点击蓝字
关注我们,让开发变得更有趣
作者:冯浩 辽宁科技大学 研究生
指导教师:张海刚 英特尔边缘计算创新大使 深圳职业技术大学 副教授

当今,深度学习技术在计算机视觉领域取得了巨大的突破,使得各种图像处理任务变得更加智能化。其中,Semantic Segmentation(语义分割)是一项重要的任务,它有助于计算机理解图像中不同对象的位置和边界。本文将介绍如何使用 OpenVINO™ Python API 部署 FastSAM 模型,以实现快速高效的语义分割。
FastSAM 官方仓库:
https://github.com/CASIA-IVA-Lab/FastSAM
OpenVINO™ 官方仓库:
https://github.com/openvinotoolkit/openvino
FastSAM 模型部署实现代码仓库:
https://github.com/zhg-SZPT/FastSAM_Awsome_Openvino
(复制链接到浏览器打开)
什么是 FastSAM 模型?
FastSAM 模型是一种轻量级语义分割模型,旨在快速而准确地分割图像中的对象。它经过了精心设计,以在较低的计算成本下提供卓越的性能。这使得 FastSAM 模型成为许多计算机视觉应用的理想选择,包括自动驾驶、医学图像分析和工业自动化等领域。
步骤一:安装 OpenVINO™
要开始使用 OpenVINO™ 进行推理 FastSAM 模型,首先需要安装 OpenVINO™ Toolkit。OpenVINO™ 是英特尔发布的开源工具,专为深度学习模型部署而设计。
你可以按照以下步骤安装OpenVINO™ :
访问OpenVINO官方网站下载OpenVINO工具包。
按照官方文档的说明进行安装和配置。
OpenVINO™ 下载安装链接:
https://www.intel.com/content/
www/us/en/developer/tools/openvino-toolkit/download.html
(复制链接到浏览器打开)
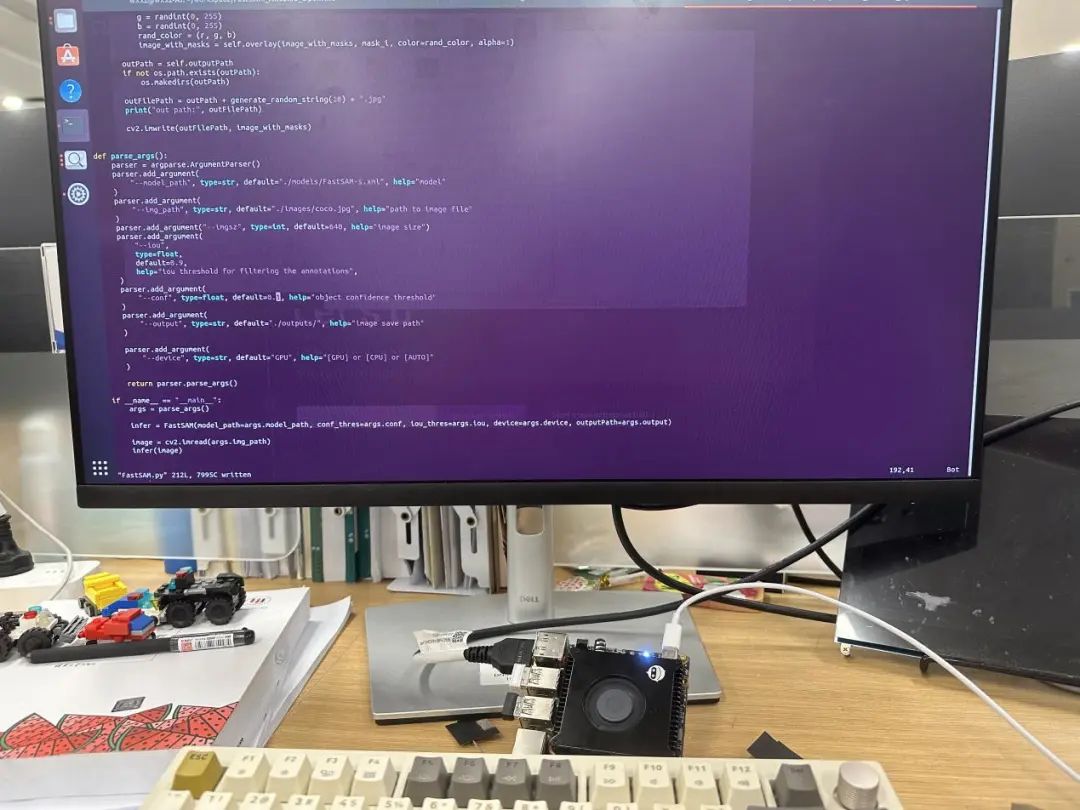
步骤二:下载 FastSam 官网模型
FastSAM 模型可以在官方 GitHub 中找到。下载模型并将其解压缩到合适的文件夹。根据自身情况下载合适的预训练模型。
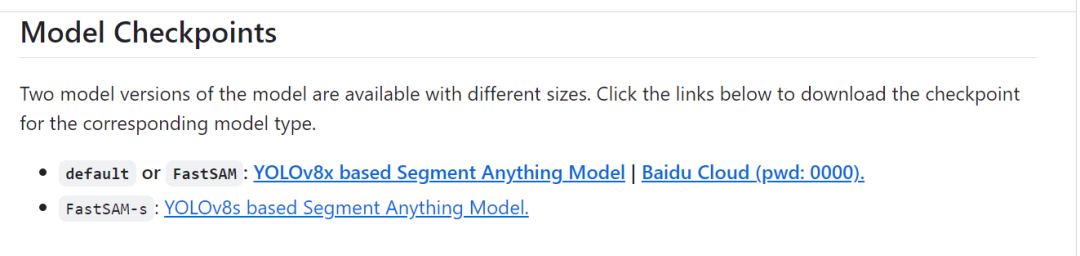
这里还需要将下载到的模型,由于这个模型是采用的pytorch 类型的格式,所以还需要将这个 pt 模型转换为 OpenVINO™ 的 IR 模型才能进行调用推理。
转换步骤如下所示:
Pytorch → onnx → IR
需要先导出为 onnx 标准格式,然后经过这个压缩优化转化为 IR 模型。
OpenVINO™ 官方提供一个模型转换工具 Model Optimizer,可以利用这个更加便捷的转换我们的模型。
例如:
mo --input_model FastSAM-s.onnx就会在当前目录下生成对应的 FastSAM-s.bin 和 FastSAM-s.xml 文件,这就是所谓的 IR 模型了。
步骤三:使用 OpenVINO™ Python API
接下来,我们将使用OpenVINO™ Python API来部署FastSAM 模型。由于官方提供的这个预训练模型也是基于yolov8进行优化的,所以也需要有和yolov8 相似的处理步骤:
加载模型 → 读图 → 预处理 → 推理 → 后处理
1. 加载模型
加载模型需要创建一个 Core, 然后对模型进行读取编译:
core = ov.Core()
model = core.read_model(model=model_path)
self.compiled_model = core.compile_model(model = model, device_name=self.device)左滑查看更多
2. 读图
我们使用 opencv 读取任意一张彩色图像:
Image = cv2.imread(“image_path”)3. 预处理
预处理主要包括 3 部分,其一是将图像重新排列为模型所需要的类型(一般来说是 batch Size, channels, height, width), 其二是归一化图像大小为模型输入需求的大小, 其三是将 opencv 的图像原始数据放置到 numpy 类型的数据中方便处理。
以下是一个简单的 Python 预处理,展示了如何对输入的图像进行预处理:
def Preprocess(self, image: cv2.Mat, targetShape: list):
th, tw = targetShape
h, w = image.shape[:2]
if h>w:
scale = min(th / h, tw / w)
inp = np.zeros((th, tw, 3), dtype = np.uint8)
nw = int(w * scale)
nh = int(h * scale)
a = int((nh-nw)/2)
inp[: nh, a:a+nw, :] = cv2.resize(cv2.cvtColor(image, cv2.COLOR_BGR2RGB), (nw, nh))
else:
scale = min(th / h, tw / w)
inp = np.zeros((th, tw, 3), dtype = np.uint8)
nw = int(w * scale)
nh = int(h * scale)
a = int((nw-nh)/2)
inp[a: a+nh, :nw, :] = cv2.resize(cv2.cvtColor(image, cv2.COLOR_BGR2RGB), (nw, nh))
rgb = np.array([inp], dtype = np.float32) / 255.0
return np.transpose(rgb, (0, 3, 1, 2)) # 重新排列为batch_size, channels, height, width左滑查看更多
4. 推理
在模型的推理之前需要先加载预训练好的模型,推理部分只需要调用compiled_model 将预处理好的数据放入即可得到输出结果:
result = self.compiled_model([input])左滑查看更多
但这只是一个同步的推理过程,有感兴趣深入研究的的同学可以参考官网的异步推理。
异步推理参考网址:
https://docs.openvino.ai/2023.1/
openvino_inference_engine_ie_bri
dges_python_sample_c
(复制链接到浏览器打开)
5. 后处理
后处理主要有两件事,第一是对输出的结果进行非极大抑制,第二是将抑制后的结果进行遍历处理掩膜。以下是一个简短的例子:
def Postprocess(self, preds, img, orig_imgs, retina_masks, conf, iou, agnostic_nms=False):
p = ops.non_max_suppression(preds[0],
conf,
iou,
agnostic_nms,
max_det=100,
nc=1)
results = []
proto = preds[1][-1] if len(preds[1]) == 3 else preds[1] # second output is len 3 if pt, but only 1 if exported
for i, pred in enumerate(p):
orig_img = orig_imgs[i] if isinstance(orig_imgs, list) else orig_imgs
# path = self.batch[0]
img_path = "ok"
if not len(pred): # save empty boxes
results.append(Results(orig_img=orig_img, path=img_path, names="segment", boxes=pred[:, :6]))
continue
if retina_masks:
if not isinstance(orig_imgs, torch.Tensor):
pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape)
masks = ops.process_mask_native(proto[i], pred[:, 6:], pred[:, :4], orig_img.shape[:2]) # HWC
else:
masks = ops.process_mask(proto[i], pred[:, 6:], pred[:, :4], img.shape[2:], upsample=True) # HWC
if not isinstance(orig_imgs, torch.Tensor):
pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape)
results.append(
Results(orig_img=orig_img, path=img_path, names="1213", boxes=pred[:, :6], masks=masks))
return results左滑查看更多
这样就可以拿到这个掩码矩阵数据,这样就可以根据这个矩阵绘制掩码即可得到最终图像:


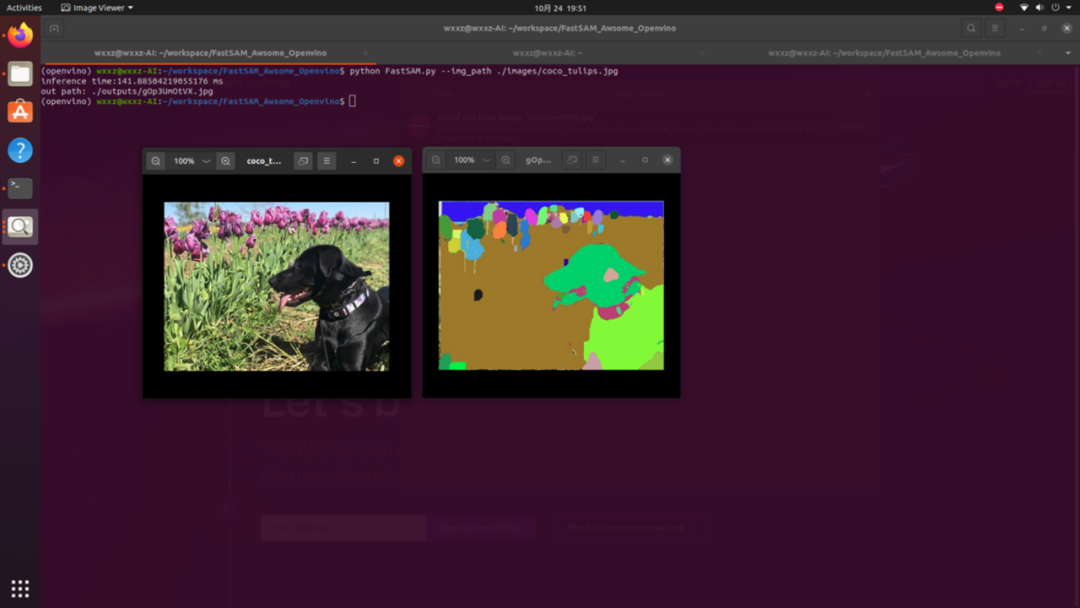
完整代码可以参考Github:
https://github.com/zhg-
SZPT/FastSAM_Awsome_Openvino
(复制链接到浏览器打开)
结语
本文介绍了如何使用 OpenVINO™ Python API 部署 FastSAM 模型,以实现快速高效的语义分割。以在较低的计算成本下提供卓越的性能。这使得 FastSAM 模型成为许多计算机视觉应用的理想选择,包括自动驾驶、医学图像分析和工业自动化等领域。
OpenVINO™
--END--
你也许想了解(点击蓝字查看)⬇️➡️ 开发者实战 | 介绍OpenVINO™ 2023.1:在边缘端赋能生成式AI➡️ 基于 ChatGLM2 和 OpenVINO™ 打造中文聊天助手➡️ 基于 Llama2 和 OpenVINO™ 打造聊天机器人➡️ OpenVINO™ DevCon 2023重磅回归!英特尔以创新产品激发开发者无限潜能➡️ 5周年更新 | OpenVINO™ 2023.0,让AI部署和加速更容易➡️ OpenVINO™5周年重头戏!2023.0版本持续升级AI部署和加速性能➡️ OpenVINO™2023.0实战 | 在 LabVIEW 中部署 YOLOv8 目标检测模型➡️ 开发者实战系列资源包来啦!➡️ 以AI作画,祝她节日快乐;简单三步,OpenVINO™ 助你轻松体验AIGC
➡️ 还不知道如何用OpenVINO™作画?点击了解教程。➡️ 几行代码轻松实现对于PaddleOCR的实时推理,快来get!➡️ 使用OpenVINO 在“端—边—云”快速实现高性能人工智能推理扫描下方二维码立即体验
OpenVINO™ 工具套件 2023.1点击 阅读原文 立即体验OpenVINO 2023.1
文章这么精彩,你有没有“在看”?