前言
常遇到两类朋友。一类是会爬虫但不知道如何进一步做数据分析的,一类是平常用 Excel 做分析但不太会用 Python 分析的。如果和你很像,那下面这篇系统长文会很适合你,建议先收藏。
Excel 是数据分析中最常用的工具,本文通过 Python 与 excel 的功能对比介绍如何使用 Python 通过函数式编程完成 excel 中的数据处理及分析工作。从 1787 页的 pandas 官网文档中总结出最常用的 36 个函数,通过这些函数介绍如何通过 Python 完成数据生成和导入、数据清洗、预处理、数据分类、数据筛选、分类 汇总、透视等最常见的操作。
文章内容共分为 9 个部分目录如下:

01 生成数据表
第一部分是生成数据表,常见的生成方法有两种,第一种是导入外部数据,第二种是直接写入数据。 Excel 中的文件菜单中提供了获取外部数据的功能,支持数据库和文本文件和页面的多种数据源导入。
文末给大家分享了Python零基础到入门的学习资料!感兴趣的自行领取
内容包含:
python百万字PDF教程,手把手助你从零进阶拿高薪(十一模块)
1.hello,初识python
2.python大数据技术体系
3.AI研发,快人一步
4.全栈开发体系,你不能错过的内容
5.掌握核心,python核心编程
6.python并发编程
7.python数据库编程
8.爬虫入门必学
9.python框架源码分析
10.爬虫必备JS逆向
11.多学一点,加薪更稳定Android逆向

python 支持从多种类型的数据导入。在开始使用 python 进行数据导入前需要先导入 pandas 库,为了方便起见,我们也同时导入 numpy 库。
1import numpy as np
2import pandas as pd
导入数据表
下面分别是从 excel 和 csv 格式文件导入数据并创建数据表的方法。代码是最简模式,里面有很多可选参数设置,例如列名称,索引列,数据格式等等。感兴趣的朋友可以参考 pandas 的
官方文档。
1df=pd.DataFrame(pd.read_csv('name.csv',header=1))
2df=pd.DataFrame(pd.read_excel('name.xlsx'))
创建数据表
另一种方法是通过直接写入数据来生成数据表,excel 中直接在单元格中输入数据就可以,python 中通过下面的代码来实现。生成数据表的函数是 pandas 库中的 DateFrame 函数,数据表一共有 6 行数据,每行有 6 个字段。在数据中我们特意设置了一些 NA 值和有问题的字段,例如包含空格等。后面将在数据清洗步骤进行处理。后面我们将统一以 DataFrame 的简称 df 来命名数据表。
1df = pd.DataFrame({"id":[1001,1002,1003,1004,1005,1006],
2 "date":pd.date_range('20130102', periods=6),
3 "city":['Beijing ', 'SH', ' guangzhou ', 'Shenzhen', 'shanghai', 'BEIJING '],
4 "age":[23,44,54,32,34,32],
5 "category":['100-A','100-B','110-A','110-C','210-A','130-F'],
6 "price":[1200,np.nan,2133,5433,np.nan,4432]},
7 columns =['id','date','city','category','age','price'])
这是刚刚创建的数据表,我们没有设置索引列,price 字段中包含有 NA 值,city 字段中还包含了一些脏数据。

02 数据表检查
第二部分是对数据表进行检查,python 中处理的数据量通常会比较大,比如我们之前的文章中介绍的纽约出租车数据和 Citibike 的骑行数据,数据量都在千万级,我们无法一目了然的 了解数据表的整体情况,必须要通过一些方法来获得数据表的关键信息。数据表检查的另一个目的是了解数据的概况,例如整个数据表的大小,所占空间,数据格式,是否有空值和重复项和具体的数据内容。为后面的清洗和预处理做好准备。
数据维度(行列)
Excel 中可以通过 CTRL+向下的光标键,和 CTRL+向右的光标键来查看行号和列号。Python 中使用 shape 函数来查看数据表的维度,也就是行数和列数,函数返回的结果(6,6)表示数据表有 6 行,6 列。下面是具体的代码。
1#查看数据表的维度
2df.shape
3(6, 6)
数据表信息
使用 info 函数查看数据表的整体信息,这里返回的信息比较多,包括数据维度,列名称,数据格式和所占空间等信息。
#数据表信息
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6 entries, 0 to 5
Data columns (total 6 columns):
id 6 non-null int64
date 6 non-null datetime64[ns]
city 6 non-null object
category 6 non-null object
age 6 non-null int64
price 4 non-null float64
dtypes: datetime64[ns](1), float64(1), int64(2), object(2memory usage: 368.0+ bytes
查看数据格式
Excel 中通过选中单元格并查看开始菜单中的数值类型来判断数据的格式。Python 中使用 dtypes 函数来返回数据格式。

Dtypes 是一个查看数据格式的函数,可以一次性查看数据表中所有数据的格式,也可以指定一列来单独查看。
#查看数据表各列格式
df.dtypes
id int64
date datetime64[ns]
city object
category object
age int64
price float64
dtype: object
#查看单列格式
df['B'].dtype
dtype('int64')
查看空值
Excel 中查看空值的方法是使用“定位条件”功能对数据表中的空值进行定位。“定位条件”在“开始”目录下的“查找和选择”目录中。

Isnull 是 Python 中检验空值的函数,返回的结果是逻辑值,包含空值返回 True,不包含则返回 False。可以对整个数据表进行检查,也可以单独对某一列进行空值检查。
#检查数据空值
df.isnull()
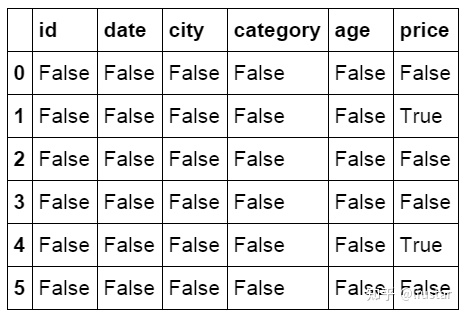
#检查特定列空值
df['price'].isnull()
0 False
1 True
2 False
3 False
4 True
5 False
Name: price, dtype: bool
查看唯一值
Excel 中查看唯一值的方法是使用“条件格式”对唯一值进行颜色标记。Python 中使用 unique 函数查看唯一值。
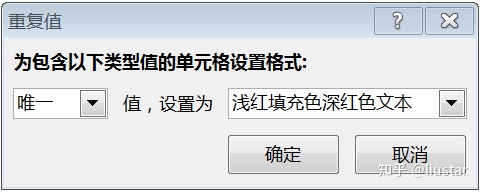
Unique 是查看唯一值的函数,只能对数据表中的特定列进行检查。下面是代码,返回的结果是该列中的唯一值。类似与 Excel 中删除重复项后的结果。
#查看 city 列中的唯一值
df['city'].unique()
array(['Beijing ', 'SH', ' guangzhou ', 'Shenzhen', 'shanghai', 'BEIJING '], dtype=object)
查看数据表数值
Python 中的 Values 函数用来查看数据表中的数值。以数组的形式返回,不包含表头信息。
#查看数据表的值
df.values
array([[1001, Timestamp('2013-01-02 00:00:00'), 'Beijing ', '100-A', 23,
1200.0],
[1002, Timestamp('2013-01-03 00:00:00'), 'SH', '100-B', 44, nan],
[1003, Timestamp('2013-01-04 00:00:00'), ' guangzhou ', '110-A', 54,
2133.0],
[1004, Timestamp('2013-01-05 00:00:00'), 'Shenzhen', '110-C', 32,
5433.0],
[1005, Timestamp('2013-01-06 00:00:00'), 'shanghai', '210-A', 34,
nan],
[1006, Timestamp('2013-01-07 00:00:00'), 'BEIJING ', '130-F', 32,
4432.0]], dtype=object)
查看列名称
Colums 函数用来单独查看数据表中的列名称。
#查看列名称
df.columns
Index(['id', 'date', 'city', 'category', 'age', 'price'], dtype='object')
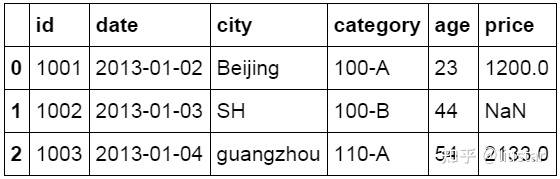
查看前 10 行数据
Head 函数用来查看数据表中的前 N 行数据,默认 head()显示前 10 行数据,可以自己设置参数值来确定查看的行数。下面的代码中设置查看前 3 行的数据。
`#查看前 3 行数据``df.head(``3``)`
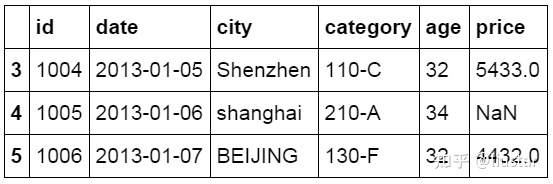
查看后 10 行数据
Tail 行数与 head 函数相反,用来查看数据表中后 N 行的数据,默认 tail()显示后 10 行数据,可以自己设置参数值来确定查看的行数。下面的代码中设置查看后 3 行的数据。
`#查看最后 3 行``df.tail(``3``)`
03 数据表清洗
第三部分是对数据表中的问题进行清洗。主要内容包括对空值,大小写问题,数据格式和重复值的处理。这里不包含对数据间的逻辑验证。
处理空值(删除或填充)
我们在创建数据表的时候在 price 字段中故意设置了几个 NA 值。对于空值的处理方式有很多种,可以直接删除包含空值的数据,也可以对空值进行填充,比如用 0 填充或者用均值填充。还可以根据不同字段的逻辑对空值进行推算。
Excel 中可以通过“查找和替换”功能对空值进行处理,将空值统一替换为 0 或均值。也可以通过“定位”空值来实现。

Python 中处理空值的方法比较灵活,可以使用 Dropna 函数用来删除数据表中包含空值的数据,也可以使用 fillna 函数对空值进行填充。下面的代码和结果中可以看到使用 dropna 函数后,包含 NA 值的两个字段已经不见了。返回的是一个不包含空值的数据表。
#删除数据表中含有空值的行
df.dropna(how='any')
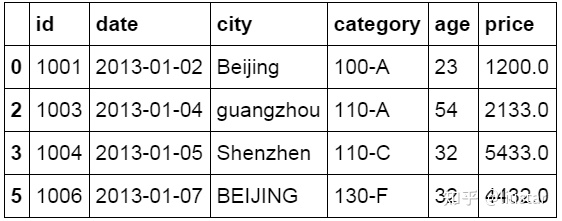
除此之外也可以使用数字对空值进行填充,下面的代码使用 fillna 函数对空值字段填充数字 0。
#使用数字 0 填充数据表中空值
df.fillna(value=0)
我们选择填充的方式来处理空值,使用 price 列的均值来填充 NA 字段,同样使用 fillna 函数,在要填充的数值中使用 mean 函数先计算 price 列当前的均值,然后使用这个均值对 NA 进行填
充。可以看到两个空值字段显示为 3299.5
#使用 price 均值对 NA 进行填充
df['price'].fillna(df['price'].mean())
0 1200.0
1 3299.5
2 2133.0
3 5433.0
4 3299.5
5 4432.0
Name: price, dtype: float64

清理空格
除了空值,字符中的空格也是数据清洗中一个常见的问题,下面是清除字符中空格的代码。
#清除 city 字段中的字符空格
df['city']=df['city'].map(str.strip)
大小写转换
在英文字段中,字母的大小写不统一也是一个常见的问题。Excel 中有 UPPER,LOWER 等函数,python 中也有同名函数用来解决大小写的问题。在数据表的 city 列中就存在这样的问题。我们将 city 列的所有字母转换为小写。下面是具体的代码和结果。
#city 列大小写转换
df['city']=df['city'].str.lower()

更改数据格式
Excel 中通过“设置单元格格式”功能可以修改数据格式。Python 中通过 astype 函数用来修改数据格式。

Python 中 dtype 是查看数据格式的函数,与之对应的是 astype 函数,用来更改数据格式。下面的代码中将 price 字段的值修改为 int 格式。
#更改数据格式
df['price'].astype('int')
0 1200
1 3299
2 2133
3 5433
4 3299
5 4432
Name: price, dtype: int32
更改列名称
Rename 是更改列名称的函数,我们将来数据表中的 category 列更改为 category-size。下面是具体的代码和更改后的结果。
#更改列名称
df.rename(columns={'category': 'category-size'})

删除重复值
很多数据表中还包含重复值的问题,Excel 的数据目录下有“删除重复项”的功能,可以用来删除数据表中的重复值。默认 Excel 会保留最先出现的数据,删除后面重复出现的数据。

Python 中使用 drop_duplicates 函数删除重复值。我们以数据表中的 city 列为例,city 字段中存在重复值。默认情况下 drop_duplicates()将删除后出现的重复值(与 excel 逻辑一致)。增加 keep=’last’参数后将删除最先出现的重复值,保留最后的值。下面是具体的代码和比较结果。
原始的 city 列中 beijing 存在重复,分别在第一位和最后一位。
df['city']
0 beijing
1 sh
2 guangzhou
3 shenzhen
4 shanghai
5 beijing
Name: city, dtype: object
使用默认的 drop_duplicates()函数删除重复值,从结果中可以看到第一位的 beijing 被保留,最后出现的 beijing 被删除。
#删除后出现的重复值
df['city'].drop_duplicates()
0 beijing
1 sh
2 guangzhou
3 shenzhen
4 shanghai
Name: city, dtype: object
设置 keep=’last‘’参数后,与之前删除重复值的结果相反,第一位出现的 beijing 被删除,保留了最后一位出现的 beijing。
#删除先出现的重复值
df['city'].drop_duplicates(keep='last')
1 sh
2 guangzhou
3 shenzhen
4 shanghai
5 beijing
Name: city, dtype: objec
数值修改及替换
数据清洗中最后一个问题是数值修改或替换,Excel 中使用“查找和替换”功能就可以实现数值的替换。
Python 中使用 replace 函数实现数据替换。数据表中 city 字段上海存在两种写法,分别为 shanghai 和 SH。我们使用 replace 函数对 SH 进行替换。
1#数据替换
2df['city'].replace('sh', 'shanghai')
30 beijing
41 shanghai
52 guangzhou
63 shenzhen
74 shanghai
85 beijing
9Name: city, dtype: object
本篇文章这是系列的第二篇,介绍第 4-6 部分的内容,数据表生成,数据表查看,和数据清洗。

04 数据预处理
第四部分是数据的预处理,对清洗完的数据进行整理以便后期的统计和分析工作。主要包括数据表的合并,排序,数值分列,数据分
组及标记等工作。
数据表合并
首先是对不同的数据表进行合并,我们这里创建一个新的数据表 df1,并将 df 和 df1 两个数据表进行合并。在 Excel 中没有直接完成数据表合并的功能,可以通过 VLOOKUP 函数分步实现。在 python 中可以通过 merge 函数一次性实现。下面建立 df1 数据表,用于和 df 数据表进行合并。
1#创建 df1 数据表
2df1=pd.DataFrame({"id":[1001,1002,1003,1004,1005,1006,1007,1008],
3"gender":['male','female','male','female','male','female','male','female'],
4"pay":['Y','N','Y','Y','N','Y','N','Y',],
5"m-point":[10,12,20,40,40,40,30,20]})
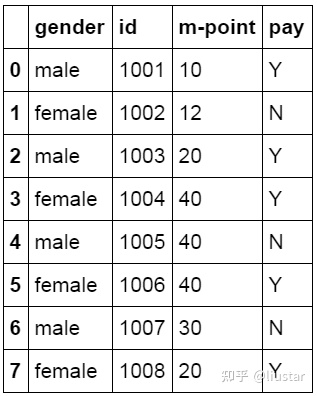
使用 merge 函数对两个数据表进行合并,合并的方式为 inner,将两个数据表中共有的数据匹配到一起生成新的数据表。并命名为 df_inner。
1#数据表匹配合并,inner 模式
2df_inner=pd.merge(df,df1,how='inner')

除了 inner 方式以外,合并的方式还有 left,right 和 outer 方式。这几种方式的差别在我其他的文章中有详细的说明和对比。
1#其他数据表匹配模式
2df_left=pd.merge(df,df1,how='left')
3df_right=pd.merge(df,df1,how='right')
4df_outer=pd.merge(df,df1,how='outer')
设置索引列
完成数据表的合并后,我们对 df_inner 数据表设置索引列,索引列的功能很多,可以进行数据提取,汇总,也可以进行数据筛选等。
设置索引的函数为 set_index。
1#设置索引列
2df_inner.set_index('id')

排序(按索引,按数值)
Excel 中可以通过数据目录下的排序按钮直接对数据表进行排序,比较简单。Python 中需要使用 ort_values 函数和 sort_index 函数完成排序。

在 python 中,既可以按索引对数据表进行排序,也可以看制定列的数值进行排序。首先我们按 age 列中用户的年龄对数据表进行排序。
使用的函数为 sort_values。
1#按特定列的值排序
2df_inner.sort_values(by=['age'])

Sort_index 函数用来将数据表按索引列的值进行排序。
1#按索引列排序
2df_inner.sort_index()

数据分组
Excel 中可以通过 VLOOKUP 函数进行近似匹配来完成对数值的分组,或者使用“数据透视表”来完成分组。相应的 python 中使用 where 函数完成数据分组。
Where 函数用来对数据进行判断和分组,下面的代码中我们对 price 列的值进行判断,将符合条件的分为一组,不符合条件的分为另一组,并使用 group 字段进行标记。
1#如果 price 列的值>3000,group 列显示 high,否则显示 low
2df_inner['group'] = np.where(df_inner['price'] > 3000,'high','low')

除了 where 函数以外,还可以对多个字段的值进行判断后对数据进行分组,下面的代码中对 city 列等于 beijing 并且 price 列大于等于 4000 的数据标记为 1。
1#对复合多个条件的数据进行分组标记
2df_inner.loc[(df_inner['city'] == 'beijing') & (df_inner['price'] >= 4000), 'sign']=1

数据分列
与数据分组相反的是对数值进行分列,Excel 中的数据目录下提供“分列”功能。在 python 中使用 split 函数实现分列。

在数据表中 category 列中的数据包含有两个信息,前面的数字为类别 id,后面的字母为 size 值。中间以连字符进行连接。我们使用 split 函数对这个字段进行拆分,并将拆分后的数据表匹配回原数据表中。
1#对 category 字段的值依次进行分列,并创建数据表,索引值为 df_inner 的索引列,列名称为 category 和 size
2pd.DataFrame((x.split('-') for x in df_inner['category']),index=df_inner.index,columns=['category','size'])
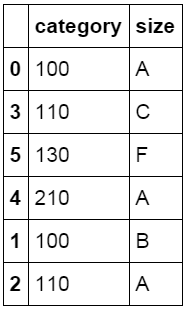
1#将完成分列后的数据表与原 df_inner 数据表进行匹配
2df_inner=pd.merge(df_inner,split,right_index=True, left_index=True)

05 数据提取
第五部分是数据提取,也是数据分析中最常见的一个工作。这部分主要使用三个函数,loc,iloc 和 ix,loc 函数按标签值进行提取,iloc 按位置进行提取,ix 可以同时按标签和位置进行提取。下面介绍每一种函数的使用方法。
按标签提取(loc)
Loc 函数按数据表的索引标签进行提取,下面的代码中提取了索引列为 3 的单条数据。
1#按索引提取单行的数值
2df_inner.loc[3]
3id 1004
4date 2013-01-05 00:00:00
5city shenzhen
6category 110-C
7age 32
8price 5433
9gender female
10m-point 40
11pay Y
12group high
13sign NaN
14category_1 110
15size C
16Name: 3, dtype: object
使用冒号可以限定提取数据的范围,冒号前面为开始的标签值,后面为结束的标签值。下面提取了 0 到 5 的数据行。
1#按索引提取区域行数值
2df_inner.loc[0:5]

Reset_index 函数用于恢复索引,这里我们重新将 date 字段的日期设置为数据表的索引,并按日期进行数据提取。
1#重设索引
2df_inner.reset_index()

1#设置日期为索引
2df_inner=df_inner.set_index('date')

使用冒号限定提取数据的范围,冒号前面为空表示从 0 开始。提取所有 2013 年 1 月 4 日以前的数据。
1#提取 4 日之前的所有数据
2df_inner[:'2013-01-04']

按位置提取(iloc)
使用 iloc 函数按位置对数据表中的数据进行提取,这里冒号前后的数字不再是索引的标签名称,而是数据所在的位置,从 0 开始。
1#使用 iloc 按位置区域提取数据
2df_inner.iloc[:3,:2]
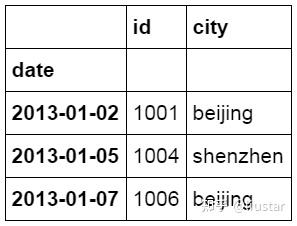
iloc 函数除了可以按区域提取数据,还可以按位置逐条提取,前面方括号中的 0,2,5 表示数据所在行的位置,后面方括号中的数表示所在列的位置。
1#使用 iloc 按位置单独提取数据
2df_inner.iloc[[0,2,5],[4,5]]

按标签和位置提取(ix)
ix 是 loc 和 iloc 的混合,既能按索引标签提取,也能按位置进行数据提取。下面代码中行的位置按索引日期设置,列按位置设置。
1#使用 ix 按索引标签和位置混合提取数据
2df_inner.ix[:'2013-01-03',:4]
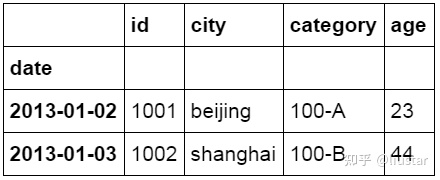
按条件提取(区域和条件值)
除了按标签和位置提起数据以外,还可以按具体的条件进行数据。下面使用 loc 和 isin 两个函数配合使用,按指定条件对数据进行提取 。
使用 isin 函数对 city 中的值是否为 beijing 进行判断。
1#判断 city 列的值是否为 beijing
2df_inner['city'].isin(['beijing'])
3
4date
52013-01-02 True
62013-01-05 False
72013-01-07 True
82013-01-06 False
92013-01-03 False
102013-01-04 False
11Name: city, dtype: bool
将 isin 函数嵌套到 loc 的数据提取函数中,将判断结果为 Ture 数据提取出来。这里我们把判断条件改为 city 值是否为 beijing 和 shanghai。如果是就把这条数据提取出来。
1#先判断 city 列里是否包含 beijing 和 shanghai,然后将复合条件的数据提取出来。
2df_inner.loc[df_inner['city'].isin(['beijing','shanghai'])]

数值提取还可以完成类似数据分列的工作,从合并的数值中提取出制定的数值。
1category=df_inner['category']
20 100-A
33 110-C
45 130-F
54 210-A
61 100-B
72 110-A
8Name: category, dtype: object
9
10#提取前三个字符,并生成数据表
11pd.DataFrame(category.str[:3])

06 数据筛选
第六部分为数据筛选,使用与,或,非三个条件配合大于,小于和等于对数据进行筛选,并进行计数和求和。与 excel 中的筛选功能和 countifs 和 sumifs 功能相似。
按条件筛选(与,或,非)
Excel 数据目录下提供了“筛选”功能,用于对数据表按不同的条件进行筛选。Python 中使用 loc 函数配合筛选条件来完成筛选功能。配合 sum 和 count 函数还能实现 excel 中 sumif 和 countif 函数的功能。

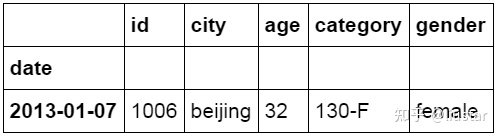
使用“与”条件进行筛选,条件是年龄大于 25 岁,并且城市为 beijing。筛选后只有一条数据符合要求。
1#使用“与”条件进行筛选
2df_inner.loc[(df_inner['age'] > 25) & (df_inner['city'] == 'beijing'), ['id','city','age','category','gender']]
使用“或”条件进行筛选,年龄大于 25 岁或城市为 beijing。筛选后有 6 条数据符合要求。
1#使用“或”条件筛选
2df_inner.loc[(df_inner['age'] > 25) | (df_inner['city'] == 'beijing'), ['id','city','age','category','gender']].sort
3(['age'])

在前面的代码后增加 price 字段以及 sum 函数,按筛选后的结果将 price 字段值进行求和,相当于 excel 中 sumifs 的功能。
1#对筛选后的数据按 price 字段进行求和
2df_inner.loc[(df_inner['age'] > 25) | (df_inner['city'] == 'beijing'),
3['id','city','age','category','gender','price']].sort(['age']).price.sum()
4
519796
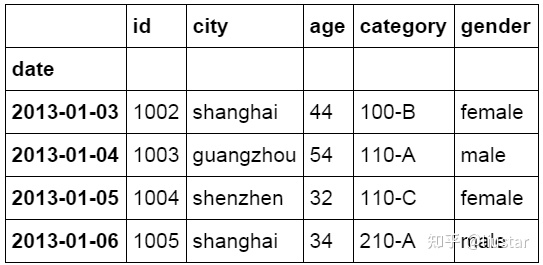
使用“非”条件进行筛选,城市不等于 beijing。符合条件的数据有 4 条。将筛选结果按 id 列进行排序。
1#使用“非”条件进行筛选
2df_inner.loc[(df_inner['city'] != 'beijing'), ['id','city','age','category','gender']].sort(['id'])
在前面的代码后面增加 city 列,并使用 count 函数进行计数。相当于 excel 中的 countifs 函数的功能。
1#对筛选后的数据按 city 列进行计数
2df_inner.loc[(df_inner['city'] != 'beijing'), ['id','city','age','category','gender']].sort(['id']).city.count()
34
还有一种筛选的方式是用 query 函数。下面是具体的代码和筛选结果。
1#使用 query 函数进行筛选
2df_inner.query('city == ["beijing", "shanghai"]')

在前面的代码后增加 price 字段和 sum 函数。对筛选后的 price 字段进行求和,相当于 excel 中的 sumifs 函数的功能。
1#对筛选后的结果按 price 进行求和
2df_inner.query('city == ["beijing", "shanghai"]').price.sum()
312230
这是第三篇,介绍第 7-9 部分的内容,数据汇总,数据统计,和数据输出。

07 数据汇总
第七部分是对数据进行分类汇总,Excel 中使用分类汇总和数据透视可以按特定维度对数据进行汇总,python 中使用的主要函数是 groupby 和 pivot_table。下面分别介绍这两个函数的使用方法。
分类汇总
Excel 的数据目录下提供了“分类汇总”功能,可以按指定的字段和汇总方式对数据表进行汇总。Python 中通过 Groupby 函数完成相应的操作,并可以支持多级分类汇总。
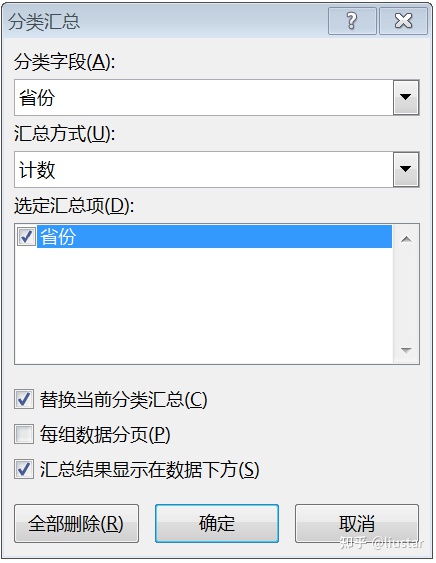
Groupby 是进行分类汇总的函数,使用方法很简单,制定要分组的列名称就可以,也可以同时制定多个列名称,groupby 按列名称出现的顺序进行分组。同时要制定分组后的汇总方式,常见的是计数和求和两种。
1#对所有列进行计数汇总
2df_inner.groupby('city').count()
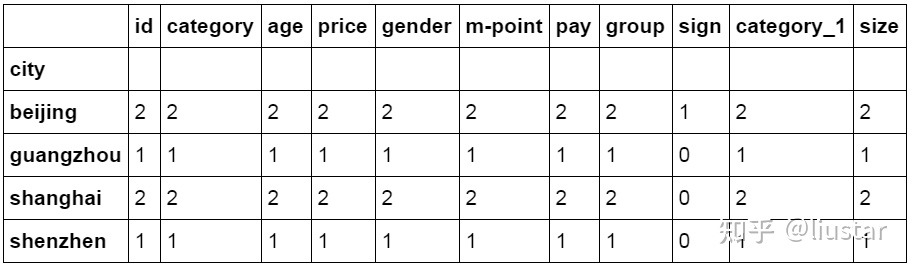
可以在 groupby 中设置列名称来对特定的列进行汇总。下面的代码中按城市对 id 字段进行汇总计数。
1#对特定的 ID 列进行计数汇总
2df_inner.groupby('city')['id'].count()
3city
4beijing 2
5guangzhou 1
6shanghai 2
7shenzhen 1
8Name: id, dtype: int64
在前面的基础上增加第二个列名称,分布对 city 和 size 两个字段进行计数汇总。
1#对两个字段进行汇总计数
2df_inner.groupby(['city','size'])['id'].count()
3city size
4beijing A 1
5F 1
6guangzhou A 1
7shanghai A 1
8B 1
9shenzhen C 1
10Name: id, dtype: int64
除了计数和求和外,还可以对汇总后的数据同时按多个维度进行计算,下面的代码中按城市对 price 字段进行汇总,并分别计算 price 的数量,总金额和平均金额。
1#对 city 字段进行汇总并计算 price 的合计和均值。
2df_inner.groupby('city')['price'].agg([len,np.sum, np.mean])
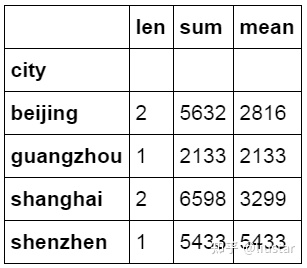
数据透视
Excel 中的插入目录下提供“数据透视表”功能对数据表按特定维度进行汇总。Python 中也提供了数据透视表功能。通过 pivot_table 函数实现同样的效果。
数据透视表也是常用的一种数据分类汇总方式,并且功能上比 groupby 要强大一些。下面的代码中设定 city 为行字段,size 为列字段,price 为值字段。分别计算 price 的数量和金额并且按行与列进行汇总。
1#数据透视表
2pd.pivot_table(df_inner,index=["city"],values=["price"],columns=["size"],aggfunc=[len,np.sum],fill_value=0,margins=True)

08 数据统计
第九部分为数据统计,这里主要介绍数据采样,标准差,协方差和相关系数的使用方法。
数据采样
Excel 的数据分析功能中提供了数据抽样的功能,如下图所示。Python 通过 sample 函数完成数据采样。

Sample 是进行数据采样的函数,设置 n 的数量就可以了。函数自动返回参与的结果。
1#简单的数据采样
2df_inner.sample(n=3)

Weights 参数是采样的权重,通过设置不同的权重可以更改采样的结果,权重高的数据将更有希望被选中。这里手动设置 6 条数据的权重值。将前面 4 个设置为 0,后面两个分别设置为 0.5。
1#手动设置采样权重
2weights = [0, 0, 0, 0, 0.5, 0.5]
3df_inner.sample(n=2, weights=weights)

从采样结果中可以看出,后两条权重高的数据被选中。

Sample 函数中还有一个参数 replace,用来设置采样后是否放回。
1#采样后不放回
2df_inner.sample(n=6, replace=False)

1#采样后放回
2df_inner.sample(n=6, replace=True)

描述统计
Excel 中的数据分析中提供了描述统计的功能。Python 中可以通过 Describe 对数据进行描述统计。

Describe 函数是进行描述统计的函数,自动生成数据的数量,均值,标准差等数据。下面的代码中对数据表进行描述统计,并使用 round 函数设置结果显示的小数位。并对结果数据进行转置。
1#数据表描述性统计
2df_inner.describe().round(2).T

标准差
Python 中的 Std 函数用来接算特定数据列的标准差。
1#标准差
2df_inner['price'].std()
31523.3516556155596
协方差
Excel 中的数据分析功能中提供协方差的计算,python 中通过 cov 函数计算两个字段或数据表中各字段间的协方差。

Cov 函数用来计算两个字段间的协方差,可以只对特定字段进行计算,也可以对整个数据表中各个列之间进行计算。
1#两个字段间的协方差
2df_inner['price'].cov(df_inner['m-point'])
317263.200000000001

相关分析
Excel 的数据分析功能中提供了相关系数的计算功能,python 中则通过 corr 函数完成相关分析的操作,并返回相关系数。
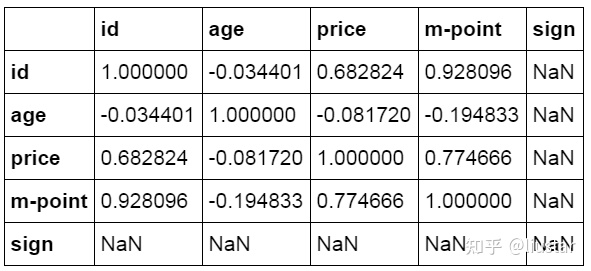
Corr 函数用来计算数据间的相关系数,可以单独对特定数据进行计算,也可以对整个数据表中各个列进行计算。相关系数在-1 到 1 之间,接近 1 为正相关,接近-1 为负相关,0 为不相关。
1#相关性分析
2df_inner['price'].corr(df_inner['m-point'])
30.77466555617085264
4
5#数据表相关性分析
6df_inner.corr()
09 数据输出
第九部分是数据输出,处理和分析完的数据可以输出为 xlsx 格式和 csv 格式。
写入 excel
1#输出到 excel 格式
2df_inner.to_excel('excel_to_python.xlsx', sheet_name='bluewhale_cc')

写入 csv
1#输出到 CSV 格式
2df_inner.to_csv('excel_to_python.csv')
在数据处理的过程中,大部分基础工作是重复和机械的,对于这部分基础工作,我们可以使用自定义函数进行自动化。以下简单介绍对数据表信息获取自动化处理。
1#创建数据表
2df = pd.DataFrame({"id":[1001,1002,1003,1004,1005,1006],
3"date":pd.date_range('20130102', periods=6),
4"city":['Beijing ', 'SH', ' guangzhou ', 'Shenzhen', 'shanghai', 'BEIJING '],
5"age":[23,44,54,32,34,32],
6"category":['100-A','100-B','110-A','110-C','210-A','130-F'],
7"price":[1200,np.nan,2133,5433,np.nan,4432]},
8columns =['id','date','city','category','age','price'])
9
10#创建自定义函数
11def table_info(x):
12 shape=x.shape
13 types=x.dtypes
14 colums=x.columns
15 print("数据维度(行,列):\n",shape)
16 print("数据格式:\n",types)
17 print("列名称:\n",colums)
18
19#调用自定义函数获取 df 数据表信息并输出结果
20table_info(df)
21
22数据维度(行,列):
23(6, 6)
24数据格式:
25id int64
26date datetime64[ns]
27city object
28category object
29age int64
30price float64
31dtype: object
32列名称:
33Index(['id', 'date', 'city', 'category', 'age', 'price'], dtype='object')
以上就是用 Python 做数据分析的基本内容。
-END-
一、Python入门
下面这些内容是Python各个应用方向都必备的基础知识,想做爬虫、数据分析或者人工智能,都得先学会他们。任何高大上的东西,都是建立在原始的基础之上。打好基础,未来的路会走得更稳重。所有资料文末免费领取!!!
包含:
计算机基础
python基础

Python入门视频600集:
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
二、Python爬虫
爬虫作为一个热门的方向,不管是在自己兼职还是当成辅助技能提高工作效率,都是很不错的选择。
通过爬虫技术可以将相关的内容收集起来,分析删选后得到我们真正需要的信息。
这个信息收集分析整合的工作,可应用的范畴非常的广泛,无论是生活服务、出行旅行、金融投资、各类制造业的产品市场需求等等,都能够借助爬虫技术获取更精准有效的信息加以利用。

Python爬虫视频资料
三、数据分析
清华大学经管学院发布的《中国经济的数字化转型:人才与就业》报告显示,2025年,数据分析人才缺口预计将达230万。
这么大的人才缺口,数据分析俨然是一片广阔的蓝海!起薪10K真的是家常便饭。
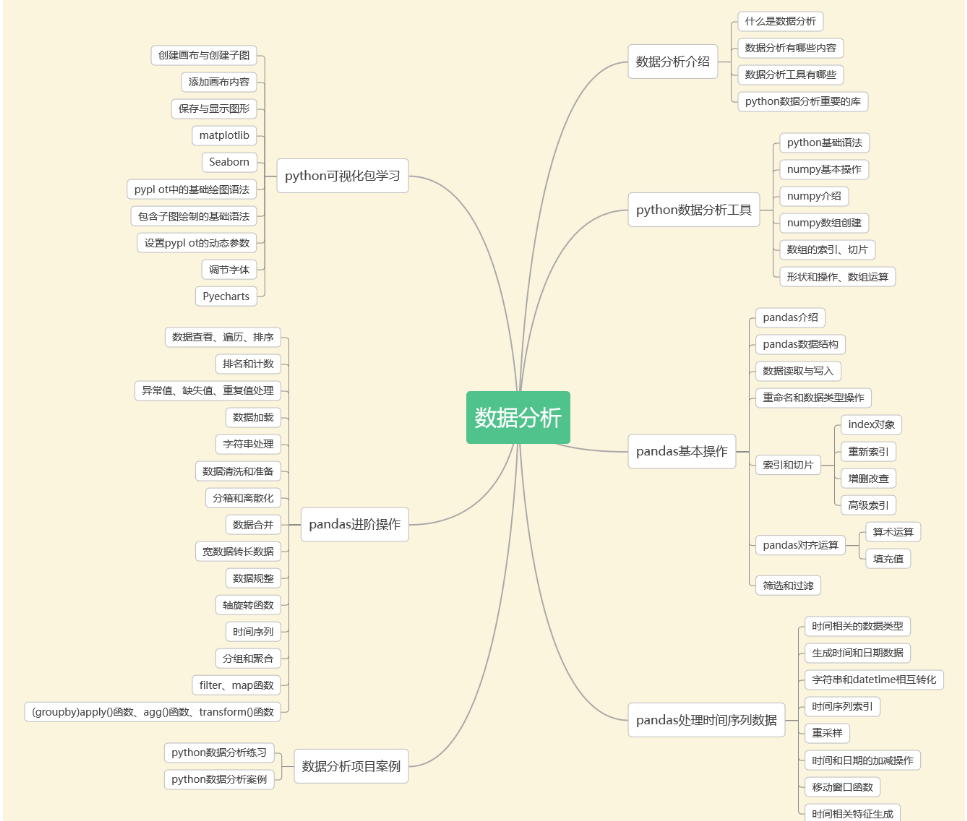
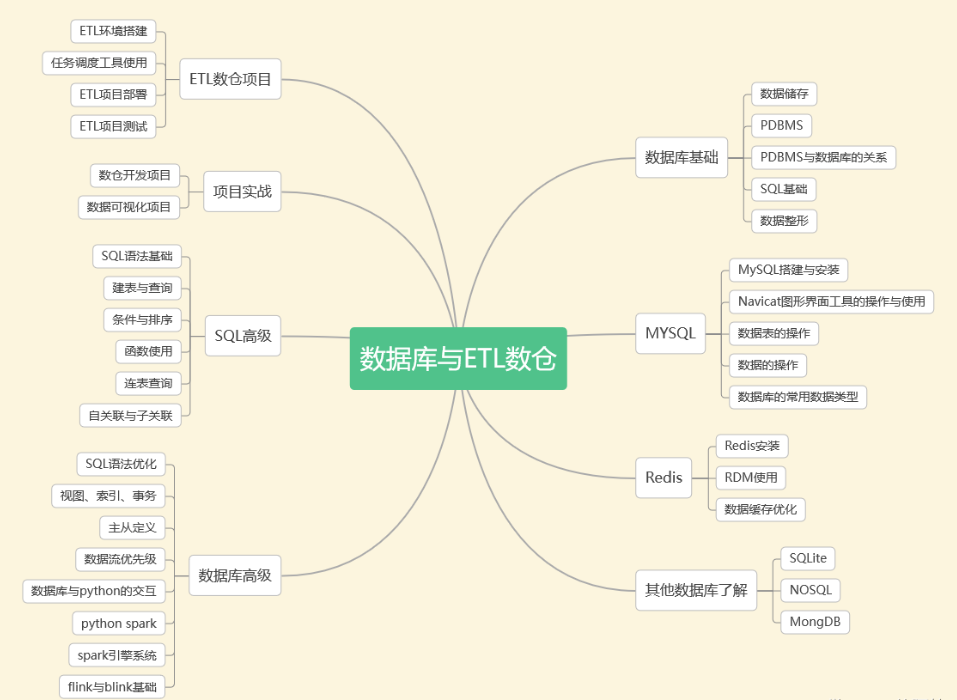
四、数据库与ETL数仓
企业需要定期将冷数据从业务数据库中转移出来存储到一个专门存放历史数据的仓库里面,各部门可以根据自身业务特性对外提供统一的数据服务,这个仓库就是数据仓库。
传统的数据仓库集成处理架构是ETL,利用ETL平台的能力,E=从源数据库抽取数据,L=将数据清洗(不符合规则的数据)、转化(对表按照业务需求进行不同维度、不同颗粒度、不同业务规则计算进行统计),T=将加工好的表以增量、全量、不同时间加载到数据仓库。
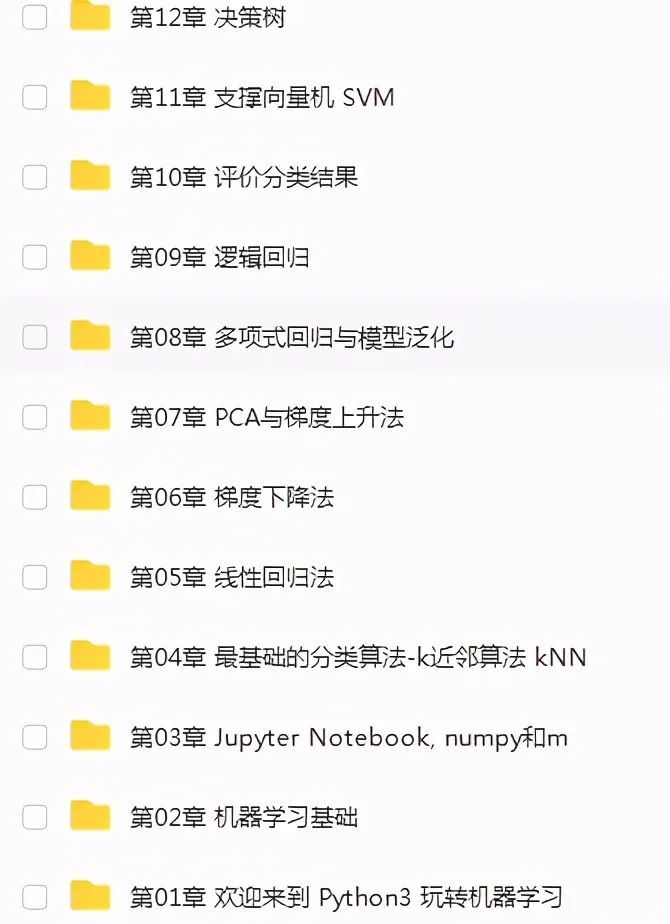
五、机器学习
机器学习就是对计算机一部分数据进行学习,然后对另外一些数据进行预测与判断。
机器学习的核心是“使用算法解析数据,从中学习,然后对新数据做出决定或预测”。也就是说计算机利用以获取的数据得出某一模型,然后利用此模型进行预测的一种方法,这个过程跟人的学习过程有些类似,比如人获取一定的经验,可以对新问题进行预测。

机器学习资料:
六、Python高级进阶
从基础的语法内容,到非常多深入的进阶知识点,了解编程语言设计,学完这里基本就了解了python入门到进阶的所有的知识点。

到这就基本就可以达到企业的用人要求了,如果大家还不知道去去哪找面试资料和简历模板,我这里也为大家整理了一份,真的可以说是保姆及的系统学习路线了。
但学习编程并不是一蹴而就,而是需要长期的坚持和训练。整理这份学习路线,是希望和大家共同进步,我自己也能去回顾一些技术点。不管是编程新手,还是需要进阶的有一定经验的程序员,我相信都可以从中有所收获。
一蹴而就,而是需要长期的坚持和训练。整理这份学习路线,是希望和大家共同进步,我自己也能去回顾一些技术点。不管是编程新手,还是需要进阶的有一定经验的程序员,我相信都可以从中有所收获。
资料领取
这份完整版的Python全套学习资料已经上传CSDN官方,朋友们如果需要可以点击下方CSDN官方认证微信卡片免费领取 ↓↓↓【保证100%免费】
