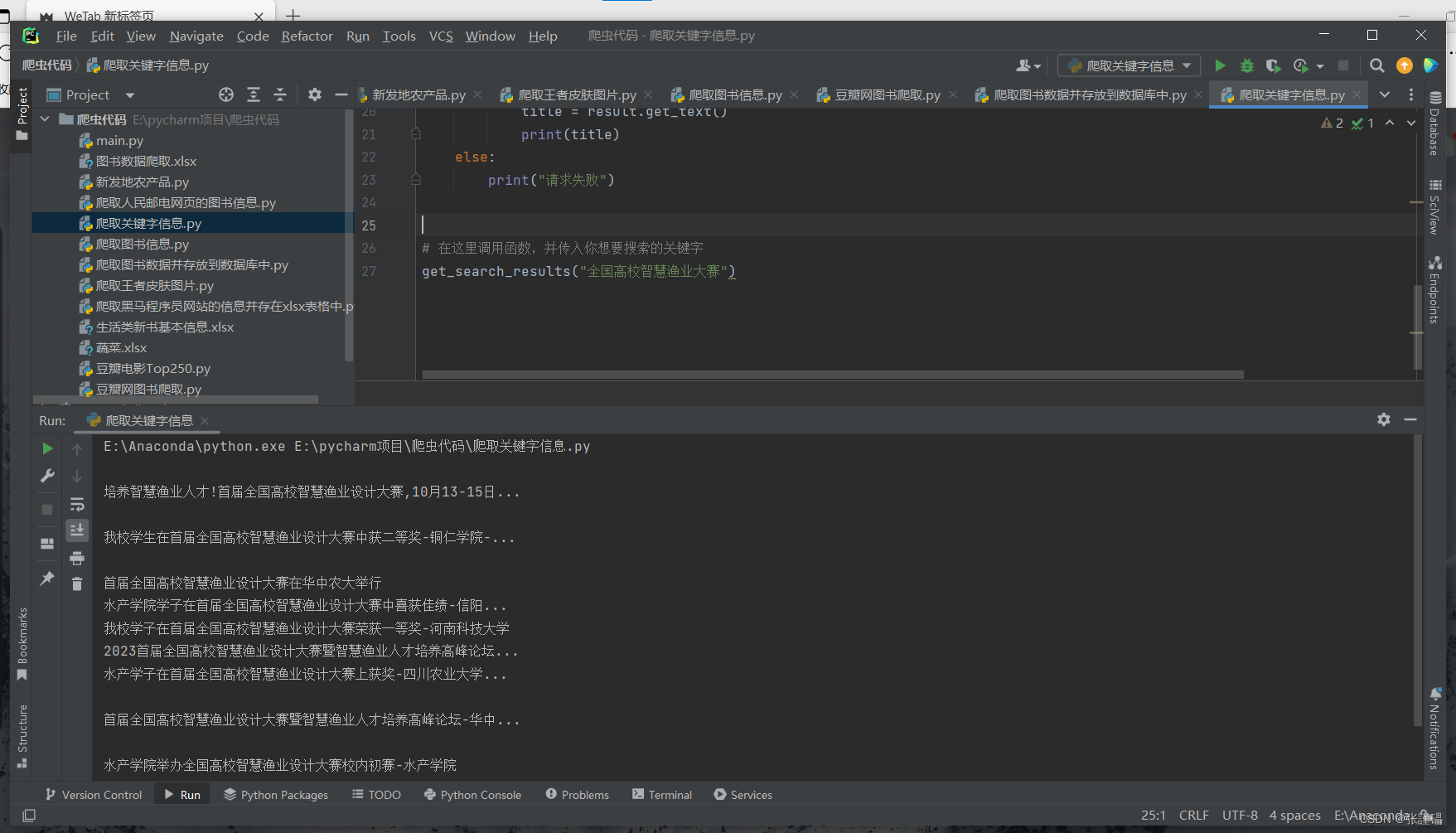
这段代码使用了requests库和BeautifulSoup库来获取并解析搜狗搜索结果页面中的标题信息。具体的步骤如下:
- 导入所需的库:requests和BeautifulSoup。
- 定义了一个函数
get_search_results(),用于获取关键字的搜索结果。 - 构造搜索关键字的URL,将关键字拼接到URL中。
- 设置请求头信息,包括User-Agent。
- 使用requests库的get()方法发送HTTP请求,并获取相应的内容。
- 检查响应状态码是否为200,如果是则表示请求成功,使用BeautifulSoup库解析响应的HTML文档。
- 使用find_all()方法查找所有具有"class"属性为"res-title"的"h3"标签元素,这些元素包含了搜索结果的标题。
- 遍历所有找到的标题元素,使用get_text()方法获取标题文本,并打印出来。
- 如果响应状态码不是200,则打印出"请求失败"的提示。
在代码的最后,调用get_search_results()函数并传入想要搜索的关键字,例如"全国高校智慧渔业大赛"。
请确保已经安装了所需的库(requests和BeautifulSoup),并根据需要适当修改代码中的请求头信息和关键字。
这段代码用于从搜狗搜索获取搜索结果页面中的标题信息。
- 导入库
import requests
from bs4 import BeautifulSoup
导入了需要使用的库 requests 和 BeautifulSoup。
- 定义获取搜索结果的函数
get_search_results(keyword)
def get_search_results(keyword):
url = f"https://www.so.com/s?q={keyword}"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
results = soup.find_all("h3", class_="res-title")
for result in results:
title = result.get_text()
print(title)
else:
print("请求失败")
这个函数接收一个关键字参数 keyword,用于指定搜索的关键字。在函数内部,根据关键字构建搜索结果页面的URL。然后,设置请求头信息,包括User-Agent。接下来,通过发送GET请求获取搜索结果页面的HTML内容。如果请求成功(状态码为200),使用BeautifulSoup解析HTML内容。使用 find_all() 方法找到所有具有 res-title 类名的 h3 标签,这些标签包含了搜索结果的标题信息。然后,遍历每个标题,使用 get_text() 方法获取标题文本,并打印出来。如果请求失败,输出提示信息。
- 调用函数并传入关键字
get_search_results("全国高校智慧渔业大赛")
在这部分代码中,调用了 get_search_results 函数,并传入关键字 “全国高校智慧渔业大赛”。这将输出搜索结果页面中的标题信息。
扫描二维码关注公众号,回复:
17185611 查看本文章

如果你还有其他问题,可以继续提问。
import requests
from bs4 import BeautifulSoup
def get_search_results(keyword):
url = f"https://www.so.com/s?q={keyword}"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
results = soup.find_all("h3", class_="res-title")
for result in results:
title = result.get_text()
print(title)
else:
print("请求失败")
# 在这里调用函数,并传入你想要搜索的关键字
get_search_results("全国高校智慧渔业大赛")