1 文章信息
文章题为“Interpretable local flow attention for multi-step traffic flow prediction”,是一篇发表于Neural Networks期刊上关于交通流多步预测的文章。文章源码可以在:https://github.com/hub5/LFAConvLSTM获得。
2 摘要
在过去的几年里,基于神经网络的方法在交通流预测(TFP)方面表现出了令人印象深刻的性能。然而,以往的研究大多未能明确有效地模拟流入与流出之间的关系。因此,这些方法通常是不可解释和不准确的。文章提出了一种用于TFP的可解释局部交通流注意力机制(LFA),该机制有三个优点:(1) LFA是流感知的(flow-aware)。不同于现有的工作,文章利用该注意力机制获取流量之间的相关性,而不是通过拼接的方式进行相关性提取。(2)LFA是可解释的。因为该机制是由交通流的真理来表述的,所学习的注意权重可以很好地解释流量相关性。(3)LFA是有效的。LFA没有使用全局空间注意力,而是利用局部注意力机制。不仅降低了计算成本,同时避免无效的注意力。在LFA的基础上,文章进一步开发了一种新的时空单元LFA-ConvLSTM(基于LFA的卷积长短期记忆),以捕捉交通数据中的复杂动态。具体来说,LFA-ConvLSTM由三个部分组成。(1)ConvLSTM模块学习特定流动特性。(2) LFA模块用于建模流之间的相关性。(3)特征聚合模块将上述两者融合,得到综合特征。文章在两个真实数据集上进行大量实验,结果表明,文章所提出的模型取得了更好的预测性能。此外,文章还提供了一些可视化结果来分析学习流的相关性。
总体而言,本文的主要贡献总结如下:
(1)文章提出了一个新的多步交通流预测框架,该框架由交通流的真理制定。在我们的方法中,流入和流出之间的关系被明确地建模,可以很好地解释。
(2)文章提出了一种新的局部流注意力机制(LFA),该机制更具可解释性和效率。通过局部注意查询,LFA可以度量流相关程度。在这里,LFA进一步有两种变体,分别符合流入和流出的真理。此外,LFA利用交通流的局部属性来避免昂贵的全局计算和错误注意。
(3)在LFA的基础上,提出了一种新的时空单元LFA-ConvLSTM。它不仅可以捕获特定流的动态,还可以学习流之间的相关性。此外,该单元格中的特征聚合部分融合上述两个特征以获得综合特征。
(4)文章进行了大量的实验来评估我们方法的有效性,结果表明文章所提出的模型实现了更好的预测性能。此外,文章还提供了一些可视化结果来分析学习流的相关性。
3 问题定义及模型整体框架
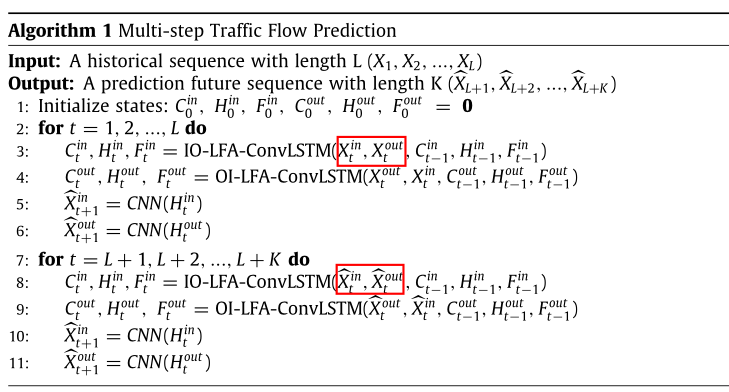
多步交通流预测(Ms-TFP):G表示目标区域,该区域被划分为m×n的网格。给定G中长度为L的历史交通序列 ,Ms-TFP旨在预测未来K步交通流
,Ms-TFP旨在预测未来K步交通流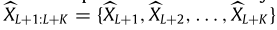 ,公式表示如下:
,公式表示如下:

其中,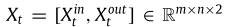 。
。
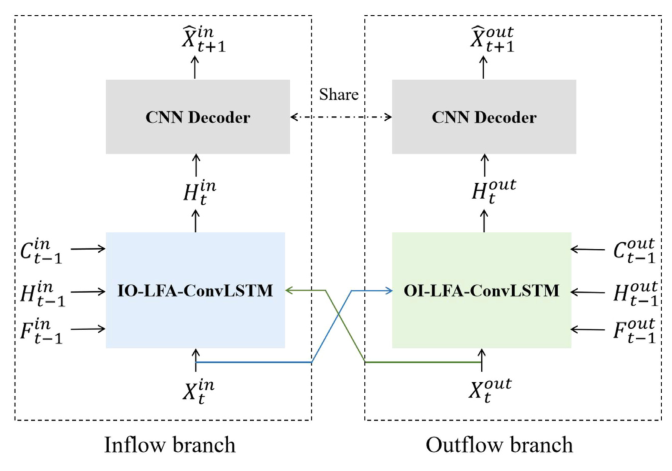
模型框架:如上图所示,流入量和流出量之间的相关性对于Ms-TFP至关重要。因此,为了明确有效地建模,文章提出了一个新的框架,如下图所示。该方法包括流入量分支和流出量分支,分别用于预测流入量和流出量。在每个分支中,文章利用基于局部流注意的ConvLSTM (LFA-ConvLSTM)捕获交通数据中的复杂动态。具体而言,t时刻的流量值(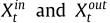 )被输入至LFA-ConvLSTM中用于获取t时刻的时空关系表示(
)被输入至LFA-ConvLSTM中用于获取t时刻的时空关系表示(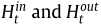 )。进一步共享的CNN解码层用于解码时空关系表示并生成预测值。此外,为实现多部预测,t时刻的输出为被作为t+1时刻的输入。
)。进一步共享的CNN解码层用于解码时空关系表示并生成预测值。此外,为实现多部预测,t时刻的输出为被作为t+1时刻的输入。
模型算法如下所示。
4 基于局部注意力机制的ConvLSTM(LFA-ConvLSTM)
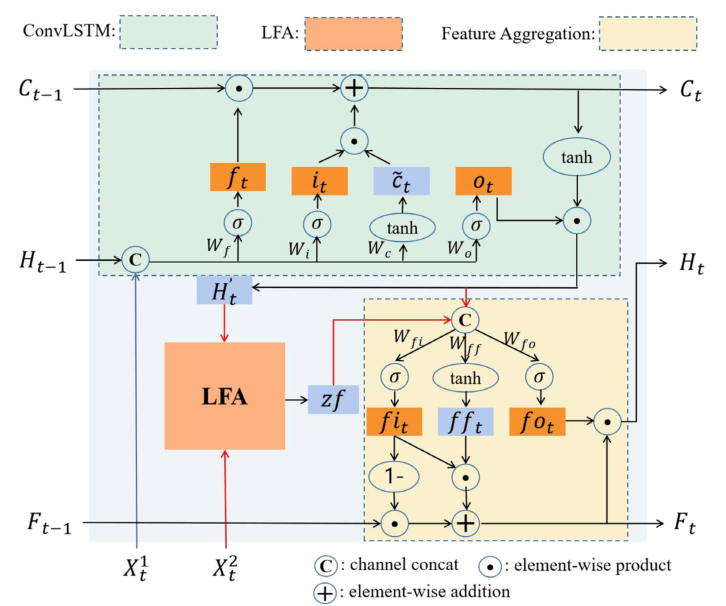
首先,文章基于以下真理设计LFA-ConvLSTM,如上图所示。
(1)流入量的真理:一个地区在时间t + 1的流入受到其邻近地区在时间t的流出的影响。
(2)流出量的真理:一个地区在时间t + 1的流出取决于它在时间t的流入。
具体而言,LFA-ConvLSTM由三个部分组成:(1) ConvLSTM部分用于生成特定流的表示。也为真理提供了未来的信息。2)提出了一个局部流量关注(LFA)部分,以明确地模拟流入和流出之间的相关性,这符合上述真理。LFA还有两种变体,即IO-LFA和OI-LFA,分别对应流入量分支和流出量分支。该部分的输出记为zf。(3)利用特征聚合部分融合特定流的表示()和流之间的相关性(zf)。
首先t时刻流量信息被输入至CovnLSTM层中,用于获取,可以提过未来信息,并被输入至LFA中。LFA包括两种变体,即IO-LFA和OI-LFA。下文将详细介绍。
IO-LFA
LFA的第一种形式是IO-LFA,用于模拟流出对流入的影响。该模型遵循了流入量的真理。具体而言,在t + 1时刻流入区域(i,j)的车辆或人群取决于在t时刻从区域(i,j)的邻近区域流出的车辆或人群。可以理解为,在t时刻,部分车辆或人群从(i,j)的邻近区域出发,在t + 1时刻到达(i, j)。
IO-LFA的输入包括两个部分:(1)Conv-LSTM的输出,用于表示t+1时刻的流入量信息;(2) 用于提供t时刻流出量的信息。此外,文章记为区域(i,j)的邻居,大小为k×k。
用于提供t时刻流出量的信息。此外,文章记为区域(i,j)的邻居,大小为k×k。
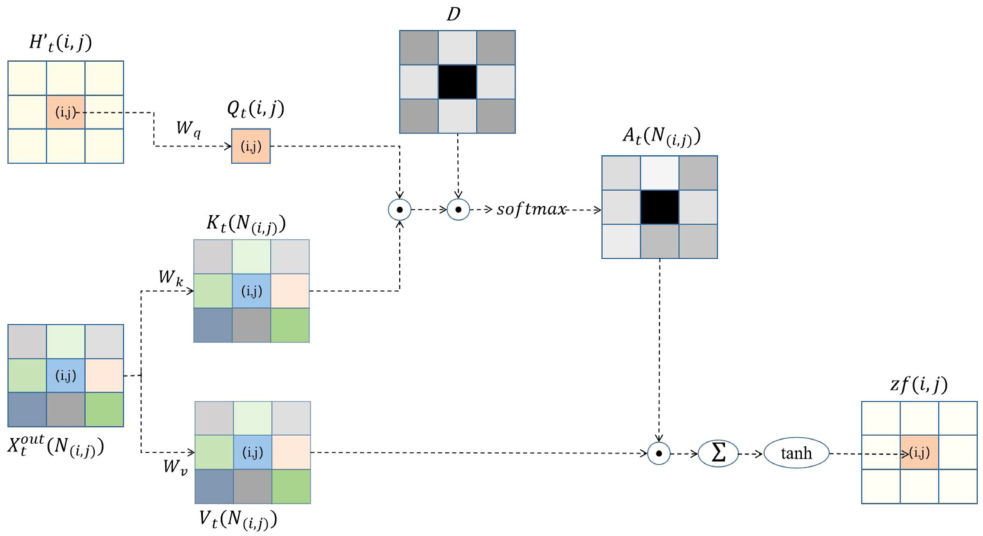
IO-LFA实现过程如图所示。具体而言,对于一个特定的区域(i,j),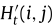 表示该区域t+1时刻的流入量,
表示该区域t+1时刻的流入量, 表示该区域t时刻周边区域的流出量。文章利用自注意力机制生成注意力权重,计算公式如下:
表示该区域t时刻周边区域的流出量。文章利用自注意力机制生成注意力权重,计算公式如下:

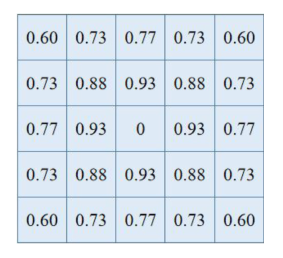
此外,在利用Softmax进行归一化至前,文章提出基于距离的先验权重D,用于生成注意力权重:

下图展示了D矩阵的一个样例。可以看到与中心点直线距离越近的点,值越大,即越相关。这是因为车辆或人群更有可能从较近的地区涌入。此外,将(i, j)的权值设为0,可以解释为区域(i, j)不能流入自身。
获取注意力权重后,文章利用求和的方式得到所选区域的最终结果zf:
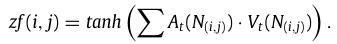
zf用于衡量流出量对流入量的影响。在IO-LFA中,可解释性体现在两个方面。(1)它是根据流入的真理设计的,可以清楚地观察到流入和流出是如何相互作用的。(2)习得的注意权重可以反映流的关联程度,其值越大,说明交互作用越多。此外,由于仅使用局部注意力机制,该模型的计算复杂度相较于全局注意力机制有所下降。
OI-LFA
与IO-LFA相似,文章提出了OI-LFA用于模拟流入量对流出量的影响。OI-LFA遵循流出的真理。具体而言,t +1时刻从区域(i,j)流出的车辆或人群取决于区域(i,j)在t时刻的流入。可以理解为,大量的流入会导致大量的流出。OI-LFA的输入包括两个部分:(1)Conv-LSTM的输出,用于表示t+1时刻的流出量信息;(2)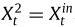 用于提供t时刻流出量的信息。下图展示了OI-LFA的计算流程。
用于提供t时刻流出量的信息。下图展示了OI-LFA的计算流程。

OI-LFA与IO-LFA有类似的计算。然而,OI-LFA是以像素到像素的方式执行的,而不是像素到邻域的方式(IO-LFA)。这是因为一个地区的流出更多地取决于它自己以前的流入。具体计算公式如下所示:
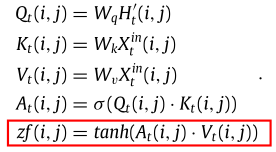
特征聚合层
首先,在获取流量动态特征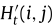 以及流量相关性zf之后,文章提出用于记忆流量信息,计算公式如下:
以及流量相关性zf之后,文章提出用于记忆流量信息,计算公式如下:
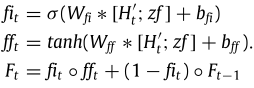
特征聚合层利用上述变量,采用输出门处理结果,并更新。
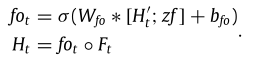
5 实验
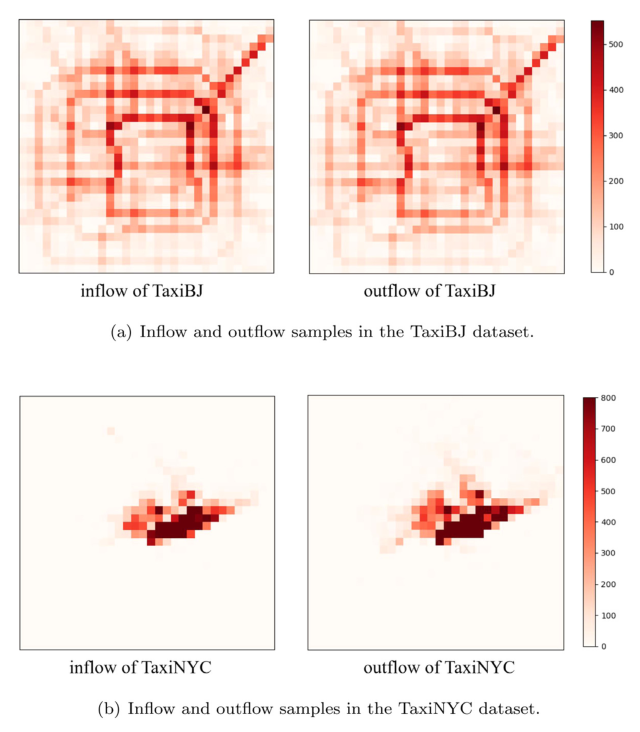
文章使用了两个交通数据集,即TaxiBJ和TaxiNYC。具体而言,(1)TaxiBJ由北京地区出租车GPS轨迹数据组成。(2) TaxiNYC记录了纽约市出租车和豪华轿车委员会(TLC)的黄色出租车行程。下图展示了交通流样例。
基于上述数据集,文章比对所提出模型和基线模型的性能,如下表所示。

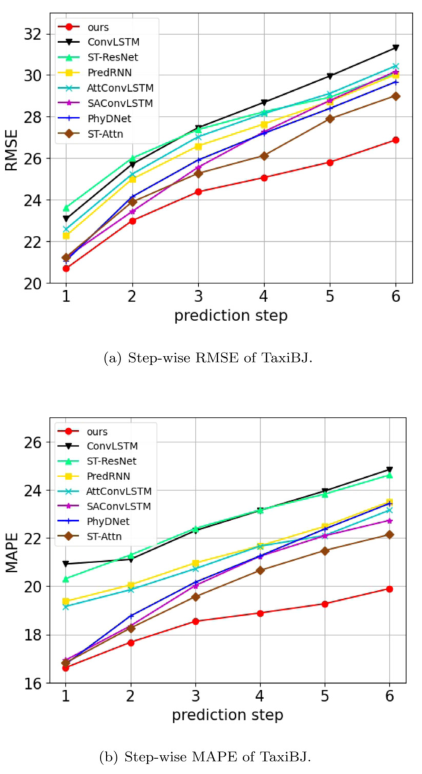
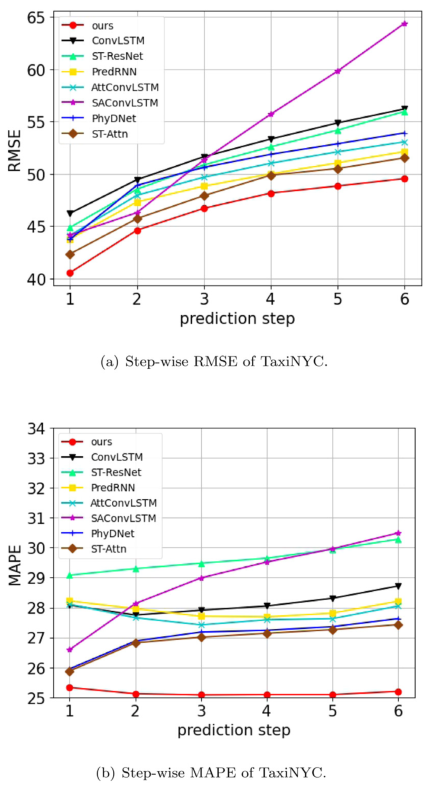
进一步,文章分析了不同模型在两个数据集上,不同预测时间步的各项指标,如下图所示。
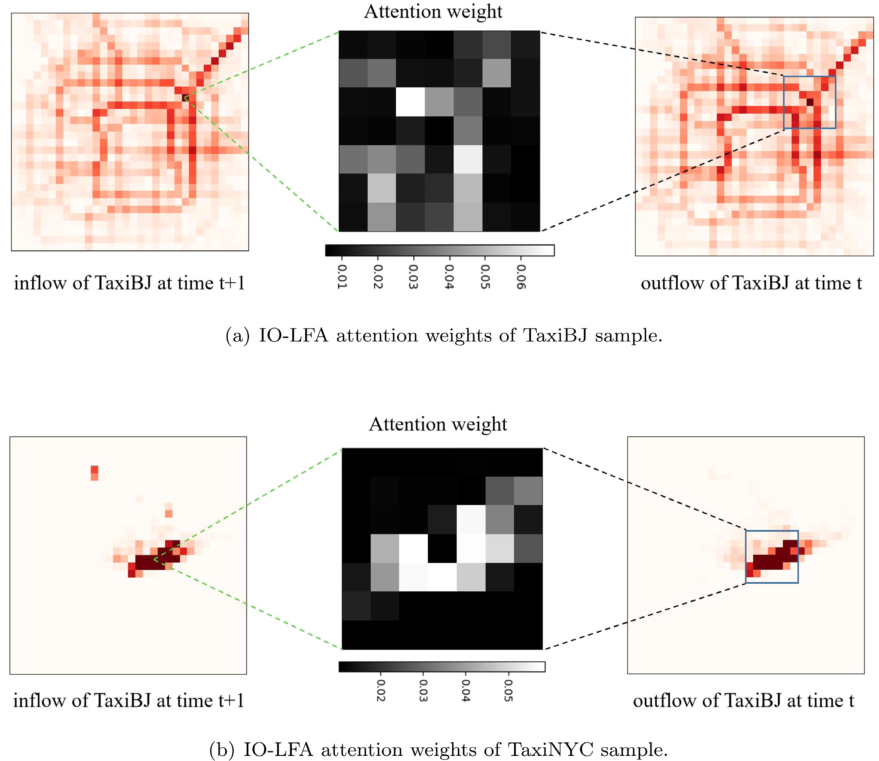
此外,文章对LFA进行分析。对于IO-LFA而言,如下图所示,可以发现,注意力权重不是均匀分布的。一般来说,权重较大的区域有两个特点。(1)距离相关区域(i, j)较近。这说明车辆或人群更容易在相邻区域之间流动。交通流的这种局部属性促使我们利用局部空间注意力而不是全局模式。(2)流出量大,这是一个重要前提。显然,一个资本流出较小的地区不可能为其他地区的资本流入做出很大贡献,即使它们之间很接近。
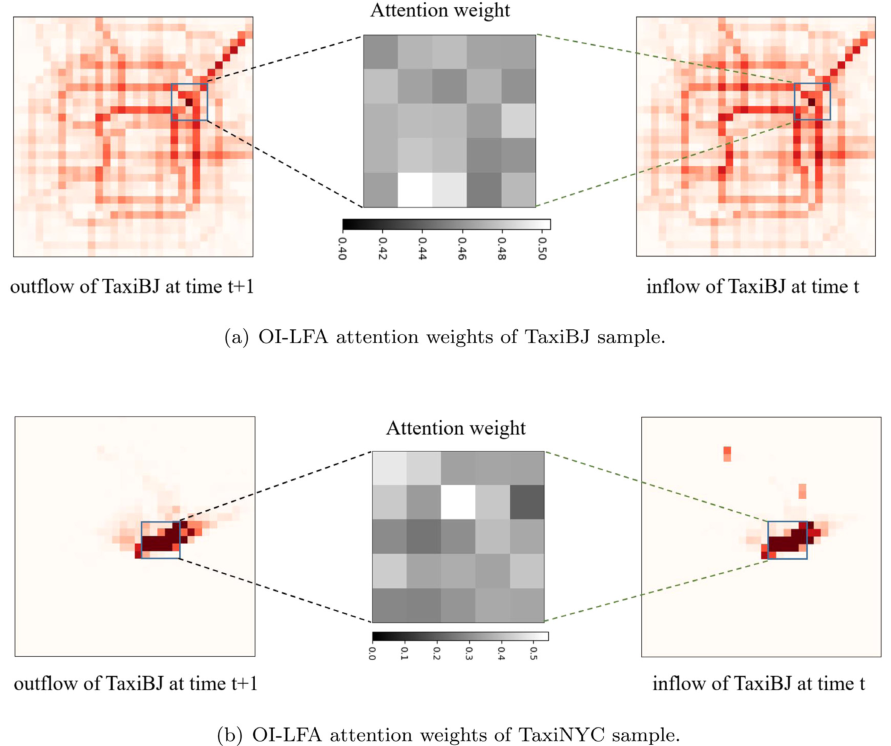
对于OI-LFA而言,如下图所示,可以观察到,注意权重略有变化,大多数都接近0.5。这表明,资本流入和流出之间确实存在显著的相关性。具体而言,OI-LFA中的关注权重反映了区域流出的计算依赖于其先前流入的程度。非零权重表明流感知特征在预测中发挥着重要作用。可以得出OI-LFA有助于更好地了解流出动态,从而有助于更准确的预测。
6 总结
文章提出了一种新的局部流注意(LFA)机制,用于多步交通流预测。LFA是由交通流的不言自明的原则来表述的,其中流入和流出之间的相关性被明确地建模。因此,我们的模型可以理解为不言自明。此外,LFA利用局部注意力来学习空间依赖关系,而不是像以前的工作那样使用全局模式。这不仅降低了计算成本,而且避免了长距离的错误注意。在LFA的基础上,文章进一步开发了一种新的时空单元LFAConvLSTM来捕捉交通数据中的复杂动态。在两个数据集上的大量实验表明,文章所提出的方法可以通过显式和有效地建模流量相关性来实现更好的预测性能。此外,可视化分析也表明LFA可以反映一些交通流的常识。例如,一个距离较近且有大量资本流出的地区,通常对其周边地区的资本流入贡献更大。
推荐阅读:
我的2022届互联网校招分享
我的2021总结
浅谈算法岗和开发岗的区别
互联网校招研发薪资汇总
2022届互联网求职现状,金9银10快变成铜9铁10!!
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步
发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书