线性扫描寄存器分配
- 论文地址:
Linear Scan Register Allocation
我们描述了一种称为线性扫描的快速全局寄存器分配的新算法。该算法不基于图形着色,而是在变量生存范围的单个线性时间扫描中将寄存器分配给变量。线性扫描算法比基于图形着色的算法要快得多,并且易于实现,并且生成的代码几乎与使用基于图形着色的更复杂且耗时的寄存器分配器获得的代码一样高效。该算法适用于关注编译时间的应用程序,例如动态编译系统、“即时”编译器和交互式开发环境。
不使用图着色算法的根本原因是它要先构造好完整的干涉图,才能在图上着色,而干涉图的构造代价太过高昂。应该说,图着色过程中的大部分开销都集中于干涉图的构造阶段。因此,虽然图着色生成的代码质量很高,但是对于讲究编译效率的现代编译器来说,其时间成本是不可忽视的。对于对编译时间更加敏感的 JIT 编译器来说,则更是如此。除此之外,在实际的编译工作中,人们发现了另外一个问题。由于在目前所有的硬件架构中,寄存器的数目都是有限的,故对于大型程序来说,寄存器不够用可以说是必然存在的情况。换句话说,大型程序一定会产生大量溢出。问题就出现在这里,因为图着色算法把重点放在解决“如何把所有的程序变量尽可能地分配到寄存器中”,如果程序一定会大量产生溢出,那么,关注“如何高效地溢出”比关注“如何尽量减少溢出”更有价值。
spill:溢出,是指目前的寄存器不够使用,该部分数据需要借助sram或者堆栈区域的空间进行缓存协调的行为。
寄存器的数量是有限的,因此当程序中使用了过多的变量或产生了大量的临时计算结果时,编译器可能会出现寄存器不足的情况,导致寄存器溢出。这可能会导致编译器将某些变量或数据存储在内存中,而不是寄存器中,从而降低了程序的执行效率。
1. 算法介绍
线性扫描寄存器分配算法是一种用于在编译器中分配寄存器的算法,旨在将程序中的变量映射到计算机的寄存器,以提高程序的执行效率。该算法通常用于编译器的代码生成阶段,用于生成目标代码。
线性扫描寄存器分配算法的基本思想是,通过一次线性扫描来分配寄存器,从而在程序的不同位置为变量分配寄存器。该算法不需要进行复杂的数据流分析,因此相对较快且简单。以下是线性扫描寄存器分配算法的主要步骤:
- 构建活跃变量区间(Live Range):首先,通过数据流分析计算每个变量的活跃区间,即变量在程序中被使用的区间。活跃区间通常是变量在程序中的生命周期。
- 排序活跃变量区间:将所有活跃变量区间按照其结束位置从小到大进行排序。
- 遍历活跃变量区间:从排好序的活跃变量区间列表中,按顺序遍历每个区间。在遍历过程中,为每个区间分配一个可用的寄存器,并在需要时将之前分配的寄存器释放。
- 确定溢出:如果某个区间没有足够的可用寄存器,即产生溢出,算法会尝试将某个寄存器的值移出到内存中,以腾出空间来分配给新的变量。
线性扫描寄存器分配算法的优点在于简单易实现,适用于中等规模的代码生成。然而,它可能不如其他更复杂的寄存器分配算法(如图着色法)在某些情况下能够达到更高的性能。不同的编译器可能会使用不同的寄存器分配算法,以根据特定的需求和目标平台进行优化。
2. 相关概念
live interval:生命间隔
live range:生命周期
interference:相交(conflict)
active list:已经分配物理内存的节点集合
3. 算法的实现
3.1 伪代码

3.2 图示
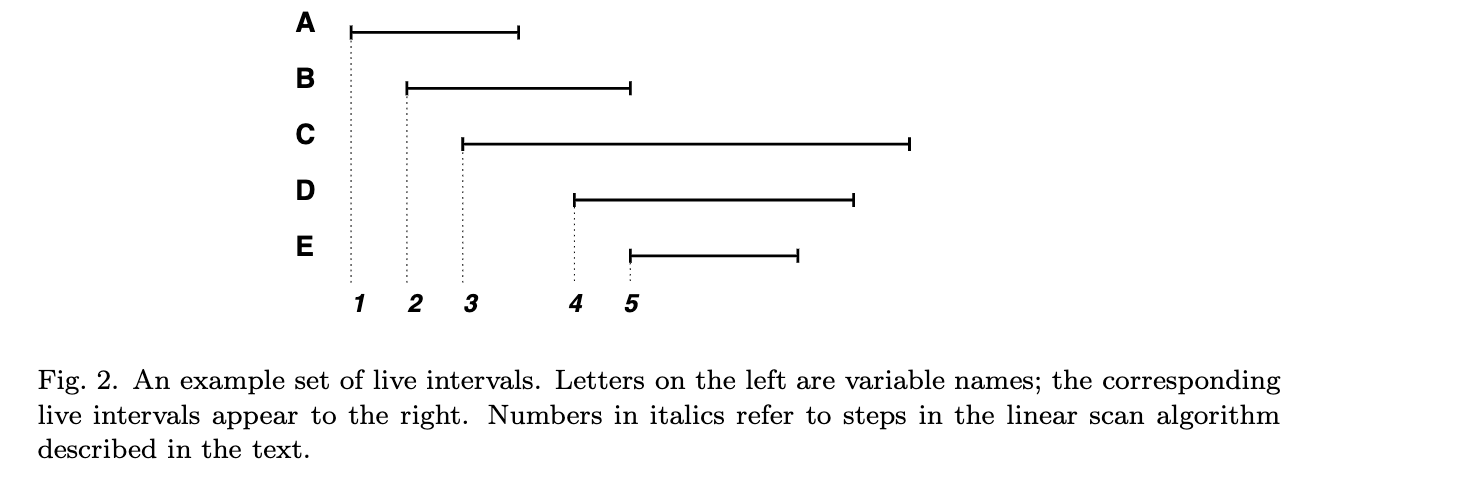
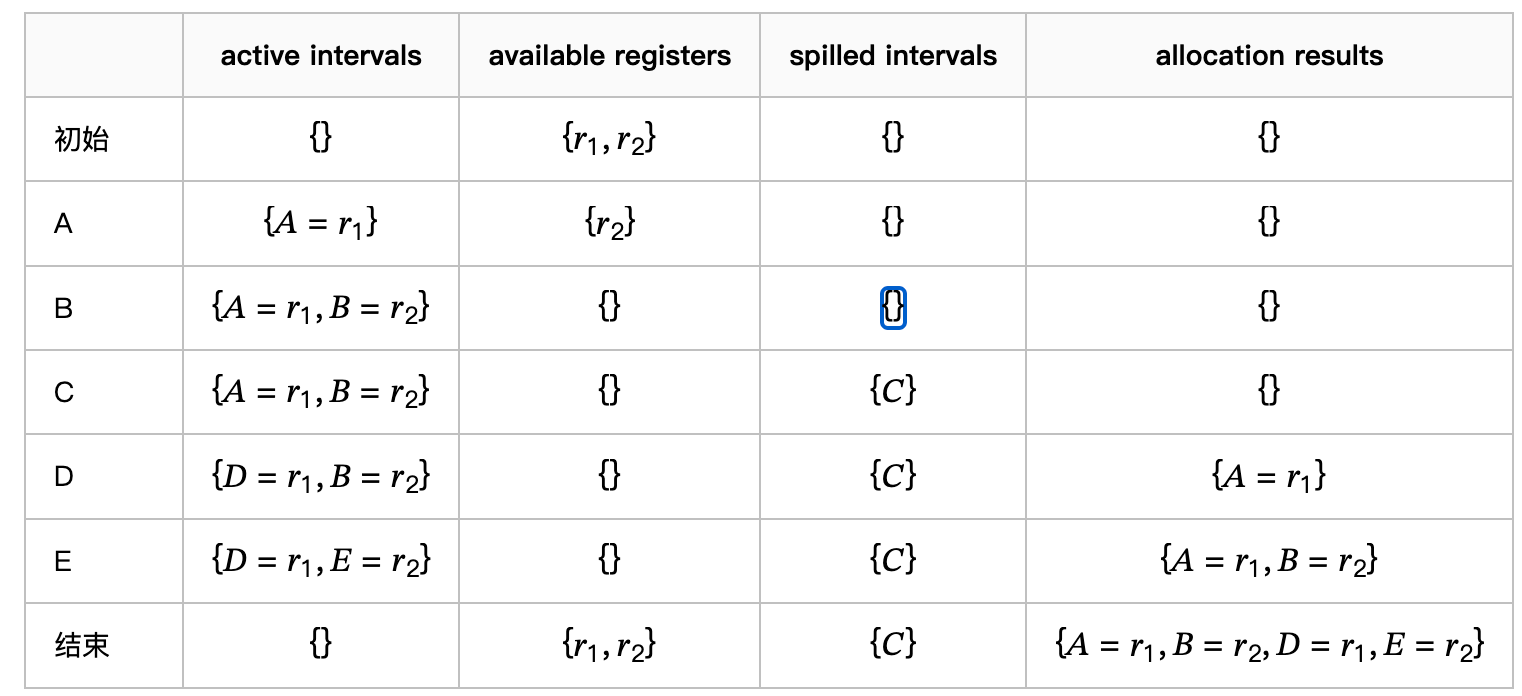
参考文献
[1] Register Allocation in LLVM 3.0
[2] Hacker News - Register Allocation
[3] Linear Scan Register Allocation
[4] Register Allocation
[5] 博客圆-线性扫描寄存器分配