Python爬虫---爬取网络上的图片
什么是爬虫这个在这里就不多说了(毕竟有度娘),那么如何爬取网络上的图片呢?
这里以这个网站为例:http://www.ivsky.com/search.php?q=%E6%B5%B7&PageNo=10
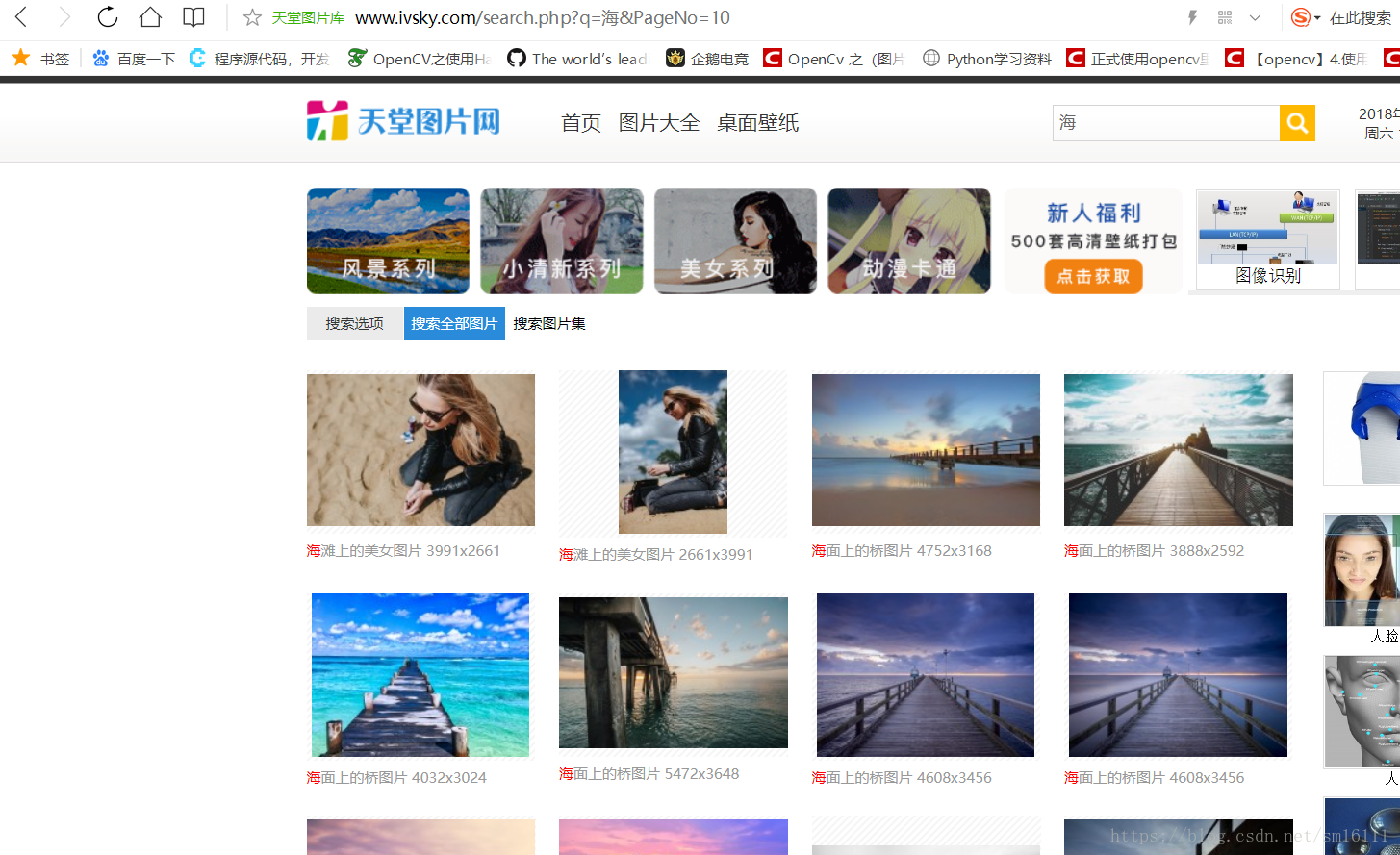
1、打开网站后点右键--》查看网页源代码
然后是不是发现了一些规律呢如下面的图片格式大都是.jpg alt 是图片的描述对吧。
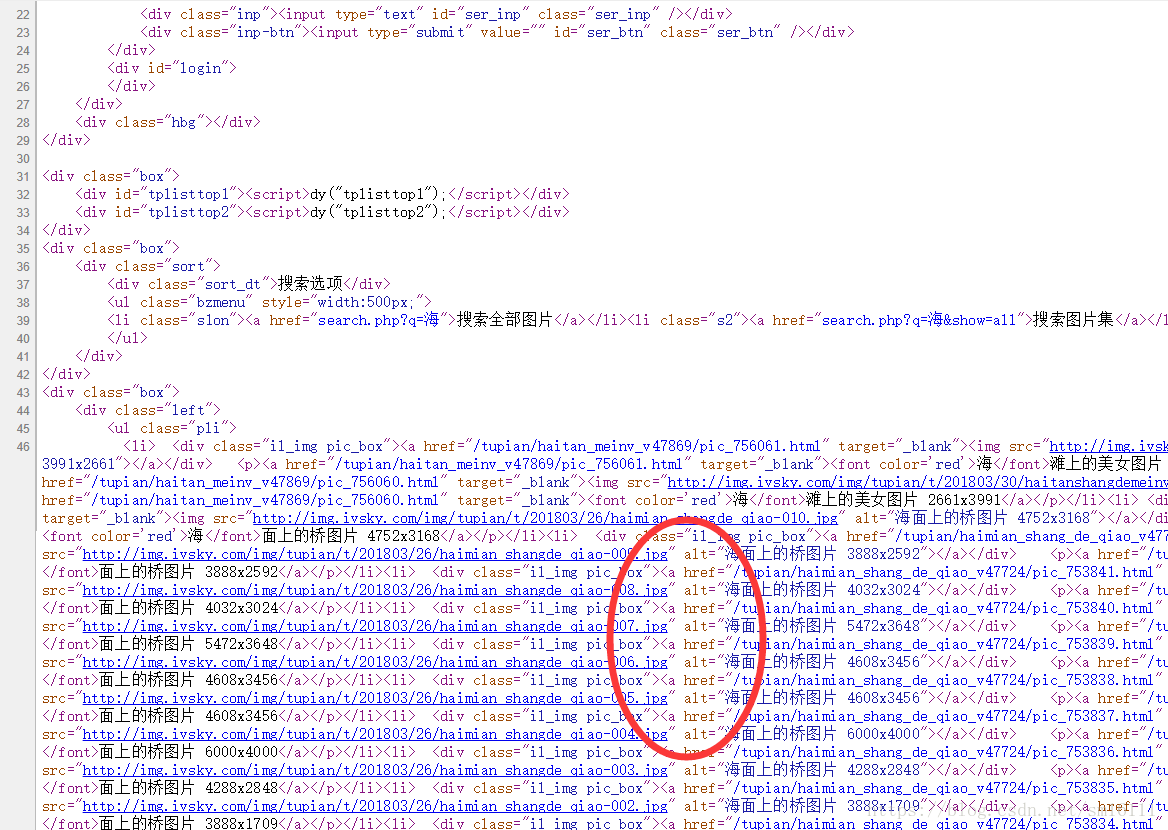
2、发现完这个规律那么我们就可以开始写代码啦 (用正则表达式来表示这个规律然后把网页是地址传进去就ok啦)
import urllib.request
import re
import urllib
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html.decode('UTF-8')
def getImg(html):
reg = r'src="(.+?\.jpg)" alt'
imgre = re.compile(reg)
imglist = imgre.findall(html)#表示在整个网页中过滤出所有图片的地址,放在imglist中
x =0
path = 'D:\\neg'
# 将图片保存到D:\\test文件夹中,如果没有test文件夹则创建
for imgurl in imglist:
urllib.request.urlretrieve(imgurl,'{}{}.jpg'.format(path,x)) #打开imglist中保存的图片网址,并下载图片保存在本地,format格式化字符串
x = x + 1
return imglist
html = getHtml("http://www.ivsky.com/search.php?q=%E6%B5%B7&PageNo=9")#获取该网址网页详细信息,得到的html就是网页的源代码
print (getImg(html)) #从网页源代码中分析并下载保存图片
print("hello 123456")
这样就爬取到这个网站上的图片啦~~~~~~~

