VGG模型是一个深度卷积神经网络,用于对图像进行分类和识别。它由英国牛津大学的研究人员所开发,是ImageNet竞赛中最重要的网络之一。VGG模型有多个版本,其中最常用的是VGG16和VGG19。这些模型具有深度和复杂的结构,可以处理复杂的视觉数据,准确性较高。学习VGG模型需要了解卷积神经网络的基础知识,例如卷积、池化和全连接层。
Simonyan, Karen, and Andrew Zisserman. “Very deep convolutional networks for large-scale image recognition.” arXiv preprint arXiv:1409.1556 (2014).
论文下载地址:https://arxiv.org/pdf/1409.1556.pdf
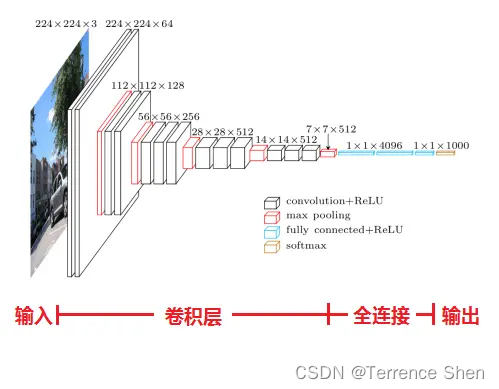
模型
由图可以看到,VGG由5层卷积层、3层全连接层、softmax输出层构成,层与层之间使用max-pooling(最大化池)分开,所有隐层的激活单元都采用ReLU函数。vgg的输入2242243大小的彩色图像,图像经过一系列卷积层处理,在卷积层中使用了非常小的33(图中用conv3表示)卷积核,在有些卷积层里则使用了11(图中用conv1表示)的卷积核。
VGGNet 可以看成是加深版本的 AlexNet,都是由卷积层、全连接层两大部分构成。
1、结构简洁
VGG 由 5 层卷积层、3 层全连接层、softmax 输出层构成,层与层之间使用 max-pooling(最大化池)分开,所有隐层的激活单元都采用 ReLU 函数。
2、小卷积核和多卷积子层
VGG 使用多个较小卷积核(3x3)的卷积层代替一个卷积核较大的卷积层,一方面可以减少参数,另一方面相当于进行了更多的非线性映射,可以增加网络的拟合 / 表达能力。
小卷积核是 VGG 的一个重要特点,虽然 VGG 是在模仿 AlexNet 的网络结构,但没有采用 AlexNet 中比较大的卷积核尺寸(如 7x7),而是通过降低卷积核的大小(3x3),增加卷积子层数来达到同样的性能(VGG:从 1 到 4 卷积子层,AlexNet:1 子层)。
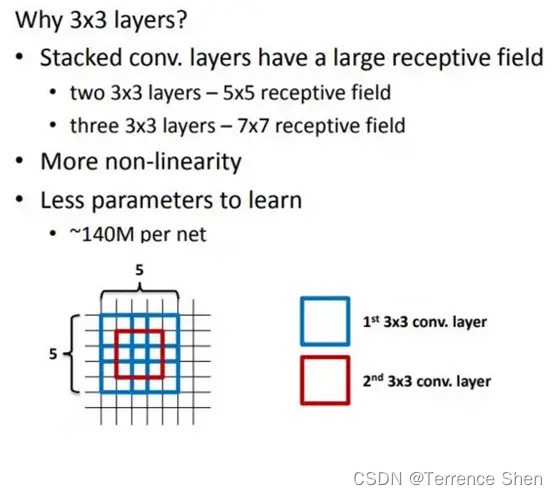
VGG 的作者认为两个 3x3 的卷积堆叠获得的感受野大小,相当一个 5x5 的卷积;而 3 个 3x3 卷积的堆叠获取到的感受野相当于一个 7x7 的卷积。这样可以增加非线性映射,也能很好地减少参数(例如 7x7 的参数为 49 个,而 3 个 3x3 的参数为 27),如下图所示:
3、小池化核
相比 AlexNet 的 3x3 的池化核,VGG 全部采用 2x2 的池化核。
4、通道数多
VGG 网络第一层的通道数为 64,后面每层都进行了翻倍,最多到 512 个通道,通道数的增加,使得更多的信息可以被提取出来。
5、层数更深、特征图更宽
由于卷积核专注于扩大通道数、池化专注于缩小宽和高,使得模型架构上更深更宽的同时,控制了计算量的增加规模。
6、全连接转卷积(测试阶段)
这也是 VGG 的一个特点,在网络测试阶段将训练阶段的三个全连接替换为三个卷积,使得测试得到的全卷积网络因为没有全连接的限制,因而可以接收任意宽或高为的输入,这在测试阶段很重要。
如本节第一个图所示,输入图像是 224x224x3,如果后面三个层都是全连接,那么在测试阶段就只能将测试的图像全部都要缩放大小到 224x224x3,才能符合后面全连接层的输入数量要求,这样就不便于测试工作的开展。
而 “全连接转卷积”,替换过程如下: