间的距离,线性复杂度 O(n)。
缺点:
- 需要提前确定 k k k值。但我们希望它能从数据中获得一些启示,自动生成。
- 对初始质心点敏感。K-Means从随机选择的聚类中心开始,因此不同的运行可能产生不同的聚类结果。结果可能是不重复的,缺乏一致性。
- 对异常数据敏感
2.1.2 k-means++ 算法
k-means++是针对k-means中初始质心点选取的优化算法。该算法的流程和k-means类似,改变的地方只有初始质心的选取,该部分的算法流程如下:
- 随机选取一个数据点作为初始的聚类中心
- 当聚类中心数量小于k
1. 计算每个数据点与当前已有聚类中心的最短距离,用 D ( x ) D(x) D(x)表示, 这个值越大,表示被选取为下一个聚类中心的概率越大,最后使用轮盘法选取下一个聚类中心
k-means++源代码,使用k-means++对上述数据做聚类处理,得到的结果如图1.6:
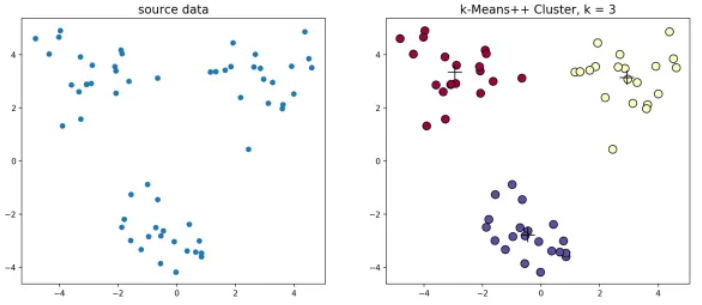
图1.6 k-means++聚类结果
2.1.3 bi-kmeans 算法
一种度量聚类效果的指标是 SSE(Sum of Squared Error),表示聚类后的簇离该簇的聚类中心的平方和,SSE越小,表示聚类效果越好。
bi-kmeans是针对kmeans算法会陷入局部最优的缺陷进行的改进算法。
该算法基于SSE最小化的原理,首先将所有的数据点视为一个簇,然后将该簇一分为二,之后选择其中一个簇继续进行划分,选择哪一个簇进行划分取决于对其划分是否能最大程度的降低SSE的值。
该算法的流程如下:
- 将所有点视为一个簇
- 当簇的个数小于k时
1. 对每一个簇
1. 计算总误差
2. 在给定的簇上面进行k- means聚类(ke = 2)
3. 计算将该簇一分为二之后的总误差
2. 选取使得误差最小的那个簇进行划分操作
bi-kmeans算法源代码,利用bi-kmeans算法处理上节中的数据得到的结果如图1.7所示。

图1.7 bi-kmeans聚类结果
这是全局最优的方法,所以每次计算出来的SSE值基本也是一样的(但是还是不排除有部分随机分错的情况)。
对比k-means、k-means++、bi-kmeans算法的SSE值:
| 序号 | k-means | k-means++ | bi-kmeans |
|---|---|---|---|
| 1 | 2112 | 120 | 106 |
| 2 | 338 | 125 | 106 |
| 3 | 824 | 127 | 106 |
| agv | 1108 | 124 | 106 |
可以发现,k-means每次计算出来的SSE都较大且不太稳定;k-means++计算出来的SSE较稳定并且数值较小;
bi-kmeans 4次计算出来的SSE都一样,并且计算的SSE都较小,聚类的效果也最好。
2.1.4 K-Medians 算法
使用均值的中间值来重新计算簇中心点。
优点:使用中间值,对离群值的敏感度较低。
缺点:对于较大的数据集来说,速度慢,因为在计算中值向量时,每次迭代都需要进行排序。
2.2 基于滑动窗口的方法
2.2.1 均值偏移聚类算法
均值偏移(Mean shift)聚类算法是一种基于滑动窗口(sliding-window)的算法,它试图找到密集的数据点。它还是一种基于中心的算法,它的目标是定位每一组簇的中心点,通过更新中心点的候选点来实现滑动窗口中的点的平均值。这些候选窗口在后期处理阶段被过滤,以消除几乎重复的部分,形成最后一组中心点及其对应的组。过程如下图2.1:
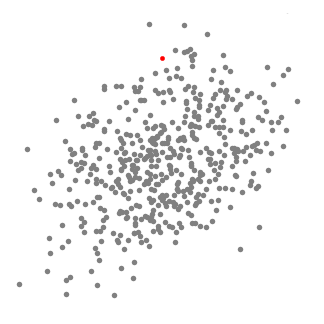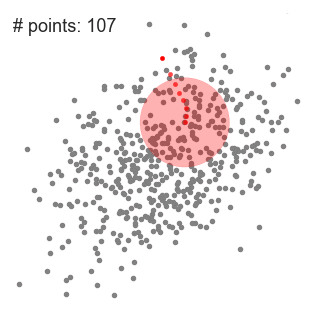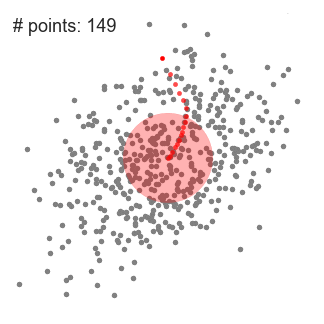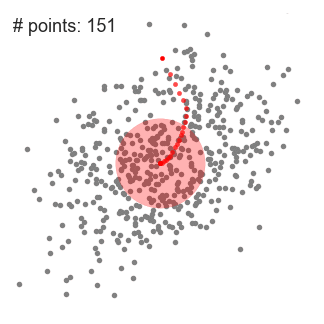
图2.1 bi-kmeans聚类结果
单滑动窗口的均值偏移聚类:
- 考虑二维空间中的一组点,如上例,从一个随机选择点 C 为中心的圆形滑窗开始,以半径 r 为内核。均值偏移是一种爬山算法(hill climbing algorithm),它需要在每个步骤中反复地将这个内核移动到一个更高的密度区域,直到收敛。
- 在每一次迭代中,滑动窗口会移向密度较高的区域,将中心点移动到窗口内的点的平均值。滑动窗口中的密度与它内部的点的数量成比例。自然地,通过移向窗口中点的平均值,它将逐渐向更高的点密度方向移动。
- 继续根据均值移动滑动窗口,直到没有方向移动可以容纳内核中的更多点,不再增加密度,也就是窗口中的点数。
- 步骤 1 到 3 的过程是用许多滑动窗口完成的,直到所有的点都位于一个窗口内。当多个滑动窗口重叠的时候,包含最多点的窗口会被保留。然后,数据点根据它们所在的滑动窗口聚类。
下图2.2为从端到端所有滑动窗口的过程演示。每个黑点代表一个滑动窗口的质心,每个灰色点都是一个数据点。

图2.2 从端到端所有滑动窗口的过程
优点:
- 与K-Means聚类相比,不需要选择聚类的数量。
- 聚类中心收敛于最大密度点,它直观地理解并适合于一种自然数据驱动。
缺点:
- 选择窗口大小/半径r是非常关键的,所以不能疏忽。
2.3 使用高斯混合模型 GMM 的期望最大化 EM 聚类
K-Means的缺点:对聚类中心的平均值的使用很简单。如下图3.1所示,图3.1左有两个以相同的平均值为中心,半径不同的圆形的聚类,因为聚类的均值非常接近,K-Means无法处理;图3.1右在聚类不是循环的情况下,使用均值作为聚类中心,K-Means也会失败。

图3.1 K-Means的两个失败案例
高斯混合模型 GMMs 比K-Means更灵活,使用高斯混合模型,假设数据点是高斯分布,有平均值和标准差两个参数来描述聚类的形状。以二维样本点为例,聚类可以采用任何形式的椭圆形(因为在x和y方向上都有标准差)。因此,每个高斯分布可归属于一个单独的聚类。
为了找到每个聚类的高斯分布的参数(平均值和标准差),使用期望最大化 EM 的优化算法。过程如图3.2 ,高斯混合模型是被拟合到聚类上的,然后继续进行期望的过程,即使用高斯混合模型实现最大化聚类。

图3.2 使用高斯混合模型来期望最大化聚类
- 首先选择聚类的数量,然后随机初始化每个聚类的高斯分布参数。通过快速查看数据,可以尝试为初始参数提供良好的猜测。在上图中可以看到,这不是必要的,因为高斯开始时的表现不好,但是很快就被优化了。
- 给定每个聚类的高斯分布,计算每个数据点属于特定聚类的概率。一个点离高斯中心越近,它就越有可能属于那个聚类。这是很直观的,因为有一个高斯分布,我们假设大部分的数据都离聚类中心很近。
- 基于这些概率,为高斯分布计算一组新的参数,这样能最大程度地利用聚类中的数据点的概率。使用数据点位置的加权和来计算新参数,权重是属于该特定聚类的数据点的概率。(如上面的图中的黄色聚类。分布在第一次迭代中是随机的,但是我们可以看到大多数的黄色点都在这个分布的右边。当我们计算一个由概率加权的和,即使在中心附近有一些点,它们中的大部分都在右边。因此,自然分布的均值更接近于这些点。可以看到,大多数点都是“从右上角到左下角”。)因此,标准差的变化是为了创造一个更符合这些点的椭圆,从而使概率的总和最大化。
- 迭代地重复步骤2和3,直到收敛,即分布不会从迭代到迭代的过程中变化很多。
优点:
- 高斯混合模型在聚类协方差方面比K-Means要灵活得多;根据标准差参数,聚类可以是任何椭圆形状,而不局限于圆形。K-Means实际上是高斯混合模型的一个特例,每个聚类在所有维度上的协方差都接近0。
- 根据高斯混合模型的使用概率,每个数据点可以有多个聚类。因此,如果一个数据点位于两个重叠的聚类的中间,通过说X%属于1类,而y%属于2类,简单地定义它的类。
2.4 基于密度的方法
k-means算法对于凸性数据具有良好的效果,能够根据距离将数据分为球状类的簇,但对于非凸形状的数据点,就无能为力了,当k-means算法对环形数据聚类时的情况如图4.1。
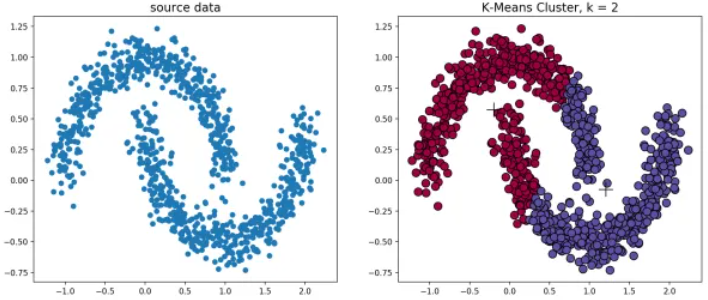
图4.1 k-means算法对环形数据聚类结果
从图4.1可以看到,kmeans聚类产生了错误的结果,这个时候就需要用到基于密度的聚类方法了,该方法需要定义两个参数 ε \varepsilon ε和 M M M,分别表示密度的邻域半径和邻域密度阈值。DBSCAN就是其中的典型。
2.4.1 DBSCAN 算法
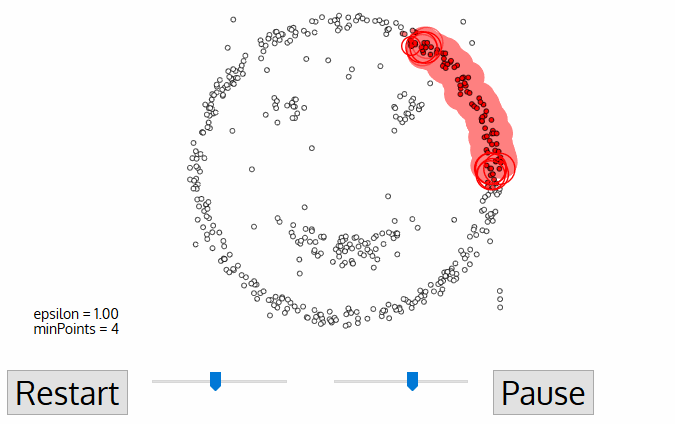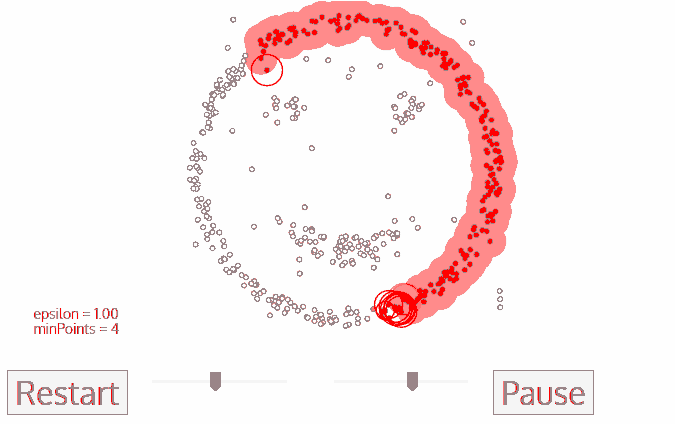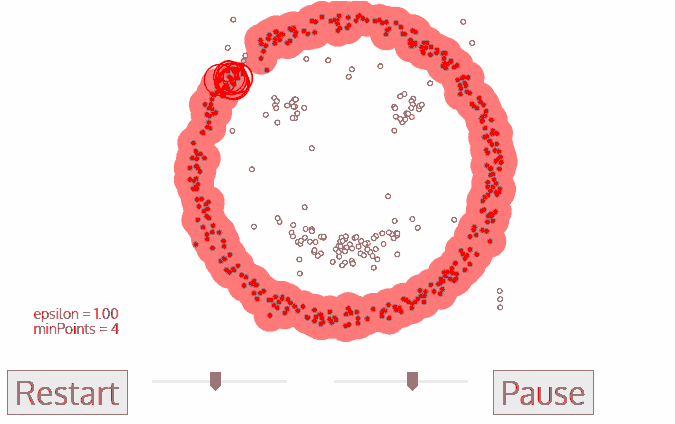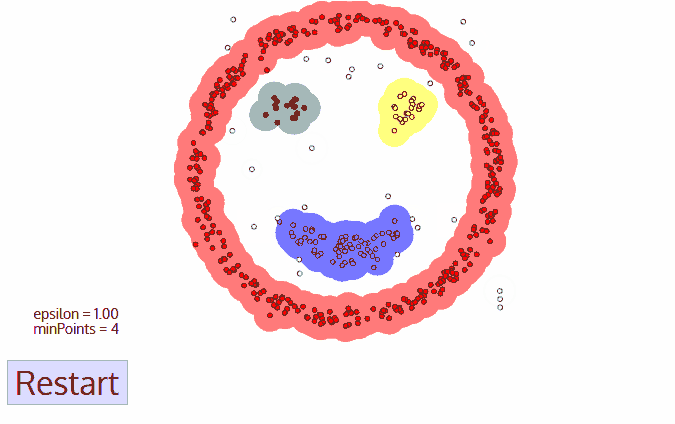
图4.2 DBSCAN 聚类过程
考虑集合 X = { x ( 1 ) , x ( 2 ) , . . . , x ( n ) } X=\left \{x^{(1)},x^{(2)},...,x^{(n)}\right \} X={ x(1),x(2),...,x(n)}, ε \varepsilon ε定义密度的邻域半径,设聚类的邻域密度阈值为 M M M,有以下定义:
- ε \varepsilon ε邻域( ε \varepsilon ε-neighborhood):
N ε ( x ) = { y ∈ X ∣ d ( x , y ) < ε } N_{\varepsilon }(x)=\left \{y\in X|d(x, y) < \varepsilon \right \} Nε(x)={ y∈X∣d(x,y)<ε} - 密度(desity) x x x的密度:
ρ ( x ) = ∣ N ε ( x ) ∣ \rho (x)=\left | N_{\varepsilon }(x)\right | ρ(x)=∣Nε(x)∣ - 核心点(core-point):
设 x ∈ X x\in X x∈X,若 ρ ( x ) ≥ M \rho (x) \geq M ρ(x)≥M,则称 x x x为 X X X的核心点,记 X X X中所有核心点构成的集合为 X c X_c Xc,记所有非核心点构成的集合为 X n c X_{nc} Xnc。 - 边界点(border-point):
若 x ∈ X n c x\in X_{nc} x∈Xnc,且 ∃ y ∈ X \exists y\in X ∃y∈X,满足 y ∈ N ε ( x ) ∩ X c y\in N_{\varepsilon }(x) \cap X_c y∈Nε(x)∩Xc
即 x x x的 ε \varepsilon ε邻域中存在核心点,则称 x x x为 X X X的边界点,记 X X X中所有的边界点构成的集合为 X b d X_{bd} Xbd。
边界点另一定义:若 x ∈ X n c x\in X_{nc} x∈Xnc,且 x x x落在某个核心点的 ε \varepsilon ε邻域内,则称 x x x为 X X X的一个边界点,一个边界点可能同时落入一个或多个核心点的 ε \varepsilon ε邻域。 - 噪声点(noise-point)
若 x x x满足
x ∈ X , x ∉ X c 且 x ∉ X b d x\in X,x \notin X_{c}且 x\notin X_{bd} x∈X,x∈/Xc且x∈/Xbd
如图4.3所示,设 M = 3 M=3 M=3,则A为核心点,B、C是边界点,而N是噪声点。

图4.3 各个定义的示例
该算法的流程如下:
- 标记所有对象为unvisited
- 当有标记对象时
1. 随机选取一个unvisited对象 p
2. 标记 p 为 visited
3. 如果 p 的 ε \varepsilon ε 邻域内至少有 M 个对象,则
1. 创建一个新的簇 C,并把 p 放入 C 中
2. 设 N 是 p 的 ε \varepsilon ε 邻域内的集合,对 N 中的每个点 p’
1. 如果点 p’ 是unvisited
1. 标记 p’ 为visited
2. 如果 p’ 的 ε \varepsilon ε 邻域至少有 M个对象,则把这些点添加到 N
3. 如果 p’ 还不是任何簇的成员,则把 p’ 添加到 C
3. 保存 C
4. 否则标记 p 为噪声
构建邻域的过程可以使用 kd-tree 进行优化,循环过程可以使用Numba、Cython、C进行优化,·DBSCAN·的源代码,使用该节一开始提到的数据集,聚类效果如图4.4:
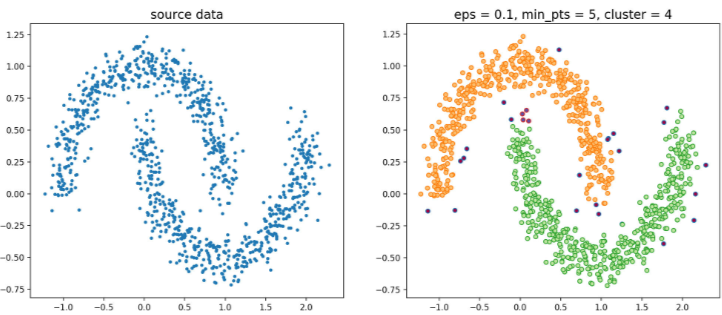
图4.4 DBSCAN算法对环形数据聚类结果
聚类的过程示意图4.5:

图4.5 聚类的过程
当设置不同的 ε \varepsilon ε 时,会产生不同的结果,如下图4.6所示:
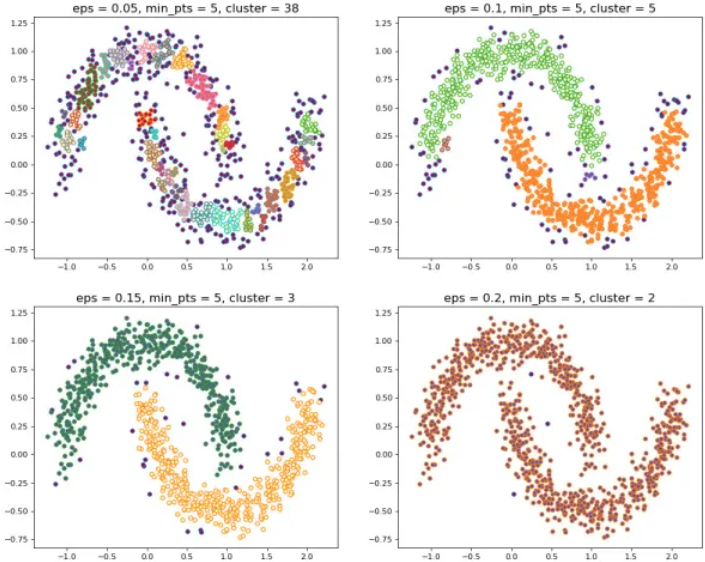
图4.6 不同的 ε
当设置不同的 M M M时,会产生不同的结果,如下图4.7所示:
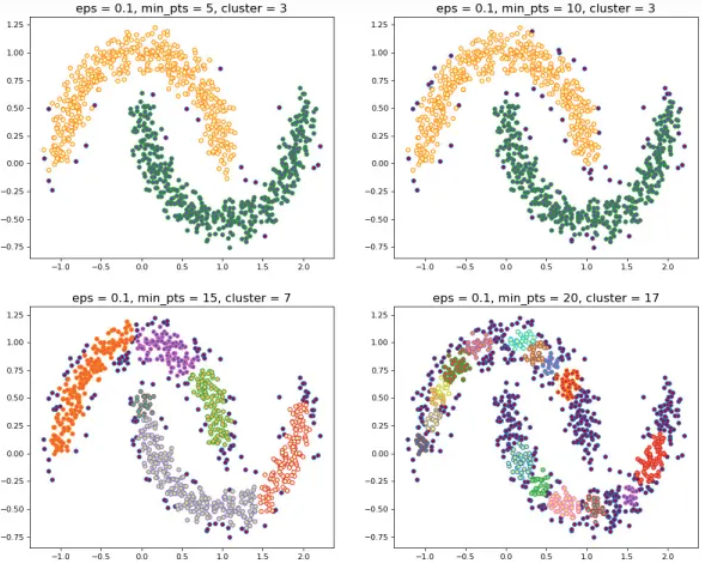
图4.7 不同的 M
优点:
- 需要提前确定 ε \varepsilon ε 和 M M M值
- 不需要提前设置聚类的个数
- 对初值选取敏感,对噪声不敏感,可以将异常值识别为噪声。但对于均值偏移聚类算法,即使数据点非常不同,它也会将它们放入一个聚类中。
- 能很好地找到任意大小和形状的聚类。
缺点:
- 对密度不均的数据聚合效果不好,因为当密度变化时,邻域半径 ε ε ε和密度阈值 M M M的设置会随着聚类的不同而变化。
- 高维数据的聚合效果不好,因为 ε ε ε难以估计。
2.4.2 OPTICS 算法
在DBSCAN算法中,使用了统一的 ε \varepsilon ε值,当数据密度不均匀的时候,如果设置了较小的 ε \varepsilon ε值,则较稀疏的 cluster 中的节点密度会小于 M M M,会被认为是边界点而不被用于进一步的扩展;如果设置了较大的 ε \varepsilon ε值,则密度较大且离的比较近的cluster容易被划分为同一个cluster,如下图4.8所示。

图4.8 设置了较小 较大的 ε
- 如果设置的 ε \varepsilon ε较大,将会获得A,B,C这3个cluster
- 如果设置的 ε \varepsilon ε较小,将会只获得C1、C2、C3这3个cluster
对于密度不均的数据选取一个合适的 ε \varepsilon ε是很困难的,对于高维数据,由于维度灾难 (Curse of dimensionality) , ε \varepsilon ε的选取将变得更加困难。
解决DBSCAN遗留下的问题:
提出一种算法,使得基于密度的聚类结构能够呈现出一种特殊的顺序,该顺序所对应的聚类结构包含了每个层级的聚类的信息,并且便于分析。
OPTICS(Ordering Points To Identify the Clustering Structure, OPTICS)实际上是DBSCAN算法的一种有效扩展,主要解决对输入参数敏感的问题。即选取有限个邻域参数 ε i ( 0 ≤ ε i ≤ ε ) \varepsilon _i( 0 \leq\varepsilon_{i} \leq \varepsilon) εi(0≤εi≤ε)进行聚类,这样就能得到不同邻域参数下的聚类结果。
在介绍·OPTICS·算法之前,再扩展几个概念。
- 核心距离(core-distance)
样本 x ∈ X x∈X x∈X,对于给定的 ε \varepsilon ε和 M M M,使得 x x x成为核心点的最小邻域半径称为 x x x的核心距离,其数学表达如下
c d ( x ) = { U N D E F I N E D , ∣ N ε ( x ) ∣ < M d ( x , N ε M ( x ) ) , ∣ N ε ( x ) ∣ ⩾ M cd(x)=\left\{\begin{matrix} UNDEFINED, \left | N_{\varepsilon }(x)\right |< M\\ d(x,N_{\varepsilon }^{M}(x)), \left | N_{\varepsilon }(x)\right | \geqslant M \end{matrix}\right. cd(x)={ UNDEFINED,∣Nε(x)∣<Md(x,NεM(x)),∣Nε(x)∣⩾M
其中, N ε i ( x ) N_{\varepsilon }^{i}(x) Nεi(x)表示在集合 N ε ( x ) N_{\varepsilon }(x) Nε(x)中与节点 x x x第 i i i近邻的节点,如 N ε 1 ( x ) N_{\varepsilon }^{1}(x) Nε1(x)表示 N ε ( x ) N_{\varepsilon }(x) Nε(x)中与 x x x最近的节点,如果 x x x为核心点,则必然会有 c d ( x ) ≤ ε cd(x) \leq\varepsilon cd(x)≤ε。 - 可达距离(reachability-distance)
设 x , y ∈ X x,y∈X x,y∈X,对于给定的参数 ε \varepsilon ε和 M M M, y y y关于 x x x的可达距离定义为:
r d ( y , x ) = { U N D E F I N E D , ∣ N ε ( x ) ∣ < M max { c d ( x ) , d ( x , y ) } , ∣ N ε ( x ) ∣ ⩾ M rd(y,x)=\left\{\begin{matrix} UNDEFINED, \left | N_{\varepsilon }(x)\right |< M\\ \max{\{cd(x),d(x,y)\}}, \left| N_{\varepsilon }(x)\right | \geqslant M \end{matrix}\right. rd(y,x)={ UNDEFINED,∣Nε(x)∣<Mmax{ cd(x),d(x,y)},∣Nε(x)∣⩾M
特别地,当 x x x为核心点时,可以按照下式来理解 r d ( x , y ) rd(x,y) rd(x,y)的含义:
r d ( x , y ) = min { η : y ∈ N η ( x ) 且 ∣ N η ( x ) ∣ ≥ M } rd(x,y)=\min\{\eta:y \in N_{\eta}(x) 且 \left|N_{\eta}(x)\right| \geq M\} rd(x,y)=min{ η:y∈Nη(x)且∣Nη(x)∣≥M}
即 r d ( x , y rd(x,y rd(x,y)表示使得" x x x为核心点"且" y y y从 x x x直接密度可达"同时成立的最小邻域半径。
可达距离的意义在于衡量 y y y所在的密度,密度越大,他从相邻节点直接密度可达的距离越小,如果聚类时想要朝着数据尽量稠密的空间进行扩张,那么可达距离最小是最佳的选择。
举例,下图4.9中假设 M = 3 M=3 M=3,半径是 ε ε ε。那么 P P P点的核心距离是 d ( 1 , P ) d(1,P) d(1,P),点2的可达距离是 d ( 1 , P ) d(1,P) d(1,P),点3的可达距离也是 d ( 1 , P ) d(1,P) d(1,P),点4的可达距离则是 d ( 4 , P ) d(4,P) d(4,P)的距离。
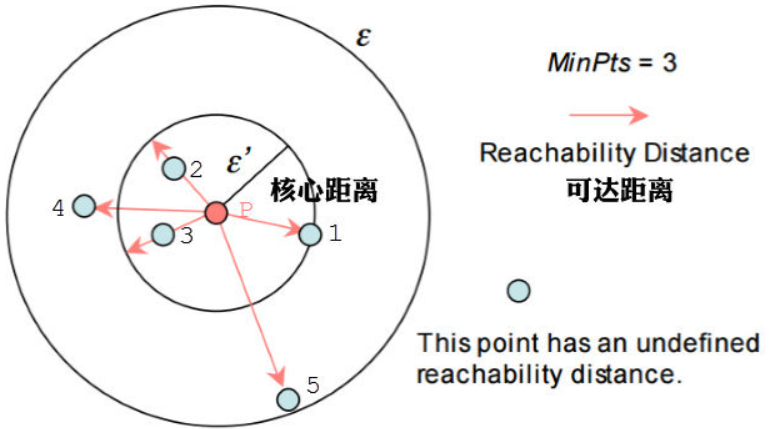
图4.9 核心距离 可达距离
OPTICS源代码,算法流程如下:
- 标记所有对象为unvisited,初始化order_ list为空
- 当有标记对象时
1. 随机选取一个unvisited对象 i i i
2. 标记 i i i为visited, 插入结果序列order_list中
3. 如果 i i i的 ε \varepsilon ε邻域内至少有 M M M个对象,则
1. 初始化seed_ list种子列表
2. 调用insert_list(), 将邻域对象中未被访问的节点按照可达距离插入队列seed_ list中
3. 当seed_ list列表不为空
1. 按照可达距离升序取出seed_list中第一个元素 j j j
2. 标记 j j j为visited, 插入结果序列order_list中
3. 如果 j j j 的 ε 邻域内至少有 M M M个对象,则
1. 调用insert _list(), 将邻域对象中未被访问的节点按照可达距离插入队列seeld_list中
算法中有一个很重要的insert_list()函数,这个函数如下:
- 对i中所有的邻域点 k k k
- 如果k:未被访问过
1. 计算rd(k,i)
2. 如果rk = UNDEFINED
1. r k = r d ( k , i ) r_k = rd(k,i) rk=rd(k,i)
2. 将节点k:按照可达距离插入seed_ list中
3. 否则
1. 如果 r d ( k , i ) < r k rd(k,i) < r_k rd(k,i)<rk
2. 更新 r k r_k rk的值,并按照可达距离重新插入seed. _ist中
OPTICS算法输出序列的过程如图4.10:

图4.10 OPTICS 算法输出序列
该算法最终获取知识是一个输出序列,该序列按照密度不同将相近密度的点聚合在一起,而不是输出该点所属的具体类别,如果要获取该点所属的类型,需要再设置一个参数 ε ′ ( ε ′ ≤ ε ) \varepsilon'(\varepsilon' \leq \varepsilon) ε′(ε′≤ε)提取出具体的类别。
举个例子,如图4.11,随机生成三组密度不均的数据,我们使用DBSCAN和OPTICS来看一下效果:
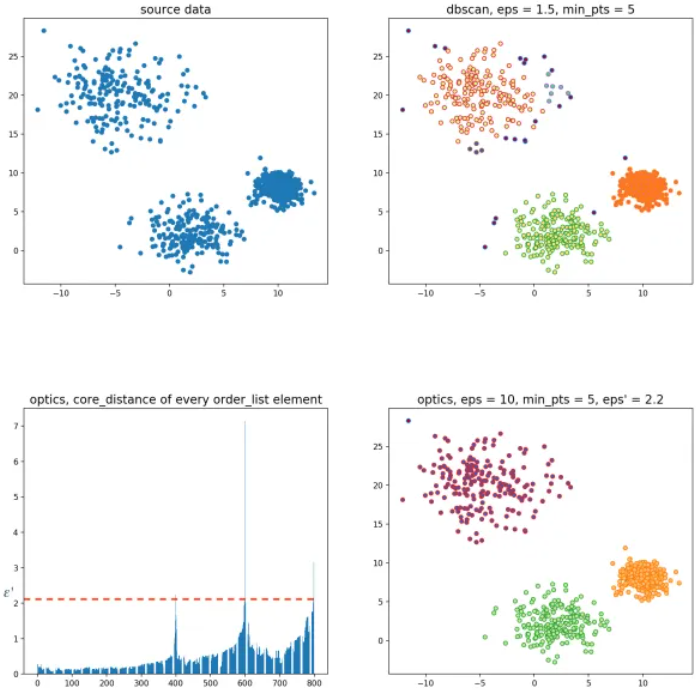
图4.11 使用DBSCAN OPTICS
可见,OPTICS第一步生成的输出序列较好的保留了各个不同密度的簇的特征,根据输出序列的可达距离图,再设定一个合理的ε′\varepsilon’,便可以获得较好的聚类效果。
2.5 层次化聚类方法
前面介绍的几种算法确实可以在较小的复杂度内获取较好的结果,但是这几种算法却存在一个链式效应的现象,比如:A与B相似,B与C相似,那么在聚类的时候便会将A、B、C聚合到一起,但是如果A与C不相似,就会造成聚类误差,严重的时候这个误差可以一直传递下去,如图5.1。为了降低链式效应,这时候层次聚类就该发挥作用了。
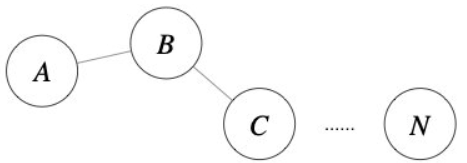
图5.1 链式效应
层次聚类算法 (hierarchical clustering) 将数据集划分为一层一层的 clusters,后面一层生成的 clusters 基于前面一层的结果。层次聚类算法,如图5.2一般分为两类:
- Agglomerative 层次聚类:又称自底向上(bottom-up)的层次聚类,每一个对象最开始都是一个
cluster,每次按一定的准则将最相近的两个cluster合并生成一个新的cluster,如此往复,直至最终所有的对象都属于一个cluster。这里主要关注此类算法。 - Divisive 层次聚类: 又称自顶向下(top-down)的层次聚类,最开始所有的对象均属于一个
cluster,每次按一定的准则将某个cluster划分为多个cluster,如此往复,直至每个对象均是一个cluster。

图5.2 层次聚类
另外,需指出的是,层次聚类算法是一种贪心算法(greedy algorithm),因其每一次合并或划分都是基于某种局部最优的选择。
2.3.1 Agglomerative 算法
给定数据集 X = { x ( 1 ) , x ( 2 ) , . . . , x ( n ) } X=\left \{x^{(1)},x^{(2)},...,x^{(n)}\right \} X={ x(1),x(2),...,x(n)},Agglomerative层次聚类最简单的实现方法分为以下几步:
- 初始时每个样本为一个
cluster,计算距离矩阵 D D D,其中元素 D i j D_{ij} Dij为样本点 D i D_i Di和 D j D_j Dj之间的距离;- 遍历距离矩阵 D D D,找出其中的最小距离(对角线. 上的除外),并由此得到拥有最小距离的两个
cluster
的编号,将这两个cluster合并为一个新的cluster并依据cluster距离度量方法更新距离矩阵 D D D (删
除这两个cluster对应的行和列,并把由新cluster所算出来的距离向量插入 D D D中),存储本次合并的
相关信息;- 重复2的过程,直至最终只剩下一个
cluster。
Agglomerative算法源代码,可以看到,该 算法的时间复杂度为 O ( n 3 ) O(n^3) O(n3)(由于每次合并两个 cluster 时都要遍历大小为 O ( n 2 ) O(n^2) O(n2)的距离矩阵来搜索最小距离,而这样的操作需要进行 n − 1 n−1 n−1 次),空间复杂度为 O ( n 2 ) O(n^2) O(n2) (由于要存储距离矩阵)。

图5.3
图5.3中分别使用了层次聚类中4个不同的cluster度量方法,可以看到,使用single-link确实会造成一定的链式效应,而使用complete-link则完全不会产生这种现象,使用average-link和ward-link则介于两者之间。
优点:
- 不指定聚类的数量,可以选择较好的聚类
- 该算法对距离度量的选择不敏感,都很好,而其他聚类算法,距离度量的选择是至关重要的。
- 当底层数据具有层次结构时,可以恢复层次结构;其他的聚类算法无法做到。
缺点:
- 低效率,时间复杂度为 O ( n 3 ) O(n^3) O(n3),与K-Means和高斯混合模型的线性复杂度不同。
2.4 聚类方法比较
| 算法类型 | 适合的数据类型 | 抗噪点性能 | 聚类形状 | 算法效率 |
|---|---|---|---|---|
| kmeans | 混合型 | 较差 | 球形 | 很高 |
| k-means++ | 混合型 | 一般 | 球形 | 较高 |
| bi-kmeans | 混合型 | 一般 | 球形 | 较高 |
| DBSCAN | 数值型 | 较好 | 任意形状 | 一般 |
| OPTICS | 数值型 | 较好 | 任意形状 | 一般 |
| Agglomerative | 混合型 | 较好 | 任意形状 | 较差 |