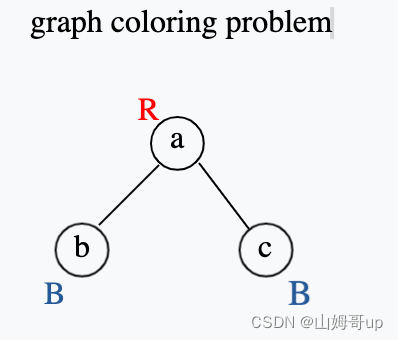
这里显示了 a b c的生命周期 发现其中是存在conflict的 即重叠部分

以下的这个图像a和b有conflict 即连线 a和c之间有conflict 即连线 b和c没有 所有不连线
在有重叠的部分其实表现的是在同一时间需要多个寄存器来存储了 那个怎么样在有着各种conflict的指令中找到寄存器使用的最小数量 即最优数量 无疑就是在graph coloring problem找到最少的颜色使用 这时一个NP-complete复杂度问题
算法只能保障有99%的概率找到最优分配 但是没有办法100%保证
这里每一个方框就是一个basic block 存储着一段指令 live in 就代表之前块定义过 接下来会使用的
live cost 就是之前块和当前块定义的 需要在接下来消耗的
局部寄存器分配指的是每一个basic block的物理寄存器分配彼此间是独立的 当进入一个新的block后 所以的都会重新分配
全局寄存器分配指的是把这些basic block链接在一起进行物理内存的分配
这里我们引出两个代码运行效率的概念 compile time 和 performance
局部寄存器分配因为是在一个block中分配的 所以实现非常简单 可以节约很多编译时间 它的优势在于compile time 但是编译完成后运行这些代码的过程 即在cpu执行0和1的过程 叫做performance 而局部寄存器的performance就是劣势
而全局寄存器分配是刚好相反的 在comile time需要跟多的时间 但是performance会表现很好 注意全局寄存器分配不需要像局部分配一样在每一个block结束以后需要把所有的def和use都store 然后在新的block中又把需要的所有def和use进行load 全局分配需要通过conlict graph算法求出以插入最少的store和load为代价使得代码能流畅的作为一个整体运行下去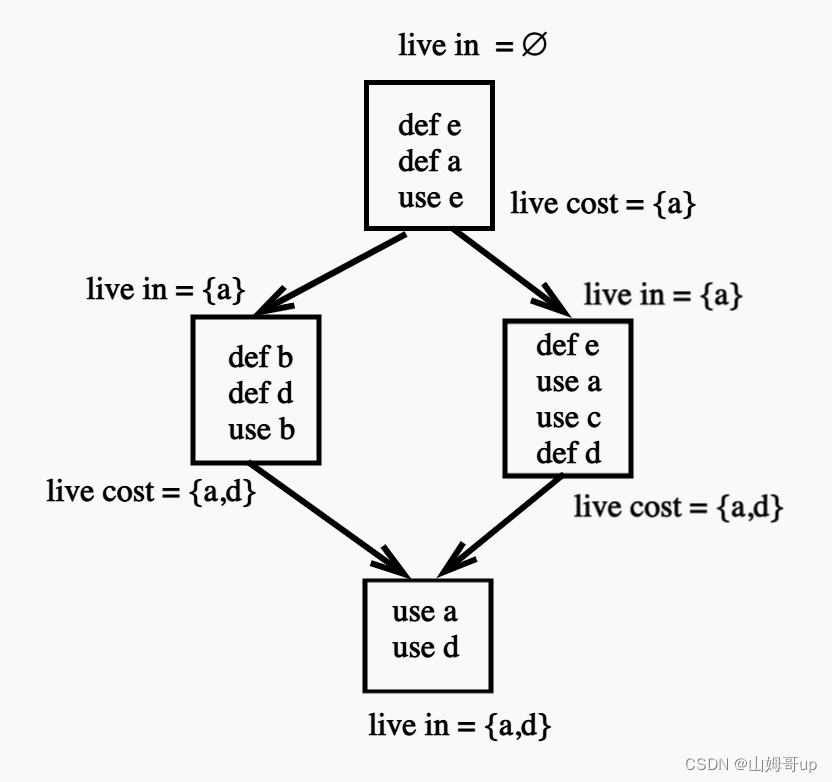

这里看到 a b d形成了一个类型与环形结构的conflict 这里叫做一个clique 所以这里至少需要三种颜色 也就是三个物理寄存器分配才不会出现spill的情况,即物理内存起不够分配需要占用内存空间临时储存
在物理寄存器不够分配的时候 我们需要插入store和load来临时导入内存并在需要的时候拿出来 这也意味着我们需要尽可能的少插入store和load来提升效率 所以我们会通常选择使用次数较少的变量地址导入内存 因为后续没使用一次 就需要load一次
可以想象 应当尽量避免在循环中出现访问内存的情况
所以在上图中 如果我们只有两个物理寄存器 能插入最少store和load的选择就是变量b
指需要在最左边的block中def b后面插入一个store b 在use b之前插入一个load b即可
可以看出 这里把b导入内存是在减少物理寄存器数量的前提下消耗最小的 但是这也不是绝对的 因为这里并没有显示每一个block的执行频率 最后的消耗是看store和load的数量乘上所在block的频率
这里我们家上发现每一个block的execution frequency 是0.5是因为被拆分了 是10是因为这个block处在一个循环体中

cost for def : # of defs x cost of store x exec freq
cost for use : # of uses x cost of load x exec freq
spill cost for a = 1x1x1 + 1x2x0.5 + 1x2x10 = 22
spill cost for b = 1x1x0.5 + 1x2x0.5 = 1.5
spill cost for c = 1.5
spill cost for d = 1x1x0.5 + 1x1x0.5 + 1x2x10 = 21
spill cost for e = 1x1x1 + 1x2x1 = 3
假设此时我们只有两个物理寄存器 意味着在conflict graph中我们只能标记两个颜色 具体流程如下:
首先 问题的关键在与clique a b d 所以要按照cost的从小到大依次spill
spill的本质其实就是加入store和load临时导入内存后 让它们的live range减小 以至于conflict减小
先spill b 那么它的live range就变成如下
结果发现conflict graph还是存在一个clique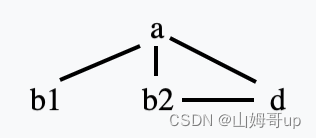
所以继续进行spill 所以这次spill d
⚠️注意:b的spill还是保留着的
spill d后可以发现 在conflict graph中已经不存在clique了 说明可以用两种颜色表示
我们可以定义a为红色 b1 b2 d1 还有c e都是绿色 至于d2 它是完全孤立于其他node的 所以红色绿色都没问题 到此 spill就算是结束 成功用最小的cost把virtual register 分配到了2个物理寄存器中
在这个例子中 问题还是比较简单容易别解决 但是在有些复杂的情况下 这个问题可以会出现bug 比如能够分配的物理寄存器过于少了 就会一直不停的spill下去 最后可能会导致BUG
或许在第一次spill b之后可以发现只要调用一下左侧def d和 use b2的位置就能解决问题 不需要再次spill了 但是注意编译器不能同时做寄存器分配和寄存器调度的工作 因为这会导致算法过于复杂 当前算法只能一条路走到死 然后再换一条路走 而不能智能的无缝切换衔接