作者:辽宁科技大学 研究生 冯浩
指导教师:英特尔边缘计算创新大使 深圳职业技术大学 副教授 张海刚
当今,深度学习技术在计算机视觉领域取得了巨大的突破,使得各种图像处理任务变得更加智能化。其中,Semantic Segmentation(语义分割)是一项重要的任务,它有助于计算机理解图像中不同对象的位置和边界。本文将介绍如何使用Openvino c++ API部署FastSAM模型,以实现快速高效的语义分割。在前文中我们发表了《基于Openvino Python API部署FastSAM模型|开发者实战》,在该文章中我们向大家展示了基于openvino Python API的基本部署流程。在实际部署过程中会考虑到由效率问题,使得我们可能更倾向于采用更高效的部署方式,故今天我们将向大家展示使用Openvino c++ API部署Fastsam模型,并且对比预处理、推理、后处理等时间的消耗。
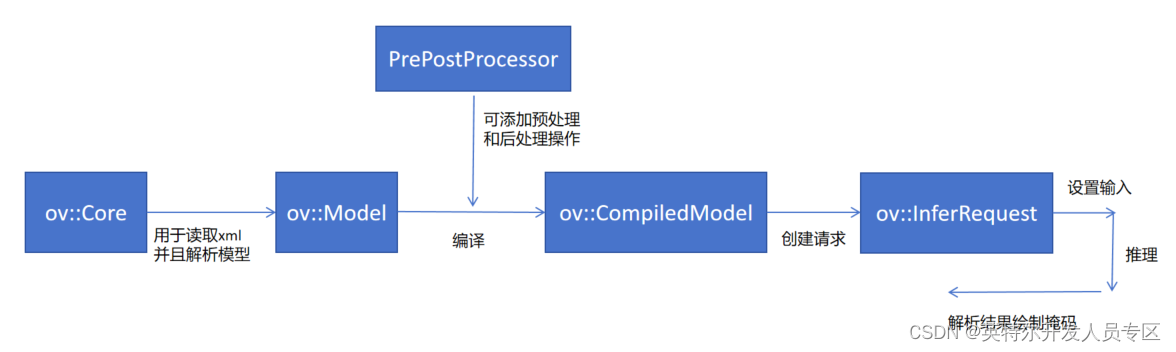
首先简单解释一下这个c++版本Openvino的推理构建流程。首先需要一个Core 去读取前面生成的xml文件(这个文件包含了模型的网络结构,与其对应的同名文件bin后缀的是模型的权重和偏置)。
读取完成之后他会返回一个Model 类,可以通过这个Model 类来生成生成最终编译完成的模型。在这里的编译不是我们常规意义上的编译代码,本质上是在模型中插入一些函数指针,也就是所谓的预处理和后处理的函数。当我们有这个PrePostProcessor的步骤之后在我们每次调用推理的时候就可以不用自己去手动的处理图像的一些简单操作,比如转换图像大小、转换数据排列顺序、以及颜色编码顺序等等。
拿到这个CompiledModel之后可以调用这个create_infer_request来创建最终我们需要的推理请求的类。最后调用infer进行模型推理。
1. 模型的转化和优化
在之前的文章我们已经了解到了模型的导出方式,大家可以参考《基于Openvino Python API部署FastSAM模型|开发者实战》,或者参考笔者的GitHub中的导出部分。
2. 初始化推理引擎和加载模型
在c++初始化openvino推理引擎和Python的基本结构相似,也是使用一个Ov::Core来创建Ov::Model。
m_model = m_core.read_model(xml_path);
m_ppp = std::make_shared<ov::preprocess::PrePostProcessor>(m_model);
m_ppp->input().tensor()
.set_element_type(ov::element::f32)
.set_color_format(ov::preprocess::ColorFormat::RGB)
.set_layout("NCHW");
/*
还可添加你模型所需要的预处理和后处理的操作
m_ppp->input().preprocess()
.convert_layout("NCHW"); //比如排列顺序转换
*/
m_model = m_ppp->build();set_shape(ov::Shape({1, 3, 640, 640}))3. 预处理输入图像
本次我们采用的是手动预处理输出数据,需要预处理输入图像的大小位模型所需的输入的大小即640x640,其次我们需要转换这个由opencv读取来的BGR图像位RGB,最后需要将这个数据排列顺序由NWHC转换为NCWH。实现代码如下
ov::Tensor FastSAM::Preprocess(const cv::Mat &image)
{
float height = (float)image.rows;
float width = (float)image.cols;
int target_size = input_height;
float r = std::min(target_size / height, target_size / width);
int padw = (int)std::round(width * r);
int padh = (int)std::round(height * r);
if((int)width != padw || (int)height != padh)
cv::resize(image, m_image, cv::Size(padw, padh));
else
m_image = image.clone();
float _dw = target_size - padw;
float _dh = target_size - padh;
_dw /= 2.0f;
_dh /= 2.0f;
int top = int(std::round(_dh - 0.1f));
int bottom = int(std::round(_dh + 0.1f));
int left = int(std::round(_dw - 0.1f));
int right = int(std::round(_dw + 0.1f));
cv::copyMakeBorder(m_image, m_image, top, bottom, left, right, cv::BORDER_CONSTANT,
cv::Scalar(114, 114, 114));
this->ratio = 1 / r;
this->dw = _dw;
this->dh = _dh;
Normalize2Vec(m_image);
return ov::Tensor(ov::element::f32, ov::Shape({1, 3, (unsigned long)input_height, (unsigned long)input_width}), input_data.data());
}4. 执行推理
在执行完这个Preprocess之后会返回一个ov::Tensor, 将前面预处理好的input tensor 设置为输入数据,然后执行infer即可进行推理。
m_request.set_input_tensor(input_tensor);
m_request.infer();5. 获取和处理输出数据
在推理完成之后可以通过调用get_output_tensor来获取指定索引的输出指针,这里我们采用的模型只有两个维度的输出。
auto* p0 = m_request.get_output_tensor(0).data(); // 获取第一个维度输出
auto* p1 = m_request.get_output_tensor(1).data(); // 获取第二个维度输出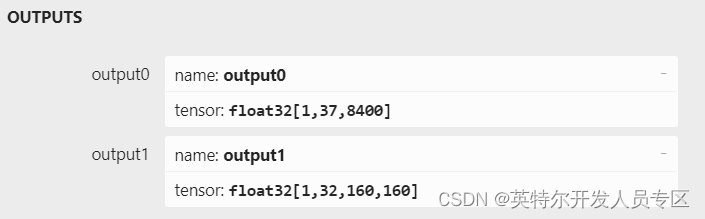
当拿我们到这个输出的数据之后我们需要解析后做后处理,首先是对第一个维度的数据解析做非极大抑制,将的到的bbox的坐标进行还原,使得这个坐标对应的是原始图像掩码的坐标而不是输入图像掩码的坐标。最后把还原后的数据的最后掩码维度和模型输出维度进行矩阵相乘后的到最终的mask。
std::vector<cv::Mat> FastSAM::Postprocess(std::vector<cv::Mat> &preds, const cv::Mat& oriImage)
{
std::vector<cv::Mat> result;
std::vector<cv::Mat> remat;
NMS(remat, preds[0], 100);
cv::Mat proto = preds[1];
cv::Mat box = remat[0];
cv::Mat mask = remat[1];
ScaleBoxes(box, oriImage);
return ProcessMaskNative(oriImage, proto, mask, box, oriImage.size());
}6. 绘制掩码到原图上
绘制掩码就比较简单了,将原始图像输入,和mask掩码矩阵传入进来。最后会把生成的掩码添加到image上。
void FastSAM::Render(cv::Mat &image, const std::vector<cv::Mat>& vremat)
{
cv::Mat bbox = vremat[0];
float *pxvec = bbox.ptr<float>(0);
for (int i = 1; i < vremat.size(); i++) {
cv::Mat mask = vremat[i];
auto color = RandomColor();
for (int y = 0; y < mask.rows; y++) {
const float *mp = mask.ptr<float>(y);
uchar *p = image.ptr<uchar>(y);
for (int x = 0; x < mask.cols; x++) {
if (mp[x] == 1.0) {
p[0] = cv::saturate_cast<uchar>(p[0] * 0.5 + color[0] * 0.5);
p[1] = cv::saturate_cast<uchar>(p[1] * 0.5 + color[1] * 0.5);
p[2] = cv::saturate_cast<uchar>(p[2] * 0.5 + color[2] * 0.5);
}
p += 3;
}
}
}
}7. 实现效果展示:


FastSAM With Openvino推理时间(未加渲染时间)
使用设备: xBoard、iGPU
| Preprocess |
Inference |
Postprocess |
Total |
|
| Python |
5±2ms |
125±5ms |
300±10ms |
430±10ms |
| CPP |
12±2ms |
110±5ms |
110±5ms |
330±5ms |
完整代码可以参考笔者Github。