ST-MGAT: Spatial-Temporal Multi-Head Graph Attention Networks for Traffic Forecasting
摘要:
图神经网络(gnn)因其对图的表示学习能力而受到越来越多的关注。交通预测是一种典型的图表示学习任务,但难以对交通中复杂的时空关系进行建模。传统的谱方法是基于特征分解得到滤波器,而特征分解依赖于图的拉普拉斯矩阵。然而,这些方法在图卷积神经网络上有昂贵的矩阵运算,不足以解决空间依赖性问题。本文提出了一种新型的图神经网络——时空多头图注意网络(ST-MGAT)来处理交通预测问题。我们直接在图上建立卷积。我们考虑邻域节点的特征和边缘的权重来生成新的节点表示。更具体地说,有两个主要模块:i)捕获动态时间相关性的时间卷积块;ii)绘制关注网络图,捕捉节点之间的动态空间关系。实验结果表明,我们的模型在短期、中期和长期公路交通预测方面比目前最先进的方法提高了13%。
图卷积网络:
空间域方法:空间方法从空间上考虑图的结构,即目标节点与其他节点之间的几何关系。挑战在于生成节点的新特征,这是通过收集和聚合相邻邻居的特征来实现的。而在本文中,我们采用了多头图注意网络,这是图卷积网络的空间域方法。我们没有使用编码器解码器或谱域方法,而是直接在图上使用注意机制构造卷积。
时空模型:
一般来说,时空模型可以分为卷积神经网络(CNN)和递归神经网络(RNN)两种方法。然而,基于rnn的方法面临着对长序列无效和梯度可能爆炸的挑战。我们采用带有门机制的扩展卷积结构来模拟交通数据的时间关系。
图卷积中的注意力机制:
基于注意力的图卷积的主要思想是通过聚集具有边缘信息的节点来生成新的节点表示。其中注意系数是图中每个节点相对于其邻居的相互重要性。在本文中,我们直接对图进行卷积,并通过注意机制使网络集中在有价值的信息上。
问题定义:
我们将交通网络视为一个图,任务是预测节点在接下来的几个时间步长的特征。我们把一个双向车道抽象成两个车道。我们将车道作为图中的边缘,将道路检测器放在车道上作为图上的点,交通状况的度量,如速度、流量和占用率,也被选择作为图中节点的特征。可以合理地将网络定义为无向图,G = (V, E, A), V为节点的有限集合,E为边的集合。邻接矩阵记为![]() 。需要强调的是,这里提到的图是一个无向图,本文的目的是预测未来某一点图上所有节点的特征。图上的节点是从道路上的检测器中选择的。此外,检测器生成的数据是节点的特征。需要强调的是,X不是一个节点的单个信号,而是一个具有整个节点的图信号。交通流量预测是使用历史测量(例如,速度或流量或占用)来预测下一个S时间片的交通流量。输入
。需要强调的是,这里提到的图是一个无向图,本文的目的是预测未来某一点图上所有节点的特征。图上的节点是从道路上的检测器中选择的。此外,检测器生成的数据是节点的特征。需要强调的是,X不是一个节点的单个信号,而是一个具有整个节点的图信号。交通流量预测是使用历史测量(例如,速度或流量或占用)来预测下一个S时间片的交通流量。输入![]() ,输出
,输出![]() ,其中N为观测站数据,F为各节点的特征,T为输入的时间步长,P为输出的时间步长。
,其中N为观测站数据,F为各节点的特征,T为输入的时间步长,P为输出的时间步长。![]() 表示时刻t节点的向量。预测接下来P个时间步长的交通速度
表示时刻t节点的向量。预测接下来P个时间步长的交通速度![]() ,其中考虑图上的所有节点和历史序列X。
,其中考虑图上的所有节点和历史序列X。
方法:
在本节中,我们将介绍框架的两个主要部分。空间层由图形注意网络(GAT)构建,该网络通过聚集具有注意系数的节点特征来生成新的节点表示。时间层由带有门机制的扩展卷积结构构成,该结构捕获时间特征并防止耗时。这些层被堆叠以提高预测的准确性,同时通过对层应用规范化来防止过拟合。最后,该模型通过附加一个完全连接层,在接下来的t个时间步中产生n个节点的输出。然后,我们将概述我们方法的框架。
框架:
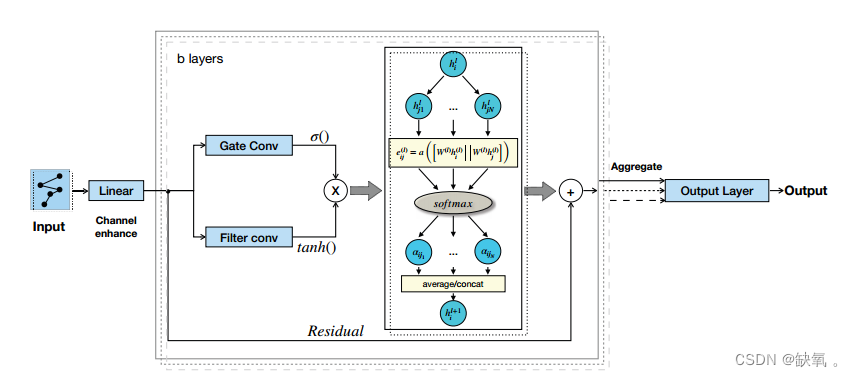
图网络的框架如图所示。一般来说,我们的模型由一个带有门机制的扩展卷积和一个基于空间的图注意卷积块组成,然后是一个用于输出的完整连接层。
输入数据为X∈RN×T ×F,其中N为节点数,T为时间步长,F为每个节点的特征。时间层的准备工作是通过二维卷积实现输入数据的特征增广。两个相同的展开卷积层接受经过特征增强的数据,其中展开核的大小分别为1、2和4。Hadamard积在两个并行卷积层(门控单元)的元素上应用。随后,将两层图注意卷积(GAT)进行叠加处理时序层的结果。同时,设置残差网络层,将未处理的数据与经过图卷积处理的数据融合。结构为一层,如上所述,多层堆叠。需要强调的是,图注意卷积层的输入为特征F∈RN×D,其中N为节点数,D为输入特征的大小。
输出为![]() ,其中Dout为特征的新大小。而门控层的输出为
,其中Dout为特征的新大小。而门控层的输出为![]() ,其中T为时间步长。本文将三维数据Xgated转换为二维数据,其中
,其中T为时间步长。本文将三维数据Xgated转换为二维数据,其中![]() 。该方法将交通数据的时间信息融合到节点的特征中。
。该方法将交通数据的时间信息融合到节点的特征中。
简而言之,时间层由一个门控时间卷积块组成,该块捕获时间特征并防止耗时。空间层由图形关注网络构建,该网络聚集具有关注系数的节点特征以生成新的节点表示。这些层被堆叠以提高预测的准确性,同时通过对层应用规范化来防止过拟合。最后,该模型通过附加一个完全连接层,在接下来的t个时间步中产生n个节点的输出。

ST-MGAT架构。输入为X∈RN×T ×F,其中N为节点数,T为时间步长,F为每个节点的特征。输出为Yout∈RN×T,表示N个节点在t个时间步长的预测速度。处理输入数据的线性方法是提高原始数据特征的维数。每个通道采用若干个卷积核为1 × 1的二维卷积。滤波块采用二维卷积。门块、残差块和聚合块采用一维卷积。我们的模型有b层,每层堆叠两个图卷积块。
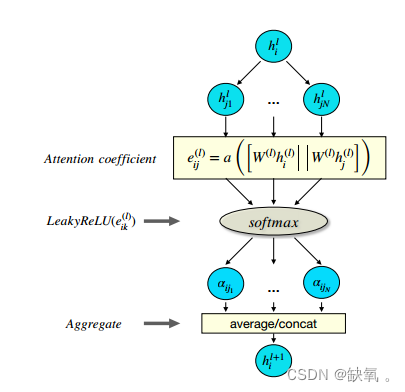
图注意层:![]() ,其中
,其中![]() 表示节点i的特征,
表示节点i的特征,![]() 表示隐藏特征的更新。N为节点数,F为特征数。
表示隐藏特征的更新。N为节点数,F为特征数。
图卷积:
图注意网络提出了一种利用注意机制对相邻节点特征进行加权求和的方法。特征节点的权重完全依赖于节点的特征,与图的结构无关。该方法克服了基于谱图卷积网络的瓶颈,易于实现对不同邻域分配不同的学习权值。
基于注意力的图卷积网络(GAT)与基于频谱的图卷积网络(GCN)的主要区别在于如何收集和总结距离为一跳的相邻节点的特征表示。在一定程度上,GAT会更强,因为顶点特征之间的相关性会更好地融入到模型中。最基本的优点是计算是在每个节点的基础上完成的。每个操作都需要循环遍历图上的所有顶点来聚合节点的特征。逐顶点运算意味着消除了拉普拉斯矩阵的束缚。与其他注意机制一样,GAT的计算分为两个步骤:计算注意系数和加权特征的聚合。
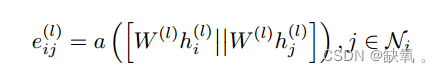
从公式中可以看出,共享参数W的线性映射将维度扩展到顶点特征,这是特征增强中常用的特征。该方法将顶点的变换特征连接起来,并将高维特征映射为实数eij,并带有a(∗)。该函数通过单层前馈神经网络实现。通过可学习参数W和映射函数a(∗)来学习顶点i和j之间的相关性。
相关系数归一化:
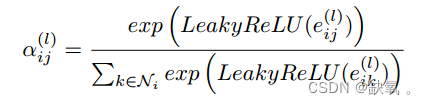
节点接收边的注意力得分通过softmax进行归一化,并使用上述相关系数。根据计算出的关注系数对特征进行加权和聚合,其中![]() 是GAT对每个顶点i进行融合后的新特征输出,σ(∗)是激活函数。
是GAT对每个顶点i进行融合后的新特征输出,σ(∗)是激活函数。

与卷积神经网络中的多核一样,采用多头注意机制来增强模型的能力和稳定训练过程。每个注意力头都有自己的参数。K是注意正面的个数。h是GAT的新特征,它融合了每个顶点的邻域信息,是激活函数。我们建议对中间层使用连接,对最后一层使用平均。
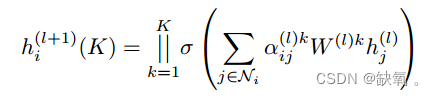
GAT中重要的学习参数是W和a(*)。由于上述逐顶点计算方法,这两个参数只与顶点特征有关,与图的结构无关。因此,在测试任务中改变图的结构对GAT的影响很小。
图结构的并行计算:
一种新颖的做法是将图拼接成一个大图,而不是在每个批次的循环过程中进行图卷积。例如,图g有n个节点和e条边,卷积![]() 的输入,
的输入,
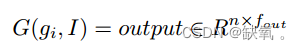
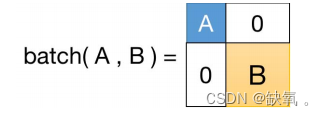
其中fin表示节点的特征,G()表示卷积操作,fout表示节点的新特征。对于批处理大小的次数,不需要在循环中运行上面的操作。然而,批处理图面临着挑战:图可以是稀疏的,也可以是大的。相比之下,它是将图批处理为并行处理卷积的大图。如图所示,批处理的输出仍然是图,这意味着对一个基本图的操作对于批处理的返回仍然是有效的。
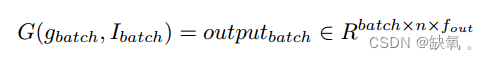
时间卷积层:
我们在时间轴上采用带有门控的扩展卷积结构提取时间相关性,如图所示。时间卷积层设置一维卷积,然后是门控线性单元。
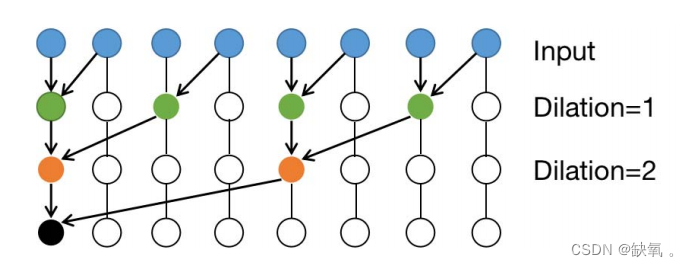
扩张卷积。内核大小设置为1和2
扩展卷积的优点是在不损失池化信息的情况下,增加了接受野,使每个卷积输出包含更大范围的信息。展开卷积可以应用于图像需要全局信息或语音,文本需要长序列信息的问题,如图像分割、语音合成、机器翻译等。扩展卷积的操作保持了特征映射的相对空间位置,这意味着我们的模型改进了接受域并考虑了历史信息。扩展的因果卷积方法变为:
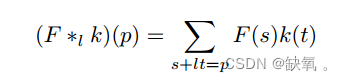
式中,F为二维序列(图像),s为定义域;K是核函数,t是定义域;L为膨胀因子;P是扩展卷积的定义域。上述公式与一维情况没有什么不同。
如果核大小为k,扩展卷积的步长为r,则接收野从k * k变为k + (r-1) * (k-1),后一部分表示要插入的零的个数。在展开卷积后,应用门控线性单元来确定信息通过层。如图所示,我们设置输入为X∈Rn×t×c,它具有三维(n为空间,t为时间序列,c为扩展卷积层产生的通道或特征)。卷积核![]() 将输入X映射到
将输入X映射到![]()
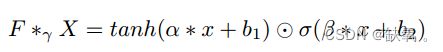
式中![]() ,并且
,并且![]() 表示元素上的阿达玛积。σ()是sigmoid门函数,它取决于哪些信息传播到下一步。
表示元素上的阿达玛积。σ()是sigmoid门函数,它取决于哪些信息传播到下一步。
实验:
数据集:
METR-LA包含了洛杉矶从2012年3月1日到2012年6月30日四个月的207个探测器的交通信息。PEMS-BAY包含了湾区从2017年1月1日至2017年5月31日6个月325个探测器的交通信息。探测器记录的数据每隔5分钟被分成多组。在这个实验中,一天的时间被划分为288个时间窗口。
Baselines:
我们将我们的模型与其他几个经典模型进行比较。为了使结果比较公平,一些模型(如STGCN)被复制并应用于同一数据集。一些结果直接引用了论文中的数据(例如,GaAN, GWaveNet)。读者可以在公开的代码中找到一些基线模型。
ARIMA:自回归综合移动平均
LSTM:长短期记忆
GaAN:用图卷积块和递归神经网络构建编码器-解码器网络
DCRNN:扩散卷积递推神经网络
WaveNet:用于时间序列任务的网络
Graph WaveNet:用于时间序列任务的图卷积网络
STGCN:时空图卷积网络
结果与分析:
与基线比较: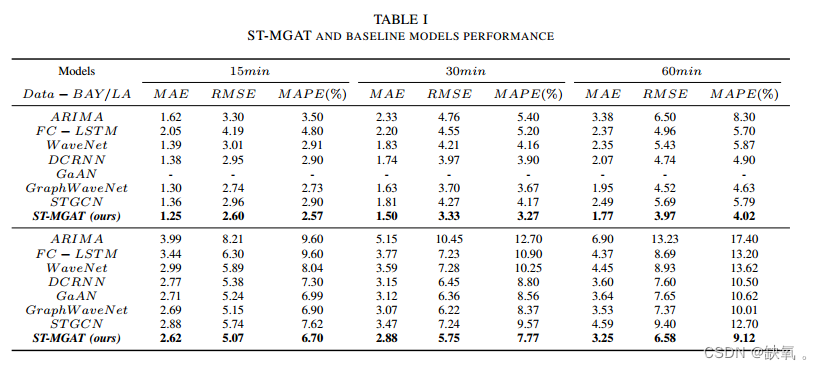
有/没有卷积比较:
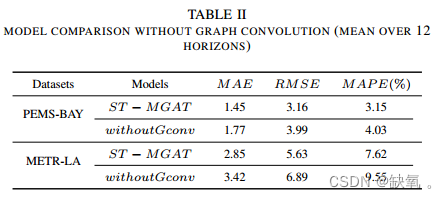
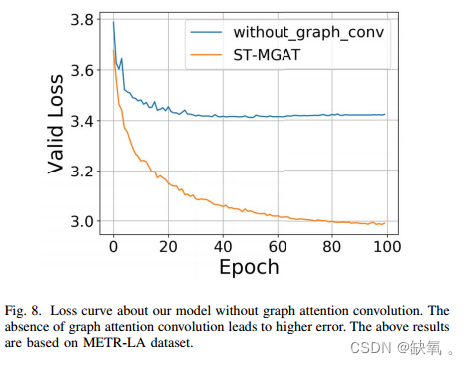
讨论:
我们尝试了许多方法,但有些不起作用。受多分量融合技术[27]的启发,该技术捕获历史交通数据中最近、每日和每周的周期性时间相关性。我们添加了相同节点在最近一天和一周的历史记录,但没有帮助。随着时间步数的增加,交通预测有轻微改善的趋势(视界为12步)。最后验证了基于当前时间点的下一时段交通流预测主要受最后几个小时的交通流控制。同样,将损失函数从MAE更改为RMSE可以改善RMSE,但不能改善其他指标。通过改变输入时间步长和增加图卷积隐藏通道,预测精度略有提高,但模型参数增加,耗时增加。
结论及未来工作:
本文提出了一种新的交通流预测模型ST-MGAT,该模型包含一个基于注意力的图卷积网络。据我们所知,我们首次将基于空间的方法而不是基于谱的方法应用于交通流预测任务,增强了模型的泛化能力。实验表明,该模型超越了基于卷积的方法,提高了处理变化路况的适应性。在未来的工作中,我们将把我们的模型应用到一般的图上,并添加诸如天气条件等补充信息,以进一步提高模型的精度。