在城市交通方面,交通时间序列预测具有非常重要的作用。由于复杂的时空动力学,交通时间序列预测具有挑战性,但当前大多数模型均是时间或空间不可知的,即使用固定参数模型,不考虑空间与时间的变化。本次为大家带来国际数据挖掘顶级会议ICDE 2022上的论文:《Towards Spatio-Temporal Aware Traffic Time Series》

一、背景
由于过去几年技术的快速发展,传感器被广泛地用于监测系统中。交通部门在不同的道路上部署了不同的传感器,这些传感器连续捕捉有用的交通信息,产生了大量的交通时间序列。使用这些序列进行交通预测是许多智能交通系统的核心组成部分,但由于其复杂的时空动态特性,准确的交通预测具有挑战性。
复杂的时空动态特性体现在,第一,从不同地点收集到的时间序列具有不同的模式;第二,时间序列内的模式经常随着时间的变化而变化。这说明我们应该同时空间感知建模和时间感知建模,即使用不同的模型参数对不同地点和不同时间段进行建模。所以,复杂的时空动态需要时空感知的预测模型,该模型需要(1)在不同的位置捕捉不同的模式;(2)快速适应不同时间段的模式变化。
然而,现有的方式往往是时空不可知的,因此无法捕捉时空动态。论文以数据驱动的方式,用时变和特定位置的模型参数,实现了时空感知的预测模型。文章使用注意力机制作为一个具体的模型,与RNNs和TCNs相比,它显示了更加优越的精度。
为了缓解时空感知模型参数生成造成的额外开销,文章还提出了一种新颖高效的注意力机制,以确保时空感知注意力也具有竞争效率。
二、相关工作
2.1 时间序列预测
为了准确地预测结果,对于时间动态进行建模是很重要的,但传统方式预测精度不足。研究表明,深度学习机制比传统方式的预测结果更优。最近,例如Tranformers的注意力机制在与基于RNNs和TCNs的模型相比表现出了优越的性能,因为它们更擅长处理长期依赖关系。为了解决输入序列长度对于内存和时间开销的限制,它们考虑长度为S的滑动窗口,每个时间戳只关注滑动窗口中的S时间戳,这导致了O(H×S)的复杂度,H是输入时间序列的长度。而本文是同线性复杂度来争取注意力。此外,现有的注意力模型仍然是时空不可知的,因为它们使用了相同的投影矩阵,而不管时间序列位置与时间周期。
2.2 基于深度学习预测的分类
文章从两个方面系统地回顾了深度学习在时间序列预测方面的研究,即空间感知和时间感知。首先,空间不可知模型对不同位置的时间序列使用相同的模型参数集,而空间感知模型对不同位置的时间序列使用不同的模型参数集。第二,时间不可知模型对不同时间段使用相同的模型参数集,而时间感知模型对不同时间段使用不同的模型参数集。
三、问题概述
3.1 问题定义
给定一组部署在空间网络不同位置的N个传感器,每个传感器产生一个多维时间序列,记录跨时间的F属性(例如,交通速度、交通流量)。假设每个时间序列总共有T个时间戳,文章使用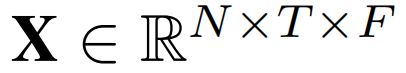 表示所有来自N个传感器的时间序列,
表示所有来自N个传感器的时间序列,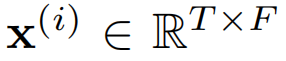 表示来自第i个传感器的时间序列,
表示来自第i个传感器的时间序列,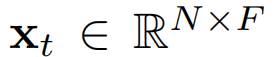 表示来自所有传感器在第t个时间戳的属性,
表示来自所有传感器在第t个时间戳的属性,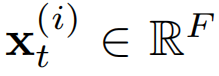 表示来自第i个传感器在第t个时间戳的属性向量。
表示来自第i个传感器在第t个时间戳的属性向量。
时间序列预测学习一个函数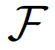 ,在时间戳t,给定所有传感器过去H个时间戳的属性,预测未来U个时间中所有传感器的属性。
,在时间戳t,给定所有传感器过去H个时间戳的属性,预测未来U个时间中所有传感器的属性。
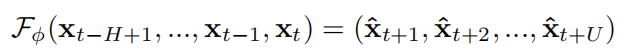
式中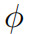 表示预测模型的可学习模型参数,
表示预测模型的可学习模型参数,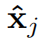 为j时刻的预测。
为j时刻的预测。
3.2 基于时空不可知注意力机制的预测
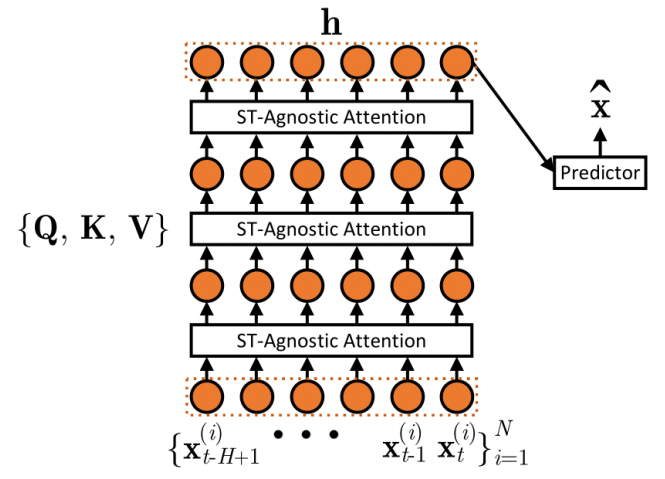
使用自注意力机制是时空不可知的,接下来将使用它作为例子来说明交通预测的时空感知建模需求。图一展示了基于自注意力机制的预测概述,其中堆叠了多个注意力层,当目标是捕获不同时间戳之间更复杂的关系时,堆叠多个注意力层以增加模型的表示能力通常是有用的,并且每一层的注意力使用自己的一组投影矩阵,最后一层的输出上应用一个预测器(如神经网络)来预测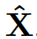 。
。
图一 时空不可知预测模型
单时间序列:考虑一个具有H个时间戳的输入时间序列,例如,来自第i个传感器的时间序列 。自注意力机制首先将时间序列转换为查询矩阵
。自注意力机制首先将时间序列转换为查询矩阵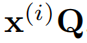 ,密钥矩阵
,密钥矩阵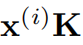 和价值矩阵
和价值矩阵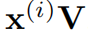 。这里投影矩阵
。这里投影矩阵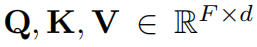 是自注意力机制中的可学习模型参数。
是自注意力机制中的可学习模型参数。
自注意力中的输出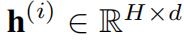 表示为价值矩阵中值的加权和,其中权值,即注意力分数,表示任意两个时间戳之间的成对相似性,并且它们基于查询矩阵和关键矩阵计算,如下式。
表示为价值矩阵中值的加权和,其中权值,即注意力分数,表示任意两个时间戳之间的成对相似性,并且它们基于查询矩阵和关键矩阵计算,如下式。
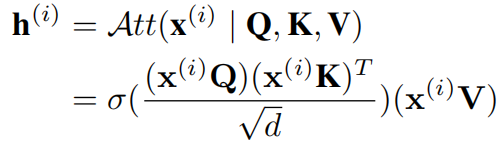
其中σ表示softmax激活函数。
多重时间序列:现在考虑来自所有N个传感器的时间序列,在此基础上可以重写如下式所示的自注意力机制。
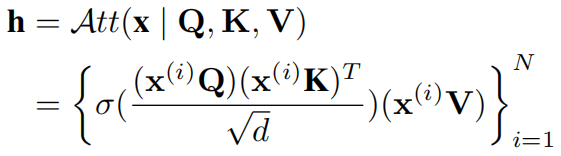
其中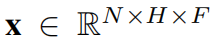 和
和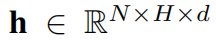 对于N个传感器。
对于N个传感器。
时空感知建模的需求:当对多个时间序列进行建模时,若对所有N个不同的时间序列和不同时间使用相同的密钥、查询和价值投影矩阵{Q,K,V},就产生了一个时空不可知模型。需要一种时空模型,对于不同的时间序列,使用不同的投影矩阵。
一个直接的解决方案时为每一个传感器采用一组不同的投影矩阵,但这导致了需要学习的参数数量过多,从而导致计算时间高、内存消耗大、收敛速度慢和过拟合问题。相反,文章建议只用编码器-解码器网络来生成这样的位置特变和时变的投影矩阵。该思想如图二所示,其中一个时空感知的模型参数生成器在每个于时间t结束的时间窗口期间为N个不同传感器的时间序列生成不同的模型参数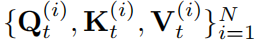 。这使得时空感知注意力机制不会导致模型参数指数爆炸。
。这使得时空感知注意力机制不会导致模型参数指数爆炸。

图二 时空感知预测模型
四、解决方法
4.1时空感知建模
4.1.1 设计考虑
文章提出了一种数据驱动和模型无关的方法来生成特定位置和时变的参数,从而能够将时空无关模型转变为时空感知模型。
首先,该方法是纯数据驱动的,仅依赖于时间序列本身。其次,该方法不局限于特定类型的模型,因为解码器可以为不同类型的模型生成模型参数。图三展示了一个解码器示例。该解码器为注意力输出特定位置和时变的模型参数,即投影矩阵。上述两个特征确保了现有的不同类型的时空不可知模型向时空感知模型的平滑转换,而无需使用额外的第三方信息。
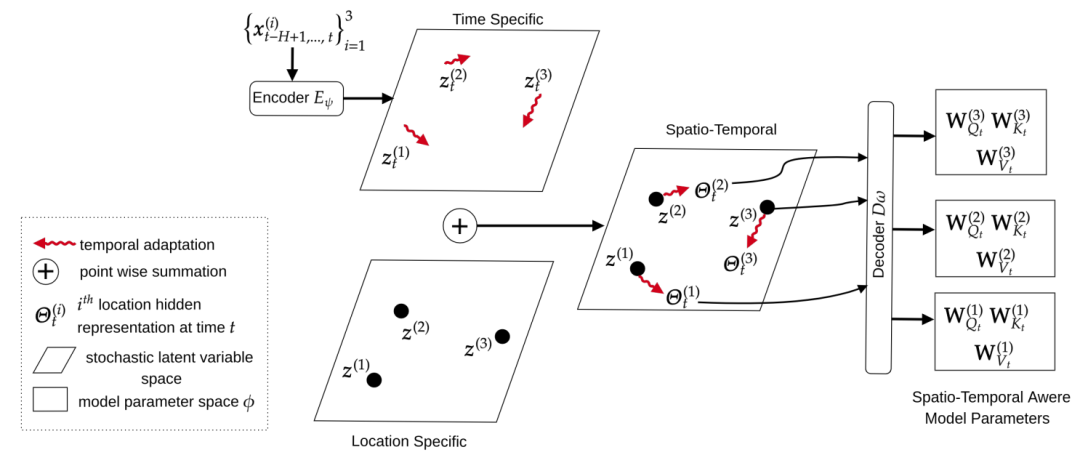
图三 时空感知模型参数生成
以注意力为例,文章说明了如何使用该方法将时空不可知的注意力机制转化为时空感知的注意力机制。在实验中,除了注意力机制,文章还在RNNs上测试了该方法,以证明该方法是模型不可知的。
图三展示了时空感知参数生成的概述。每个时间段内每个位置的时间序列学习一个唯一的随机潜变量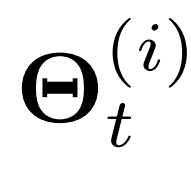 。更具体地说,
。更具体地说,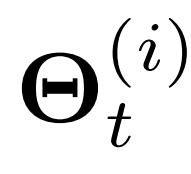 表示来自于时间t结束的周期的第i个时间序列的变量。
表示来自于时间t结束的周期的第i个时间序列的变量。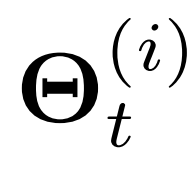 作为一个空间感知变量
作为一个空间感知变量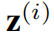 和一个时间感知变量
和一个时间感知变量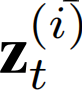 的和。然后使用来自
的和。然后使用来自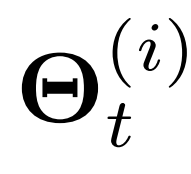 的解码器生成位于特定位置和时变的模型参数。这为生成不同模型的时空感知参数提供了便利,因此是模型不可知的。
的解码器生成位于特定位置和时变的模型参数。这为生成不同模型的时空感知参数提供了便利,因此是模型不可知的。
4.1.2学习随机潜变量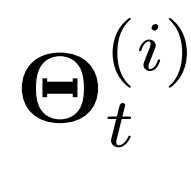
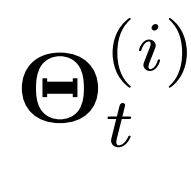 是以t结束的时间段内的第i个时间序列的唯一的随机潜变量,作为空间感知变量
是以t结束的时间段内的第i个时间序列的唯一的随机潜变量,作为空间感知变量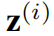 和时间感知变量
和时间感知变量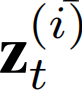 的和。
的和。
在这里,空间感知变量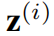 捕获第i个时间序列的最一般和最突出的模式,时间适应变量
捕获第i个时间序列的最一般和最突出的模式,时间适应变量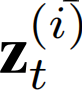 顾及到在不同时期最普遍模式的特定变化。使用随机变量,因为它们具有更好的泛化能力,与确定性变量相比具有更强的表示能力,确定性变量是协方差矩阵均为0的随机变量的特殊情况。
顾及到在不同时期最普遍模式的特定变化。使用随机变量,因为它们具有更好的泛化能力,与确定性变量相比具有更强的表示能力,确定性变量是协方差矩阵均为0的随机变量的特殊情况。
空间感知的随机潜变量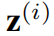 是有望代表第i个时间序列的最普遍和最突出的模式。它是空间感知的,因此预计可捕获来自不同位置的不同模式。由于不依赖任何关于潜变量分布的先验知识,假设它们在k维空间中遵循多元高斯分布。多元高斯分布提供了很好的属性,如损失函数中KL散度的解析评估和高效梯度计算的重新参数化技巧。在之后的实验中表明该建议优于确定性变体。
是有望代表第i个时间序列的最普遍和最突出的模式。它是空间感知的,因此预计可捕获来自不同位置的不同模式。由于不依赖任何关于潜变量分布的先验知识,假设它们在k维空间中遵循多元高斯分布。多元高斯分布提供了很好的属性,如损失函数中KL散度的解析评估和高效梯度计算的重新参数化技巧。在之后的实验中表明该建议优于确定性变体。
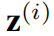 以纯数据驱动的方式直接可学习,而不使用编码器。使用编码器来生成信息往往无法从时间序列数据本省获得,这限制了该方法的适用性,因此选择纯数据驱动的设计。
以纯数据驱动的方式直接可学习,而不使用编码器。使用编码器来生成信息往往无法从时间序列数据本省获得,这限制了该方法的适用性,因此选择纯数据驱动的设计。
接下来,时间适应变量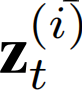 代表,即在特定时间t捕捉到的最突出的模式,改变,这适应了在时间t时的模式变换。因此,
代表,即在特定时间t捕捉到的最突出的模式,改变,这适应了在时间t时的模式变换。因此,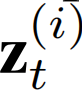 应该是随时间变化的时间感知。
应该是随时间变化的时间感知。
一个可变编码器来生成模型参数,因为它能捕获输入数据的分布,从而更好地泛化在训练期间从没见过的情况。注意两个随机变量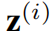 和
和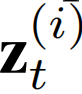 需要在同一个k维空间中,如图三的两个菱形。
需要在同一个k维空间中,如图三的两个菱形。
4.1.3解码到时空感知模型参数
模型使用一个由ω参数化的解码器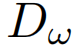 。由于不能直接通过分布反向传播梯度,首先根据到
。由于不能直接通过分布反向传播梯度,首先根据到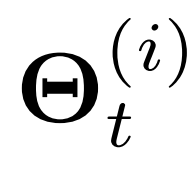 指定的分布,然后将其作为解码器的输入来生成模型参数。
指定的分布,然后将其作为解码器的输入来生成模型参数。
当在注意力机制中使用获得的特定于位置是时变投影矩阵式,它将时空不可知的注意力转化为时空感知的注意力,如下式。
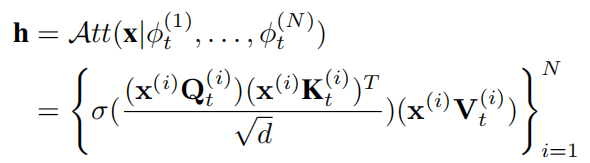
与其他朴素方法相比,文章所提出的时空感知模型参数生成大大减少了需要学习的参数量,这使得过拟合可能下降并提高了可扩展性。
4.2 高效的时空感知注意力
基于注意力机制的模型显示出准确性,但其二次复杂度限制了速度。模型将大小为H的输入时间序列分解为W=H/S的窗口,S为窗口大小。计算每一个窗口的注意力分数,对于每一个窗口,引入多个可学习代理。在每一个窗口中,每一个时间戳只对查询中的每个代理计算一个注意力分数,因此实现了线性复杂度。
图四举例说明了这个想法。假设对于每个窗口存在p个代表性的时间模式,使用p个代理来捕获这些模式。这些代理取代标准自注意力机制内部的查询。为此,引入了一个独特的可学习代理张量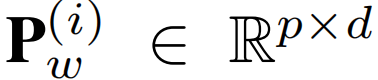 ,这使得在每个窗口,每个传感器一共有P个代理。每个代理使用一个d维向量,它可在窗口中捕获一个特定的、隐藏的时间模式。
,这使得在每个窗口,每个传感器一共有P个代理。每个代理使用一个d维向量,它可在窗口中捕获一个特定的、隐藏的时间模式。
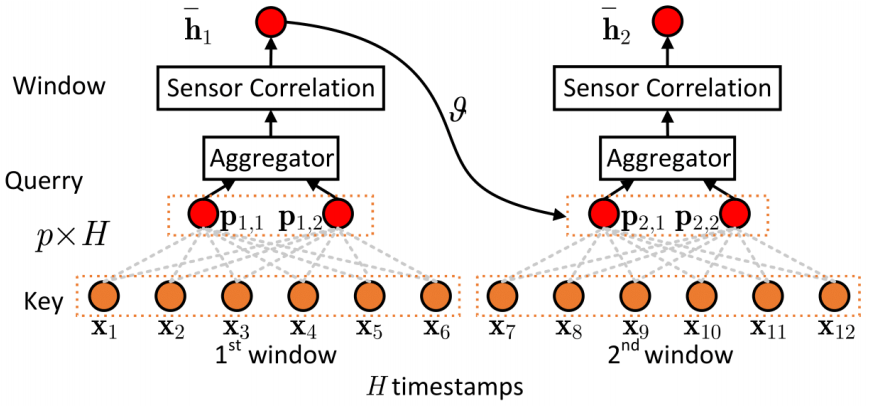
图四 窗口注意力
通过应用代理,规模为H的输入时间序列上的典型自注意力复杂性从二次降低到线性。为了进一步降低即将到来的层的复杂性,文章提出了一个聚合函数,负责将窗口内的所有代理聚合在一起,成为一个单一且共享的隐藏表示。由此产生的隐藏表示使得p成倍缩小,从而使得下一层的注意力得分计算更小。如图五所示。
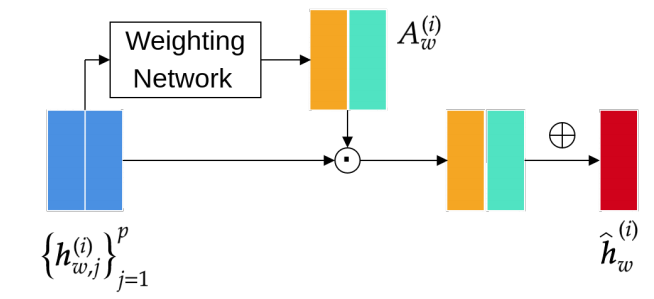
图五 代理聚合器示意图
首先使用一个加权网络对每一个代理进行加权,在计算了代理权重得分后,可计算最终的窗口。复杂度的降低使得模型无法捕捉不同窗口之间的关系,从而对准确性产生不利影响。为补偿这一点,一个窗口的输出会连接到下一个窗口代理,以便维持时间信息流。
4.3 传感器相关注意力机制
不同传感器采集到的信息往往具有相关性,所以需要对这种相关性进行建模。在聚合代理后,得到窗口的注意力输出。为捕获它们之间的相互影响,可使用归一化嵌入高斯函数,如下式。
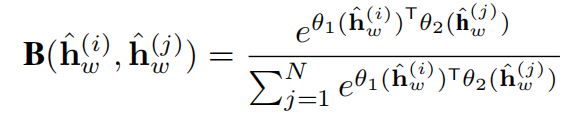
然后可以得到第i个传感器的更新表示
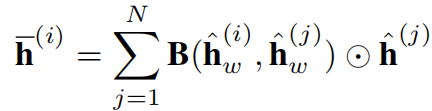
4.4 完整模型
在使用注意力机制时,往往将多层的注意力堆叠在一起以提高准确率。图六展示了完整模型
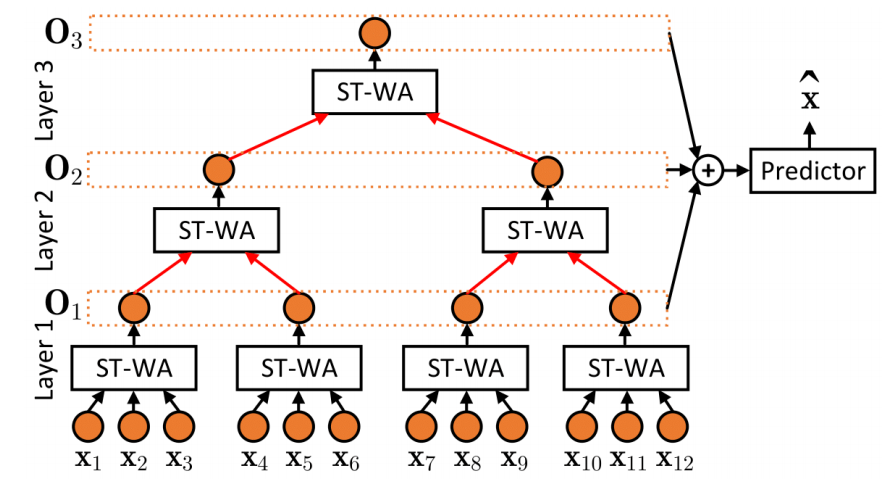
图六 完整模型
每个窗口注意力层都有自己的一组可学习的代理张量p,第一层的输出是通过每个窗口的输出派生出来的。由于输入的维度在每一层呈指数级减少,模型使用一层神经网络形式的跳跃连接来确保每一层之间的输出形状一致。最后采用一个具有两层神经网络的预测器。
4.5 损失函数与优化
通过端到端的方式优化损失函数,如下式
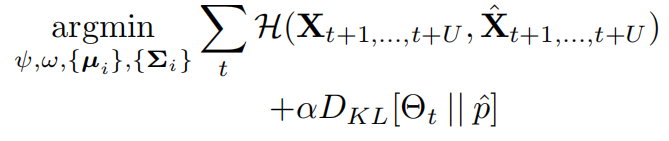
不同于传统的学习设置,文章直接优化模型参数,它是由解码器从随机潜变量生成的。因此,学习的目标是优化生成模型参数的参数。
五、实验
5.1 实验装置
实验在四个常用的公共交通时间序列数据集中进行测试,通过时间顺序划分数据集,60%用于训练,20%用于验证,20%用于测试。实验同时考虑扩展性和准确性,并使用其他其他空间或时间感知模型进行对比。在准确性方面,实验遵循现有文献中提出的平均绝对误差(MAE)、均方根误差(RMSE)和平均绝对百分比(MAPE)误差作为标准。实验使用PyTorch1.7.0在Python3.7.3上实现该时空感知模型和其他的模型,并在内部云上的计算机节点进行。
5.2 实验结果
结果说明和其他空间或时间感知模型相比,文章所提出的时空感知模型更加优秀的表现,精度与长时间预测的能力均优于其他模型,且内存效率很高。实验也证明了该模型参数生成是模型无关的,所以能够运用于不同类型的预测模型,并提高准确性。消融实验证明了模型各组成部分的有效性与重要性。在对于各个变量的研究中,文章指出,历史窗口增长对于实验结果的影响不大,甚至有一些还失去了准确性;在对于窗口大小的实验中说明该模型对于窗口大小不敏感;正则项对于实验精确度影响较大,这说明模型设计是正确的;代理数量越多精度越高,聚合函数越复杂精度越高。整体的运行时间相较于之前的模型有明显的进步。
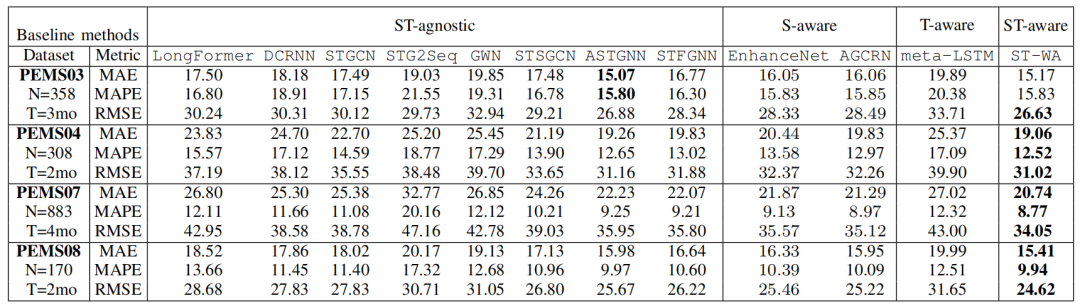
表一 总体精度(H=12,U=12)
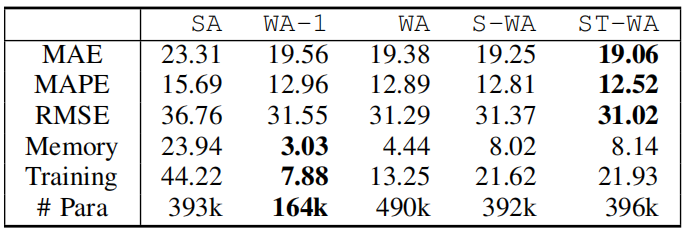
表二 消融研究
六、结论与展望
文章提出了一种数据驱动、模型不可知的方法,将时空不可知的模型转化为时空感知的模型。特别是,文章应用该方法实现了时空感知注意力机制,该注意力机制能够在交通时间序列中建模复杂的时空动态。此外,文章提出了具有线性复杂度的高效窗口注意力,从而确保了具有竞争力的整体效率。广泛的实验表明,所提出的建议优于其他最先进的方法。建议的一个局限性是,学习是基于潜随机变量遵循高斯分布的假设。在未来的研究中,例如采用非高斯随机变量的归一化流会成为研究方向。
推荐阅读:
我的2022届互联网校招分享
我的2021总结
浅谈算法岗和开发岗的区别
互联网校招研发薪资汇总
2022届互联网求职现状,金9银10快变成铜9铁10!!
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步
发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书