下面是一段抽象汇编指令
load a to r1
load b to r2
mult r1 r2 to r3
首先声明的是 这里为什么叫抽象汇编指令因为我们假设是有无限多的寄存器的 我们可以一直r1 r2 r3 r4 ……我们称这些寄存器为virtual register(虚拟寄存器) 而后端中的register allocation做的工作就是把这些虚拟寄存器映射到真实的寄存器上
其次这里发现r1和r2都存储着真实的变量(variable)a和b 而r3却是一个中转的临时变量(temporaries) 实际中的汇编是没有变量这个概念的 实际中只有寄存器和内存地址
在优化过程中 例如common subexpression elimination(CSE)就是会增加变量的数量来减少重复计算,一旦变量太多 就会增加寄存器的负担,导致一部分变量不能存在速度最快的寄存器中而是存在了内存中 就有可能会适得其反降低了代码运行速度
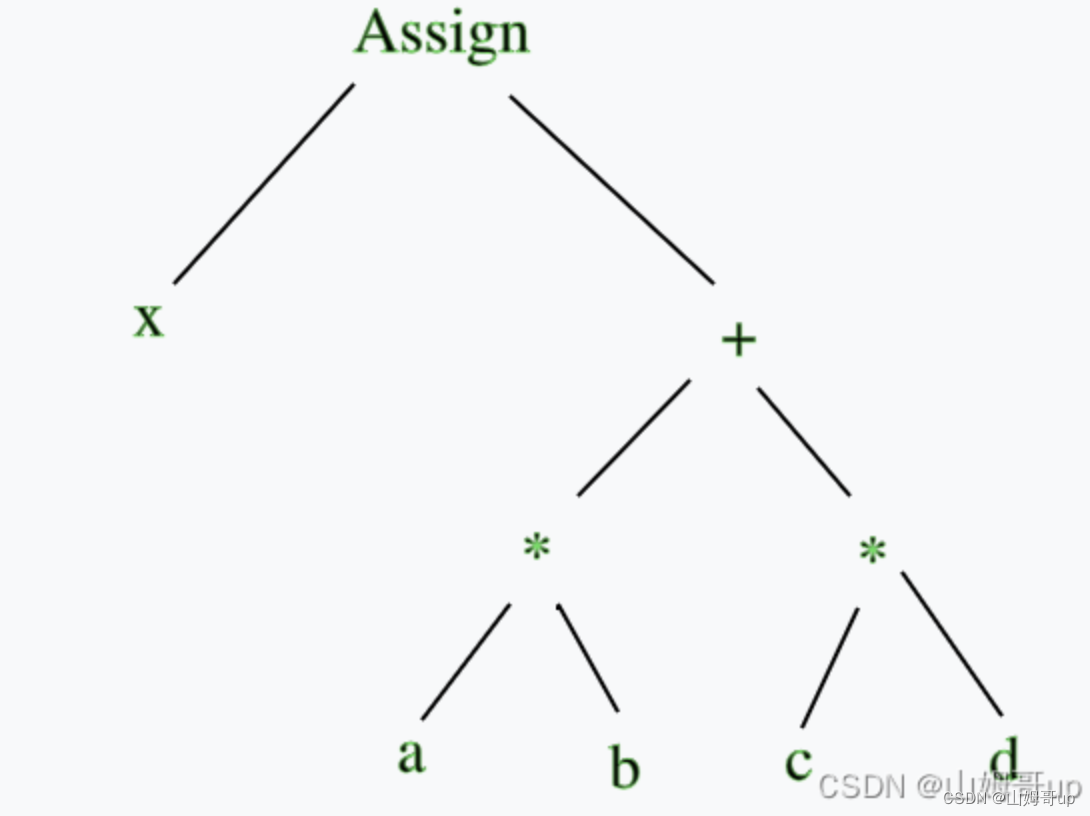
如何通过一个AST转换成抽象汇编指令呢 这里有一个特性是deepth first 只有先计算了最底层的a*b和c*d才能执行上一层的加法运算 只有执行完加法运算才能执行赋值运算
ILOC(intermidate language for optimizing compiler)编译器优化的中间语言
load a
r1
扫描二维码关注公众号,回复: 16308061 查看本文章
loadAI
, @a
//第一个行抽象汇编指令实际是第二行的简化 第二行才是抽象汇编指令的完整写法
//不过通常都会简写
A代表address地址 I代表immediate 立即的意思 loadAI合起来就是立即加载地址的意思代表activation record pointer 活动记录指针 @a代表offset偏移量

这里可以看到 一个活动记录 常称栈帧(stack frame)main函数中调用了f1函数 f1函数内部调用了f2 在f2中有变量a b c 其中就是0xff00 充当段寄存器的作用 而@a就是偏移量 起指令指针寄存器的作用
寄存器分配
假设我们有三个物理寄存器p1 p2 p3 要把所有的虚拟寄存器分配到物理寄存器上
首先先多加一个蓝色部分

显然 更长的生命周期对应着寄存器的压力也会更大
当去除掉最后一个行蓝色加深后
可以看出 后端的寄存器分配功能会尽量使用较少的寄存器去做运算 只有其他寄存器内的数据的生命周期都没结束才会使用新的寄存器
如果只有两个物理寄存器p1和p2那么情况又如何呢?

可以看出 当只有两个物理寄存器的时候 不能把每一个虚拟寄存器都映射到物理寄存器上 而是需要临时存入内存 这种情况英文中叫spill 就是溢出到内存中的意思 register allocation会尽可能的不去发生spill的情况