目录
一、数据与数据元素
数据是客观事物的符号表示,可以说是信息的载体,它是所有能被输入到计算机中,并被计算机程序识别和处理的符号集合。
数据由数据元素组成,即数据元素是数据的基本单位,而数据元素又由若干个数据项组成,所以,数据项是组成数据元素的最基本、不可分割的最小单位。
另外,具有相同性质的数据元素集合称为数据对象,它是数据的一个子集。
二、数据类型和抽象数据类型
数据类型是高级程序语言中的一个基本概念,它是值的集合和操作的集合。
- 抽象数据类型(ADT)是指一个数学模型及定义在该模型上的一组操作,它包括三个部分,
数据对象、数据对象上关系的集合、对数据对象的基本操作的集合,简单可概括为数据对象、数据关系和基本操作。可以用抽象数据类型定义一个完整的数据结构,抽象数据类型的定义取决于它的一组逻辑特性,另外,数据结构的抽象操作的定义与具体实现无关。
三、数据结构的定义
探究一种数据结构的方法分为三个步骤:
1、首先,要定义数据元素之间的关系,即定义逻辑上的结构;【数据如何组织】
2、由于需要存储这些数据元素,所以需要确定某种存储结构,实现数据结构以及对数据结构的基本运算,即定义存储结构;【数据如何存储】
3、针对实现的需求,需要对这种逻辑结构进行怎样的运算,即数据的运算。【数据的运算如何实现】
例如,举一个现实中的例子,公司员工的信息表,其中每个员工的信息就是一个数据元素;由于每个员工都有员工编号,所以其编号的前后员工也是存在的,即有前驱和后驱(线性结构),另外,公司中还存在一个经理来领导某一个部门的所有员工(非线性结构),从而对应逻辑结构;这些信息都某种存储方式被存储在计算机中,其中存储的方式有很多,即对应存储结构;当公司有新的员工入职(增加)、老员工离职(删除)、员工信息修改(修改)、查找某个员工的信息(查找)等情况,即对应数据的运算。
- 数据结构,指这些数据元素中
存在一种或多种特定关系的数据元素的集合,简单点说,数据结构就是带结构的数据元素集合,它包括逻辑结构、存储结构和数据的运算共三个方面,即数据结构的三个方面缺一不可,另外,存储结构也可称为物理结构。
例如,一维数组中存在一对一的关系,它存储一组具有相同数据类型的数据元素,通过数组下标来访问,每个数据元素在一维数组中都对应有一个特定的位置,如下:
| 数组下标 | 0 | 1 | 2 | … |
|---|---|---|---|---|
| 数据元素 | A | B | C | … |
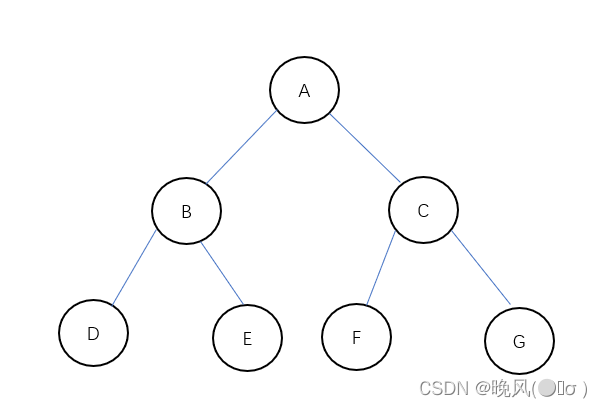
二叉树是一对二,即一对多的关系,其中每个结点可以算作一个根结点,每个根结点的后继结点最多只能有两个,从而对应左子树(左孩子)和右子树(右孩子),而没有后继结点的则称为叶子结点,如下图:
(一)逻辑结构
逻辑结构指的是数据元素之间在逻辑上的关系,可分为线性结构和非线性结构,如下:
例如,顺序表、单链表、哈希表既描述逻辑结构,又描述存储结构和数据的运算,而有序表只是一种逻辑结构,它只表示数据元素之间的逻辑关系是有序的。
1、线性结构是一对一的关系,例如有线性表、栈、队列、串、一维数组等。
2、非线性结构是一对多或多对多的关系,例如有二维数组(多维数组)、广义表、树(二叉树)、图等。
通常指的线性结构即数据元素之间存在一对一的关系,树形结构(树、二叉树等)即数据元素之间存在一对多的关系,图形结构(无向图、有向图等)即数据元素之间存在多对多的关系,而集合中的数据元素之间无关系。
(二)存储结构(物理结构)
数据的逻辑结构在计算机中的表示称为存储结构,也称为物理结构,它包括数据元素的表示和关系的表示,根据其存储特点可以分为四种存储结构,即顺序存储结构、链式存储结构、索引存储结构和散列存储结构。
以上四种存储结构,由于每种存储结构都有其优缺点,不能直接地说哪种存储结构最优,只能说在针对某种数据结构中需要选择不同的存储结构时,应该选择符合其特点的数据结构才是最优的。
1、顺序存储结构
顺序存储由存储单元的邻接关系体现,即把逻辑上相邻的元素存储在物理位置上也相邻的存储单元里,其中数据是连续的。
- 该存储结构的优点是可以实现
随机存取,每个元素占用最少的存储空间,而缺点是由于只能使用相邻的一整块存储单元,从而会产生较多的外部碎片。
以线性表为例,通过顺序存储的线性表称为顺序表,它是将线性表中所有元素按照其逻辑顺序,依次存储到指定存储位置开始的一块连续的存储空间里;而通过链式存储的链表中,每个结点不仅包含该元素的信息,还包含元素之间的逻辑关系的信息。
2、链式存储结构
链式存储不要求逻辑上相邻的元素物理位置上也相邻,通过指示元素存储地址的指针来体现元素之间的逻辑关系,其数据是可离散的。
- 该存储结构的优点是
充分利用了所有的存储单元,不会造成碎片现象,而缺点是由于通过指针来表示逻辑关系,所以指针也要存储,从而占用额外的存储空间,即链式存储的存储结构所占存储空间分两部分,一部分存放结点的值,另一部分存放表示结点间关系的指针(结点内的存储单元要求连续,而不同结点的存储空间可以不连续),例如,顺序表的存储密度=1,而链表的存储密度<1,是由于结点中含有指针域。另外,链式结构只能顺序存取,不能随机存储。
以线性表为例,单链表是通过链式存储的,其每个结点除了存放数据元素之外,还存储指向下一个结点的指针;而顺序表是顺序存储的,其每个结点只存放数据元素。顺序存储结构可以随机存取、顺序存取,而链式存储结构只能顺序存取,顺序存储结构不仅可用于存储线性结构,还能用于树、图等非线性结构。
针对线性表,以上两种存储结构在线性表中的实际选择:
在一般情况下,若需对表进行频繁的插入、删除操作,此时适合选链式存储,因为顺序表平均需要移动近一半的元素且耗费时间(其插入和删除算法的平均时间复杂度为O(n)),而链表在插入和删除操作时不需要移动元素,只需修改指针;当若表的总数基本稳定,且很少进行插入和删除操作,则顺序表相较于链表可以充分发挥其存取速度块、存储利用率高的优点。
3、索引存储结构
索引存储在存储数据元素的同时还需要建立附加的索引表,其中的索引项的形式为关键字和地址,其数据是可离散的。
- 该存储结构的优点是在查找数据元素时
很快、容易找到,而缺点是由于附加了索引表,从而占用了额外的存储空间,同时,若需要增加和修改数据时,需修改索引表,会花费较多时间。
例如,查找算法中树型查找的B树、B+树的应用到了索引存储结构。
4、散列存储结构
散列存储是根据数据元素的关键字直接计算其存储地址,也称为哈希存储(Hash),其数据是可离散的。
- 该存储结构的优点是在对数据元素进行增加、删除结点操作时
很快,而缺点是若定义的哈希函数不能完全贴合情况,则会发生元素存储单元的冲突,而减少冲突从而会花费时间和一定的空间上的开销。
例如,哈希表即为一种基于散列存储结构的查找表。
(三)数据的运算
前面说过,针对实现的需求,需要对这种逻辑结构进行怎样的运算,即数据的运算,它是数据定义的一组操作,而运算的实现是通过存储结构的。【定义针对逻辑结构、实现针对存储结构】
例如,顺序表的增删改查,即为数据的运算,对应的是顺序表插入操作、删除操作、修改元素和查找元素。
四、算法的基本概念
(一)算法的特性
算法具有以下五个特性:
(1)输入
(2)输出
(3)确定性
(4)可行性
(5)有穷性
一个算法可以没有输入,但是必须有输出。
(二)算法与算法分析
程序=算法+数据结构,设计一个具有正确性、可读性、健壮性、高效率(执行速度快,时间复杂度低)和低存储(不费内存,空间复杂度低)的算法,再加上合适的数据结构,从而构成一个良好的程序。算法分析的目的是分析算法的效率以求改进。
(多选)设计一个″好″的算法应考虑达到的目标是()。
A、可行性
B、健壮性
C、无二义性
D、可读性好的
解析:(B、D)
五、算法设计步骤
(1)算法描述
(2)数学模型选择
(3)算法的详细设计
(4)算法的程序实现和测试
(5)算法分析
六、算法的效率分析
(一)时间复杂度
1、时间复杂度的定义
时间复杂度是对算法运行时间的数量级,有两种度量方法,分别是事前分析估算法和事后统计法。通常,对一个算法的时间复杂度考察三个方面,即最好情况、平均情况和最坏情况,从而对应最好时间复杂度、平均时间复杂度和最坏时间复杂度,其中平均时间复杂度是指所有输入在等概率的情况下,该算法的期望运行时间,例如直接插入排序:
| 排序算法 | 空间复杂度 | 平均时间复杂度 | 最好时间复杂度 | 最坏时间复杂度 |
|---|---|---|---|---|
| 直接插入排序 | O(1) | O(n2) | O(n) | O(n2) |
最好情况下,即元素都有序,此时只需比较元素而不需移动元素,最好时间复杂度为O(n),而最坏情况下,即排好的序列刚好与初始序列相反,呈逆序排列,则此时比较次数和移动次数都到达最大值,最坏时间复杂度为O(n2),而考虑平均情况下,总的比较次数和移动次数约为n2/4,故直接插入排序的平均时间复杂度为O(n2)。
2、时间复杂度的规则
(1)常数规则
C为一个正常数,O[Cf(n)]=O[f(n)]。
(2)加法规则
O[f(n)]+O[g(n)]=O[max(f(n),g(n)]。
(3)乘法规则
O[f(n)]×O[g(n)]=O[(f(n)×g(n)],例如下列代码:
count=0; //执行一次
for(k=1;k<=n;k*=2) //执行log2n次,变量k成倍数增加,呈现出log对数关系
for(j=1;j<=n;j++) //循环n次
count++;
第一行代码执行一次,根据加法规则,该程序的运行时间由for循环决定,假设最外层m次循环结束,则有2m+k=n,可得:m=log2n,所以执行执行log2n次,另外,内层for循环n次,根据乘法规则,所以该程序段的时间复杂度为O(n)=n×log2n=nlog2n。【变量k成倍数增加,呈现出log对数关系】
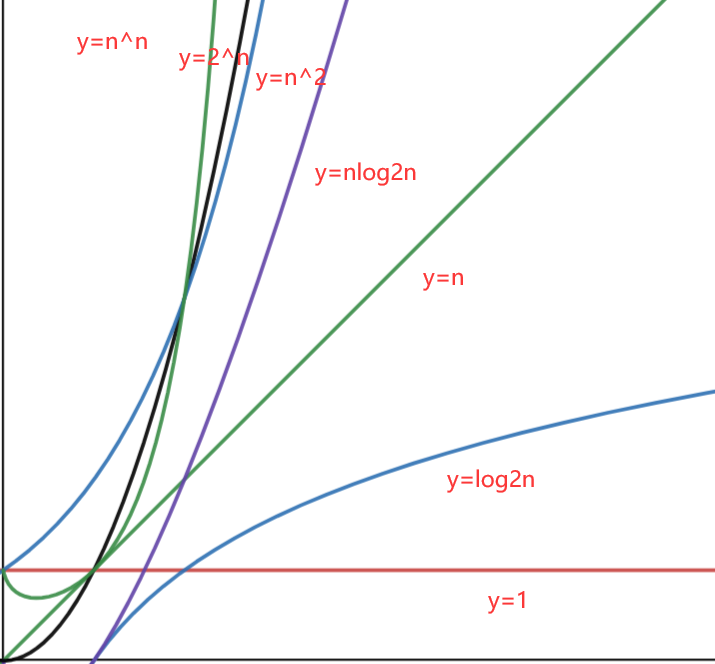
3、常见的时间复杂度的大小比较
时间复杂度为O(1) 常数阶算法的效率最高,而像O(2n) 、 O(n!) 、 O(nn)这类的算法的效率最低。
O(1) < O(log2n) < O(n) < O(nlog2n) < O(n2) < O(n3) < O(2n) < O(n!) < O(nn)
根据其图像,如下:
(二)空间复杂度
空间复杂度是指定义该算法所需要耗费的存储空间,根据其规模函数f(n),可记为O[f(n)],若算法需要的存储空间是常量,则其空间复杂度为O(1)。例如,由于快速排序代码中的递归进行需要栈来辅助,所以其需要的空间较大。其空间复杂度与递归层数(栈的深度)有关,为O(递归层数):
若将n个要排序的元素组成一个二叉树, 这个二叉树的层数就是递归调用的层数(栈的深度), 由于在n个结点的二叉树中,其最小高度=⌊ log2n⌋ (以2为底n的对数然后再向上取整,取比自己大的最小整数), 其最大高度=n。
所以,可知最好情况下,即最小高度,为⌊ log2n ⌋,最好空间复杂度为O(log2n);而最坏情况下,即最大高度,为n层,最坏空间复杂度为O(n);故平均情况下,为O(log2n)。