收藏关注不迷路
文章目录
前言
摘要:随着网络科技技术的快速增长,网络数据已经成为一种极其重要的资源。如今的一个研究热点是如何快速和有效率地寻找、提取、分析数据。对于这些方法,运用Python的Scrapy框架可以设计出网络爬虫,对网络数据进行提取分析。先分析网站源代码,之后设计出相应的表达式来提取需要用到的数据,提取结束之后将数据保存进数据库里。
本课题是一个基于scrapy分布式爬虫针对腾讯招聘网站数据的抓取系统,为数据进一步操作做数据支持。设计系统使用Python的Scrapy框架,根据网页分析得到json数据包,然后使用json.load()对下载的网页数据转化为python数据再提取,依靠Redis数据库实现分布式的功能,将数据存储进mysql数据库里,设计以及完成了针对腾讯招聘职位信息的分布式网络爬虫。
关键词:爬虫,scrapy框架,腾讯招聘
一、功能介绍
本项目主要抓取腾讯招聘网站里有价值的数据,利用Scapy框架爬取腾讯招聘官方网站主页上刊登的招聘信息。例如,其中网页链接、职位名称、职位职责、职位职责、职位利用现有技术在项目中免除注册,实现了多个目标,如要求、地点和发布时间等。同时对爬取得的数据进行初步筛选,除去多余的信息,除了可以节省当地空间外,数据科学家对数据进行两次清洗、精制,从而得到更有价值的信息。本项目对爬虫类的作用机构和设计模式进行了优化。同时采用了适当的设计模式,可以及时将内存数据导入数据库,大幅减少了内存资源的占用。
二、开发环境
开发语言:Python, scrapy框架
软件版本:python3.7/python3.8
数据库工具:Navicat11
开发软件:PyCharm/vs code
————————————————
三、程序流程设计
网络爬虫的爬取对象
本文实现的网络爬虫是爬取腾讯招聘网站招聘信息,爬取招聘网站的的一级页面,里面包含职位名称、职位类别以及工作地点等,之后再通过分析将每个职位的二级页面爬取下来,之后再爬取二级页面数据,包含职位责任和职位要求。
网络爬虫系统功能架构
分布式爬虫抓取系统,如图3-1所示,主要包含以下功能:

图3-1 分布式爬虫抓取系统架构图
(1)爬虫:爬取策略的设计、提取数据设计、增量爬取、请求去重
(2)中间件:爬虫防屏蔽中间件
(3)数据存储:抓取字段设计、数据存储
本文将腾讯招聘网站为主题的网络爬虫划为爬虫模块、中间件模块、数据存储模块3个部分。其中爬虫模块用来分析提取url地址,实施招聘主题信息网页的抓取,在满足爬取规则的范围内抓取符合招聘主题信息的网页数据;中间件模块主要负责添加user-agent请求头信息模拟浏览器登录,实现爬虫防屏蔽功能;数据存储模块主要将抓取的网页数据存入到数据库中。
四、系统效果图
3.4 腾讯招聘网页分析
3.4.1 判断网页的静/动态加载
首先进入腾讯招聘网站(https://careers.tencent.com/),我们可以看到如图3-3所示的腾讯招聘网站主页,点击“查看工作岗位”即可得到此招聘网站的大量信息。
图3-3. 腾讯招聘网站主页
单击点开之后便是招聘网站的分页,如图3-4所示,这时候可以依据不同的地区选择想要了解的职位信息。以中国的四个一线城市(北京、上海、广州、深圳)为例,主要分析这四大地区的网页地址。
图3-4. 腾讯招聘网站分页
判断网页静/动态加载,主要依据是查看网页源代码中有没有具体数据,有数据则为静态加载,无数据则为动态加载。静态加载的数据主要是html数据,提取数据可以使用正则表达式或xpath方法。动态加载则需要利用控制台并根据页面的动作来抓取网络数据包,即json数据包的url地址。
以腾讯招聘网站为例,由于网页源代码中没有具体数据,则为Ajax动态加载,根据控制台和页面刷新可以在XHR上面得到三个异步加载的数据包,在Query文件的Preview中发现了需要爬取的数据,如图3-5所示。
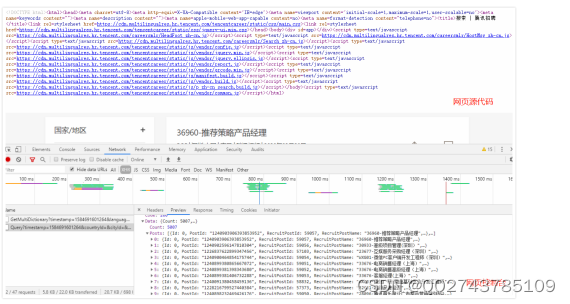
图3-5.招聘网站网页信息
3.4.2 分析一级网页获取相应数据
在XHR得到json数据包,此时需要在Headers上面查找有用的信息。如图3-6所示,需要提取到的url地址便是图中RequestURL。
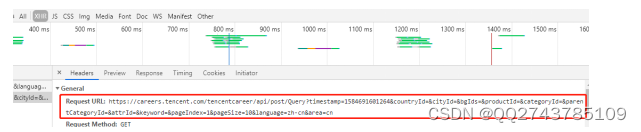
图3-6. 一级页面Headers信息
RequestURL(一级页面):
https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1584696974713&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex=1&pageSize=10&language=zh-cn&area=cn
然而此url地址比较复杂,所以需要分析每个参数。在Headers底端的Query String Parameters(查询参数)栏便有着这个网页地址的所有参数。在获取到北京、上海、广州、深圳以及不分地区的招聘网页地址后,分别得到它们的参数区别,如图3-7所示。
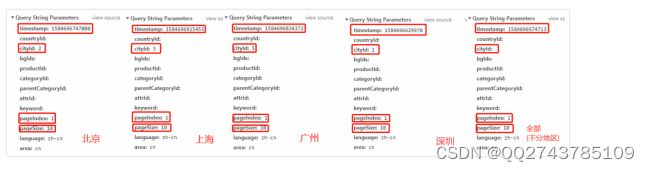
图3-7. 北京、上海、广州、深圳以及不分地区的招聘网页地址参数
在这些参数中,可分析得到,如表3-1所示。
表3-1 一级页面各参数所代表的含义

由于删去timestamp这个参数后依然可以得到json数据包,所以重要的参数分别为cityId、pageIndex、pageSize。可得到一级页面one_url:
https://careers.tencent.com/tencentcareer/api/post/Query?&countryId=&cityId={}&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex={}&pageSize=10&language=zh-cn&area=cn
最后再运用format方法即可将字符串分别带入,得到一个完整的url。代入参数后打开此链接,所得到的信息便是我们需要的json数据包,里面包含所有招聘职业的职业名称、职业类别和工作地点等大量数据,如图3-8所示。

图3-8. 一级页面Json数据包
在这个json数据包中,我们可以分析得到想要的数据,如表3-2所示。
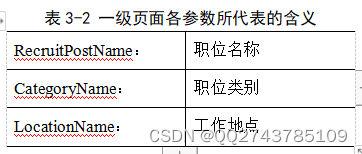
根据图3-8展示的json数据包,我们可以知道这些数据是需要根据字典的方式来进行提取,首先由一个大字典含有的‘Data’键来对应值,这个值为所需要提取的第二个字典,根据第二个字典的键‘Posts’来获取数据。‘Posts’对应的值为一个列表,在列表中提取字典,所以我们可以根据以上信息,运用for循环来编写提取数据的代码:
for job in html['Data']['Posts']:
#职位名称 = job['RecruitPostName']
#职位列别 = job['CategoryName']
#工作地点 = job['LocationName']
在这个数据包中没有我们想要的职位职责和职位要求,所以就需要分析二级网网页来获取。
结论
在这个网络技术发达,数据充沛的时代,如何获取网络数据是一份很重要的工作。相关研究人员提出:网络上百分之六十的流量均为网络爬虫爬取的[11]。爬虫作为获取数据的重要手段之一,在各种网站数据中得到了广泛的应用。本文主要从网络爬虫、Python语言与Scrapy框架几个方面进行阐述,简单介绍了腾讯招聘信息主题网络爬虫的工作流程、开发与实现。
相较于一般的爬虫项目,招聘网络爬虫有明显的精确性特征,可以精准地搜索与主题相关的网页信息,增强了网络搜索的实效性。但本文的不足之处是只列举了一些简单的爬虫技术和反爬虫方法,光是这些技术还不足以提升到爬取更多复杂的数据。在今后的研究工作中,会继续改进本项目的设计,完善有关功能,提升爬取数据的效率,更好地为学生就业工作提供更多的帮助。