一般的文字识别会包含两个阶段,一个是CNN,一个是RNN,可以参考PaddleOCR使用指南 中的CRNN 文字识别。这种架构虽然准确,但复杂且LSTM的效率较低,很多移动设备对LSTM的加速效果并不好,所以在实际的应用场景中也存在诸多限制。随着swin transformer在计算机视觉领域大放光彩,swin的这种金字塔结构(像CNN里面的下采样一样)也被引入到文字识别。
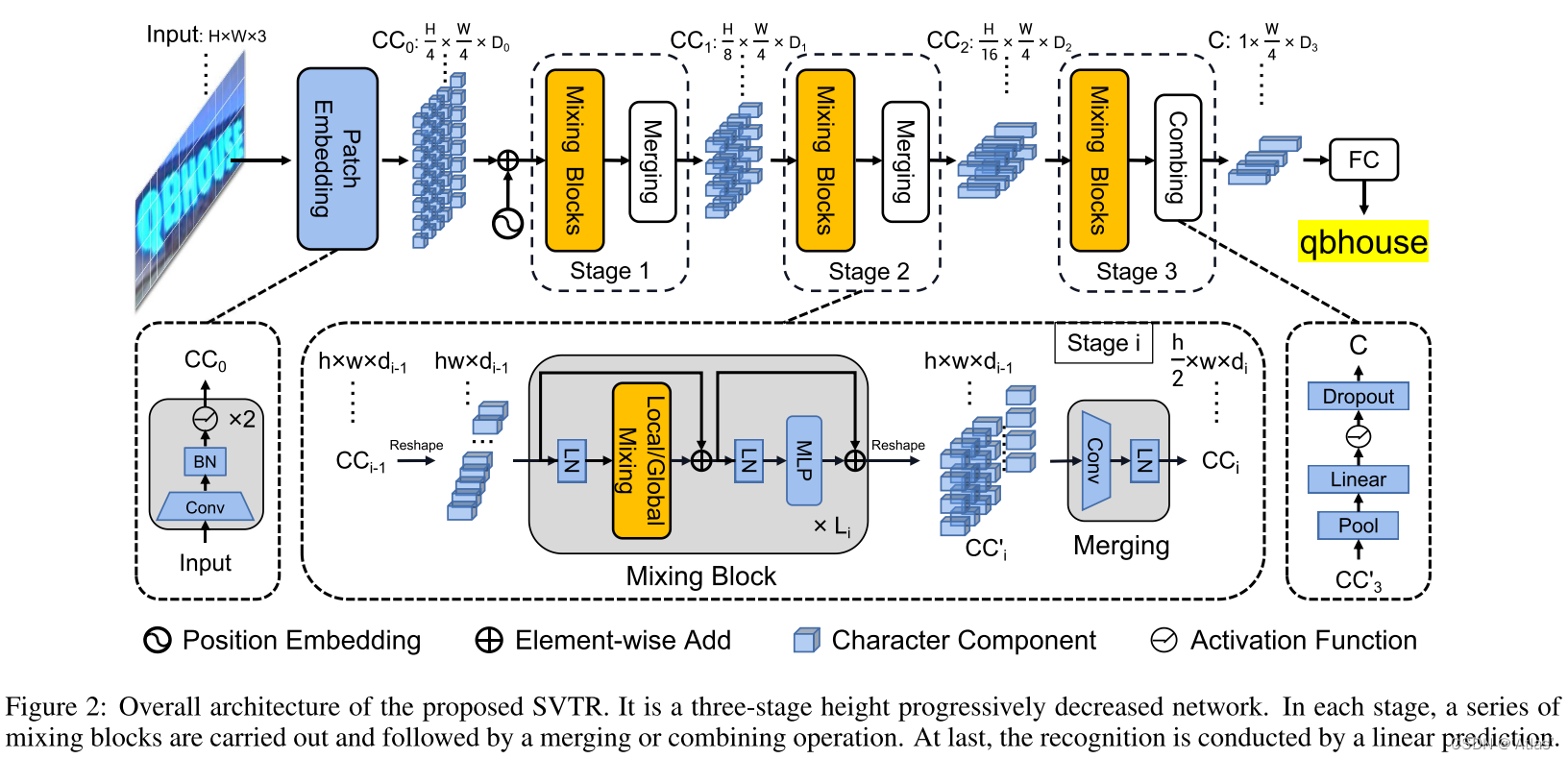
上图是SVTR的网络架构图,输入文本图像H*W*3,经过patch embedding模块,转换为(H/4)*(W/4)个维度为![]() 的patch。与Swim Transformer不同的是,SVTR的patch embedding并不是使用4*4的卷积核(步长也为4)进行4倍无重叠的下采样的,而是使用2个3*3的卷积核(步长为2)进行有重叠的4倍下采样(延续的CNN的作风,感受野更大,提取局部信息的表达能力也会比swin的patch embedding要好)。有关Swim Transformer的内容可以参考Swin Transformer介绍 。飞桨代码如下
的patch。与Swim Transformer不同的是,SVTR的patch embedding并不是使用4*4的卷积核(步长也为4)进行4倍无重叠的下采样的,而是使用2个3*3的卷积核(步长为2)进行有重叠的4倍下采样(延续的CNN的作风,感受野更大,提取局部信息的表达能力也会比swin的patch embedding要好)。有关Swim Transformer的内容可以参考Swin Transformer介绍 。飞桨代码如下
class PatchEmbed(nn.Layer):
def __init__(self,
img_size=[32, 100],
in_channels=3,
embed_dim=768,
sub_num=2):
super().__init__()
num_patches = (img_size[1] // (2 ** sub_num)) * \
(img_size[0] // (2 ** sub_num))
self.img_size = img_size
self.num_patches = num_patches
self.embed_dim = embed_dim
self.norm = None
if sub_num == 2:
self.proj = nn.Sequential(
ConvBNLayer(in_channels=in_channels,
out_channels=embed_dim // 2,
kernel_size=3,
stride=2,
padding=1,
act=nn.GELU,
bias_attr=None),
ConvBNLayer(
in_channels=embed_dim // 2,
out_channels=embed_dim,
kernel_size=3,
stride=2,
padding=1,
act=nn.GELU,
bias_attr=None))
def forward(self, x):
B, C, H, W = x.shape
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose((0, 2, 1))
return x
经过4倍下采样后是进入3个Stage的模块,第一、第二个Stage包含Mixing Block和Merging,第三个Stage包含Mixing Block和Combing。它们的作用跟CRNN一样都是对特征图的高度进行下采样,并最终下采样到1并保证宽度不变。

Mixing Block
由于两个字符可能略有不同,文本识别严重依赖于字符组件级别的特征。然而,现有的研究大多采用特征序列来表示图像文本。每个特征对应于一个切片图像区域,这通常是有噪声的,特别是对于不规则的文本。它不是描述这个角色的最佳方法。而vision transformer引入了二维特征表示,但如何在文本识别的背景下利用这种表示仍然值得研究。
更具体地说,对于embedded组件,作者认为文本识别需要两种特征。(1)第一个是局部组件模式,如类似笔画的特征。它编码了形态特征和特征不同部分之间的相关性;(2)第二种是字符间的依赖性,如不同字符之间或文本和非文本组件之间的相关性。
因此,作者设计了两个混合块(全局Mix和局部Mix),通过使用不同接收场的self-attention来感知上下文的相关性。
- Global Mixing
Global Mixing评估所有字符组件之间的依赖性。由于文本和非文本是图像中的两个主要元素,这种通用的Mixing可以建立来自不同字符的组件之间的长期依赖关系。此外,它还能削弱非文本成分的影响,同时提高文本成分的重要性。在数学上,对于上一阶段的字符组件CCi−1,它首先被reshape为一个特征序列。当进入Mixing block时,应用layer norm进行标准化,然后进行多头自注意获取其依赖关系。然后,依次应用LN和MLP进行特征融合。与同时引入跳跃连接,形成全局混合块。如下图所示:

Global Mixing本质上就是一个简单的自注意力机制,特征图经过线性变换投影到三个空间(三个头),然后q矩阵和k矩阵的转置进行矩阵乘法、softmax操作得到attention矩阵,最后和v矩阵进行矩阵乘法得到输出,具体多头注意力机制请参考深度学习网络模型的改进与调整 中的Transformer中的Self-Attention。飞桨代码如下
class Attention(nn.Layer):
def __init__(self,
dim,
num_heads=8,
mixer='Global',
HW=[8, 25],
local_k=[7, 11],
qkv_bias=False,
qk_scale=None,
attn_drop=0.,
proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim**-0.5
self.qkv = nn.Linear(dim, dim * 3, bias_attr=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.HW = HW
if HW is not None:
H = HW[0]
W = HW[1]
self.N = H * W
self.C = dim
if mixer == 'Local' and HW is not None:
hk = local_k[0]
wk = local_k[1]
mask = paddle.ones([H * W, H + hk - 1, W + wk - 1], dtype='float32')
for h in range(0, H):
for w in range(0, W):
mask[h * W + w, h:h + hk, w:w + wk] = 0.
mask_paddle = mask[:, hk // 2:H + hk // 2, wk // 2:W + wk //
2].flatten(1)
mask_inf = paddle.full([H * W, H * W], '-inf', dtype='float32')
mask = paddle.where(mask_paddle < 1, mask_paddle, mask_inf)
self.mask = mask.unsqueeze([0, 1])
self.mixer = mixer
def forward(self, x):
if self.HW is not None:
N = self.N
C = self.C
else:
_, N, C = x.shape
qkv = self.qkv(x).reshape((0, N, 3, self.num_heads, C //
self.num_heads)).transpose((2, 0, 3, 1, 4))
q, k, v = qkv[0] * self.scale, qkv[1], qkv[2]
attn = (q.matmul(k.transpose((0, 1, 3, 2))))
if self.mixer == 'Local':
attn += self.mask
attn = nn.functional.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
x = (attn.matmul(v)).transpose((0, 2, 1, 3)).reshape((0, N, C))
x = self.proj(x)
x = self.proj_drop(x)
return x
- Local Mixing

上图中的a其实就是对整个特征图进行局部化窗口的自注意力机制,而b中则是偏移窗口自注意力机制。Local mixing评估了预定义窗口内组件之间的相关性。其目的是对形态特征进行编码,并建立特征内成分之间的关联,从而模拟对特征识别至关重要的笔画样例特征。
与Global Mixing不同,Local mixing考虑的是每个分量都有一个邻域。与卷积类似,混合是以滑动窗口的方式进行。窗口大小根据经验设置为7×11。
与Global Mixing相比,它实现了自我注意机制来捕获局部模式。其实就是Swin transformer里面的那一套,将全局的self-attention转换为局部的self-attention来计算,只不过swin是为了减少计算量,而SVTR是为了获取更多的局部信息。
而且swin是通过reshape这种类似的方式来进行滑窗,并将不同的窗口累加到通道维度上,而SVTR则是直接使用值为0的mask操作。SVTR这种做法和swin相比,计算复杂度还是比较高。有关滑动窗口注意力机制可以参考Swin Transformer介绍 中的Shifted windows 技术。
通过Mixing之后就是多层感知机MLP,它们都有残差连接。
Merging
其实就是下采样操作,和卷积的下采样一样。因为self-attention的计算量和特征图的宽高有关,宽高太大的话,计算复杂度暴涨,具体可以参考Swin Transformer介绍 中的MSA 计算复杂度,所以SVTR对其进行了下采样操作,在低分辨率的特征图上计算可以减少矩阵乘法的计算复杂度。
Combing
在最后一个阶段,使用一个Combining进行维度的压缩。即:
if last_stage:
self.avg_pool = nn.AdaptiveAvgPool2D([1, out_char_num])
self.last_conv = nn.Conv2D(
in_channels=embed_dim[2],
out_channels=self.out_channels,
kernel_size=1,
stride=1,
padding=0,
bias_attr=False)
self.hardswish = nn.Hardswish()
self.dropout = nn.Dropout(p=last_drop, mode="downscale_in_infer")
- 首先将高度维度全局池化为1
- 然后是经过全连接层处理
- 字符被进一步压缩为一个特征序列
- 与CRNN中的合并操作相比,SVTR的合并操作可以避免对一维尺寸非常小的token进行卷积,例如对高度为2的token进行卷积。
- 利用组合特征,通过一个简单的并行线性预测来实现识别。具体地说,使用全连接层生成转录序列
- 理想情况下,相同字符被转录成重复的字符,非文本的组件被转录成一个空白符号。就是一个CTC解码模块。
但是,这种
nn.AdaptiveAvgPool2D([1, out_char_num])
的方法有局限性,得到的是一个[B,C,1, out_char_num]维度的输出,这样的话out_char_num就固定了,处理可变的输入图像不方便(图像字符很短,但是out_char_num很大,浪费算力;图像字符很长,out_char_num长度较短,无法完整表达图像中的字符)。
PaddleOCR V3中的SVTR模块
总的来看,整个结构其实就是通过self-attention和线性层完成视觉信息和序列信息的编码一步到位。也就是省掉了CRNN里面那个LSTM模块。但是,在PaddleOCR V3里面只使用了两层的self-attention,还是通过mobilenet提取视觉信息,self-attention进行序列信息转换,没有全部使用transformer模块,大概是为了减少计算复杂度
class EncoderWithSVTR(nn.Layer):
def __init__(
self,
in_channels,
dims=64, # XS
depth=2,
hidden_dims=120,
use_guide=False,
num_heads=8,
qkv_bias=True,
mlp_ratio=2.0,
drop_rate=0.1,
attn_drop_rate=0.1,
drop_path=0.,
qk_scale=None):
super(EncoderWithSVTR, self).__init__()
self.depth = depth
self.use_guide = use_guide
self.conv1 = ConvBNLayer(
in_channels, in_channels // 8, padding=1, act=nn.Swish)
self.conv2 = ConvBNLayer(
in_channels // 8, hidden_dims, kernel_size=1, act=nn.Swish)
self.svtr_block = nn.LayerList([
Block(
dim=hidden_dims,
num_heads=num_heads,
mixer='Global',
HW=None,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate,
act_layer=nn.Swish,
attn_drop=attn_drop_rate,
drop_path=drop_path,
norm_layer='nn.LayerNorm',
epsilon=1e-05,
prenorm=False) for i in range(depth)
])
self.norm = nn.LayerNorm(hidden_dims, epsilon=1e-6)
self.conv3 = ConvBNLayer(
hidden_dims, in_channels, kernel_size=1, act=nn.Swish)
# last conv-nxn, the input is concat of input tensor and conv3 output tensor
self.conv4 = ConvBNLayer(
2 * in_channels, in_channels // 8, padding=1, act=nn.Swish)
self.conv1x1 = ConvBNLayer(
in_channels // 8, dims, kernel_size=1, act=nn.Swish)
self.out_channels = dims
def forward(self, x):
# for use guide
if self.use_guide:
z = x.clone()
z.stop_gradient = True
else:
z = x
# for short cut
h = z
# reduce dim
z = self.conv1(z)
z = self.conv2(z)
# SVTR global block
B, C, H, W = z.shape
z = z.flatten(2).transpose([0, 2, 1])
for blk in self.svtr_block:
z = blk(z)
z = self.norm(
# last stage
z = z.reshape([0, H, W, C]).transpose([0, 3, 1, 2])
z = self.conv3(z)
z = paddle.concat((h, z), axis=1)
z = self.conv1x1(self.conv4(z))
return z
而且paddleocr v3也没有使用论文里面的AdaptiveAvgPool2D,而是使用卷积的方式,很好的解决了out_char_num问题。总的来看,paddleocr v3并未使用完整的SVTR,而是结合了CNN + self-attention,在保留轻量级结构设计的同时去掉了LSTM,替换为可以并行处理的self-attention。