前言
教程来源:清华大佬重讲机器视觉!TensorFlow+Opencv:深度学习机器视觉图像处理实战教程,物体检测/缺陷检测/图像识别
注:
这个教程与官网教程有些区别,教程里的api比较旧,核心思想是没有变化的。
上一篇文章 TensorFlow学习:使用官方模型进行图像分类、使用自己的数据对模型进行微调是基于官方案例来实现的分类,这次是从另一个角度来实现的分类。
基础知识
这部分基础知识之前没学过,这次正好根据视频教程简单学习一下。
Keras
简介
Keras是一个开源的深度学习框架,它是建立在Python之上的高级神经网络API。它提供了一个简单、直观的接口,使得构建、训练和部署深度学习模型变得更加容易。
TensorFlow 1.9 之后与Keras 进行了集成。在TensorFlow 中可以使用其API。
Keras相关模块
applications:Kears应用程序是具有预训练权重的固定架构callback:在训练模型期间在某些点调用的实用程序datasets:Keras 内置数据集initializers:Keras初始化器,用于设置神经网络模型的权重和偏差的初始值。权重和偏差的初始值对模型的训练和收敛速度有很大的影响。layers:Keras层API,layers模块提供了各种类型的层,用于搭建不同类型的神经网络架构。比如:Dense(全连接层)、Conv2D(卷积层)losses:用于定义损失函数。损失函数是用来衡量模型的预测结果与真实标签之间的差异的指标。metrics:用于定义评估指标,用于衡量模型的性能。比如根据准确率(accuracy)来评估模型性能model:模型optimizers:内置优化器preprocessing:数据预处理工具regularizers: 内置正规化器utils:内置的一些工具类
构建神经网络模型
下面的代码是官方案例:https://tensorflow.google.cn/overview?hl=zh-cn
建议看一下视频教程里的神经网络介绍,会有一个更好的理解。
# 第一步,加载数据集、并进行归一化
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# 第二步,构建神经网络模型
model = tf.keras.models.Sequential([
# 将输入的图像数据展平为一维数组
tf.keras.layers.Flatten(input_shape=(28, 28)),
# 创建一个有128个神经元和ReLU激活函数的全连接层,用于提取图像特征
tf.keras.layers.Dense(128, activation='relu'),
# 使用Dropout层,以防止过拟合
tf.keras.layers.Dropout(0.2),
# 最后一层是具有10个神经元和softmax激活函数的全连接层,用于输出分类的概率分布。10 是因为有10中分类类别
tf.keras.layers.Dense(10, activation='softmax')
])
# 第三步,配置模型的优化器、损失函数和评估指标。
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 第四步,训练模型,训练5轮,在每一轮训练时会将所有数据进行分组,每一个组里有128张图片,批次最好是 2的次方,符合计算机2进制运算
model.fit(x_train, y_train, epochs=5, batch_size=128)
# 第五步,对模型进行测试,输出损失值、准确率
model.evaluate(x_test, y_test)
为什么使用relu激活函数
在构建神经网络模型时,选择激活函数通常是基于以下几个因素:
-
非线性性质:激活函数的非线性性质是神经网络能够学习和表示复杂函数关系的关键。因为多个线性层的组合仍然是线性的,所以我们需要使用非线性函数来引入非线性变换 。常见的非线性激活函数包括ReLU(Rectified Linear Unit)、Sigmoid、Tanh等。
-
梯度消失和梯度爆炸问题:在深层神经网络中,梯度的传播可能会出现梯度消失或梯度爆炸的问题。梯度消失指的是在反向传播过程中,梯度逐渐减小到接近零,导致底层的权重更新非常缓慢。梯度爆炸指的是梯度逐渐增大,导致底层的权重更新非常迅速。合适的激活函数可以缓解这些问题。例如,ReLU激活函数能够有效地抑制梯度消失和梯度爆炸。
-
计算效率:激活函数的计算效率也是选择的一个因素。某些激活函数的计算比较简单,能够加速模型的训练和推理过程。
根据具体的任务和网络结构,选择合适的激活函数是一个实验性过程。在实践中,ReLU是最常用的激活函数,但也可以根据需求尝试其他的激活函数来提升模型性能。
为什么使用softmax激活函数
在构建分类模型时,常常使用softmax函数作为最后一层的激活函数。softmax函数将神经网络的输出转化为概率分布,用于多类别分类任务。
softmax函数将输入的向量转化为一个概率分布向量,其中每个元素表示对应类别的概率。具体地,对于输出层的每个神经元的输出值,softmax函数将其转化为一个在0到1之间的实数,且所有元素的和为1。这样做的好处是可以直接解释模型的输出结果,可以理解为每个类别的置信度或概率。
卷积神经网络
原理见:https://www.bilibili.com/video/BV1ee411K7WU?p=36&vd_source=fd72ff60b43cc949b3316d103871c31c
基本结构
卷积神经网络一般用于解决图片方面的问题。卷积神经网络主要有一下几个结构:
- 卷积层:提取输入的不同特征
- 池化层:减少图片的特征数量,避免全连接层参数过多
- 全连接层:全连接层通常紧跟在卷积层和池化层之后,它将卷积层和池化层的输出进行扁平化,然后将其连接到一个或多个全连接层,最终输出预测结果。
卷积神经网络API
- Conv2D:实现卷积
- MaxPool2D:池化操作
例如:
# 设置卷积核为32,卷积核大小为5*5,卷积核步长为1,采用same填充方式,通道数放在最后,使用relu激活函数
tf.keras.layers.Conv2D(32, kernel_size=5, strides=1, padding='same',
data_format='channels_last', activation='relu')
# 设置池化窗口为2*2,池化操作步长为2,采用same填充方式
tf.keras.layers.MaxPool2D(pool_size=2,strides=2,padding='same')
在卷积层中,在图像分类任务中,常见的kernel_size取值为3或5,而在物体检测任务中,通常会选择更大的kernel_size。通常建议使用奇数大小的kernel_size,可以保证中心对齐、避免边缘问题等
卷积层中,卷积核的数量是一个重要的超参数,会影响模型的性能和效果。通常情况下,卷积层中的卷积核数量会逐渐增加。一种常见的做法是从较少的卷积核数量开始,逐渐增加卷积核的数量,直到达到满足性能要求的水平。
在池化层中,pool_size参数表示池化窗口的大小。常见的pool_size取值包括2x2、3x3和4x4等
图片介绍
组成特征
组成一张图片的的特征值是所有的像素值,有三个维度:图片长度、图片宽度、图片通道数。
描述一个像素点,如果是灰度图,那么只需要一个数值来描述它,就是单通道。如果一个像素点,有RGB三种颜色来描述它,那就是三通道
- 灰度图:单通道
- 彩色图片:三通道
在TensorFlow中图片会用张量来表示
- 单张图片:(高、宽、通道数)
- 多张图片:(一个批次的图片数量,高、宽、通道数)
图片读取处理
读取图片
import tensorflow as tf
# 加载图片,并加图片大小设置为224 * 224
image = tf.keras.preprocessing.image.load_img('./images/flower.jpg',target_size=(224,224))
print("图片:",image)
不同的模型对输入的图片大小有不同的要求,需要调整图片大小使其符合模型的输入。

将图片转换为数组格式
读取的图片不能直接使用,需要将其转换成数组格式(张量)
# 转换成数组
img_arr = tf.keras.preprocessing.image.img_to_array(image)
print("图片形状:", img_arr)

有些模型还会对数组进行归一化,img_arr = img_arr / 255.0 。除以255是因为三原色值是0~255 。
注: img_to_array 有第二个参数为格式化方式,值是channels_first 或者 channels_last。即图片的通道数是在前面还是后面,不同框架可能会有不同的要求,TensorFlow默认为通道数在后。
图片形状
模型对图片的输入一般是三维或者四维的,可以进行查看或修改,以保证符合模型的要求
# 加载图片,并加图片大小设置为224 * 224
image = tf.keras.preprocessing.image.load_img(
'./images/flower.jpg', target_size=(224, 224))
print("图片:", image)
# 转换成数组
img_arr = tf.keras.preprocessing.image.img_to_array(image)
print("图片形状:", img_arr.shape) # 三维 (224, 224, 3)
# 有些模型需要四维模型,可以进行转换
new_img = img_arr.reshape(1,img_arr.shape[0],img_arr.shape[1],img_arr.shape[2])
print("四维:", new_img.shape) # (1, 224, 224, 3)

图片分类
这里只简单介绍一下基于mobilenet_v2来进行迁移学习。在TensorFlow学习:使用官方模型进行图像分类、使用自己的数据对模型进行微调 中介绍过一种方式,文章中的方式是来自于官方文档。
这里的方式是来源于视频教程:模型定义
训练模型
import tensorflow as tf
# matplotlib是用于绘制图表和可视化数据的库
import matplotlib.pylab as plt
import datetime
# 加载内置的模型,include_top=False不使用默认的分类
base_model = tf.keras.applications.mobilenet_v2.MobileNetV2(include_top=False)
# 冻结模型训练数据,冻结模型结构是为了保持预训练模型的权重不受训练的影响
# 训练数据少时只需要训练全连接层即可
for layer in base_model.layers:
layer.trainable = False
# 初始化类,并归一化
train_generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1.0/255.0)
test_generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1.0/255.0)
# 读取训练集
train = train_generator.flow_from_directory(
directory='data/train', # 文件目录
target_size=(224, 224), # 处理图片大小,(h,w)
batch_size=32, # 批次数量
class_mode='categorical' # 设置类别模式为,根据文件夹确定类别
)
# 读取验证集
test = test_generator.flow_from_directory(
directory='data/validation', # 文件目录
target_size=(224, 224), # 处理图片大小,(h,w)
batch_size=32, # 批次数量
class_mode='categorical' # 设置类别模式为,根据文件夹确定类别
)
#print(train, test)
print(base_model.summary())
#print("输入:",base_model)
# 微调模型
x = base_model.outputs[0] # 移除分类后的模型输出
#print('x:', x)
# 输出到全连接层,加上全局池化
x = tf.keras.layers.GlobalAveragePooling2D()(x)
# 添加一个有1024个神经元使用relu激活函数的全连接层
x = tf.keras.layers.Dense(1024, activation='relu')(x)
y_predict = tf.keras.layers.Dense(2, activation='softmax')(x) # 全连接层,这里两个神经元是因为只有图片只有两类
# 新模型
new_model = tf.keras.models.Model(inputs=base_model.inputs, outputs=y_predict)
print("新模型:",new_model)
# 编译模型
new_model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 记录训练日志
log_dir = "logs/fit/" + datetime.datetime.now().strftime('%Y%m%d-%H%M%S')
# 用于在训练过程中收集模型指标和摘要数据,并将其写入TensorBoard日志文件中
tensorboard_callback = tf.keras.callbacks.TensorBoard(
log_dir= log_dir,
histogram_freq=1
)
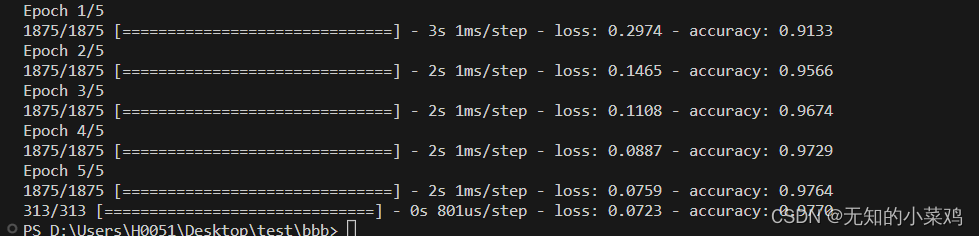
history = new_model.fit_generator(train,epochs=10,validation_data=test,callbacks=[tensorboard_callback])
# 导出模型
export_path = 'tmp/cat_dog_model'
new_model.save(export_path)
这种方式需要按照固定的目录结果,如下
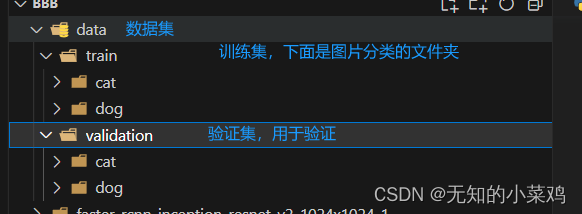
导出的模型
使用训练好的模型,进行预测
from matplotlib.font_manager import FontProperties
import tensorflow as tf
# matplotlib是用于绘制图表和可视化数据的库
import matplotlib.pylab as plt
import numpy as np
#1、加载本地图片,并将其处理为224*224
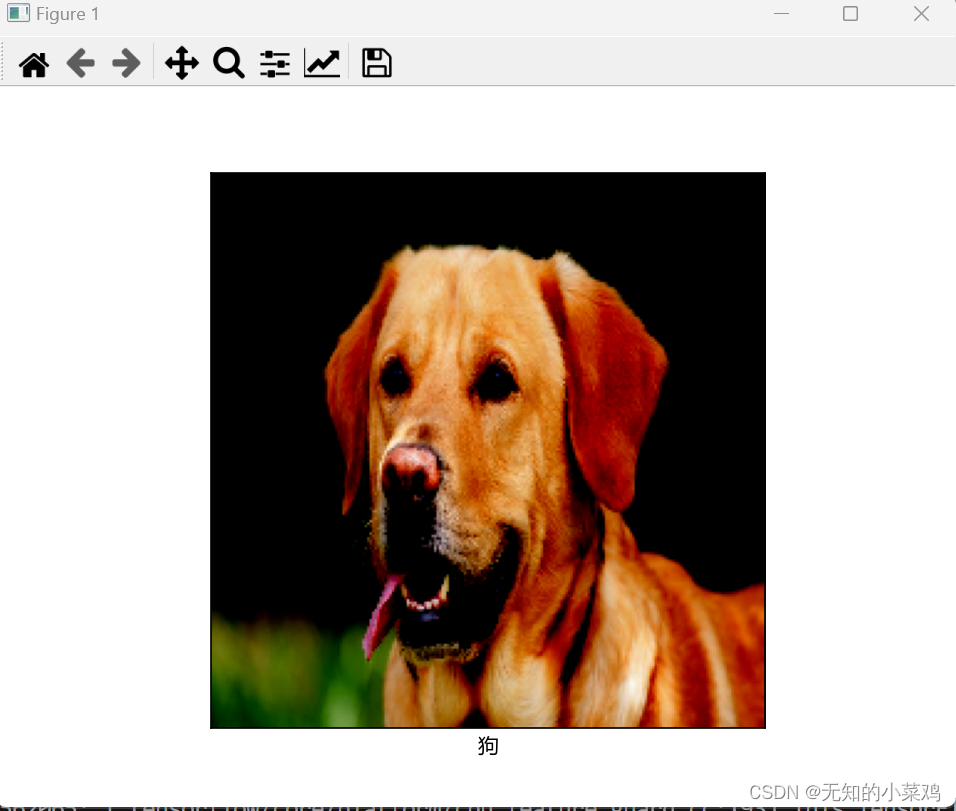
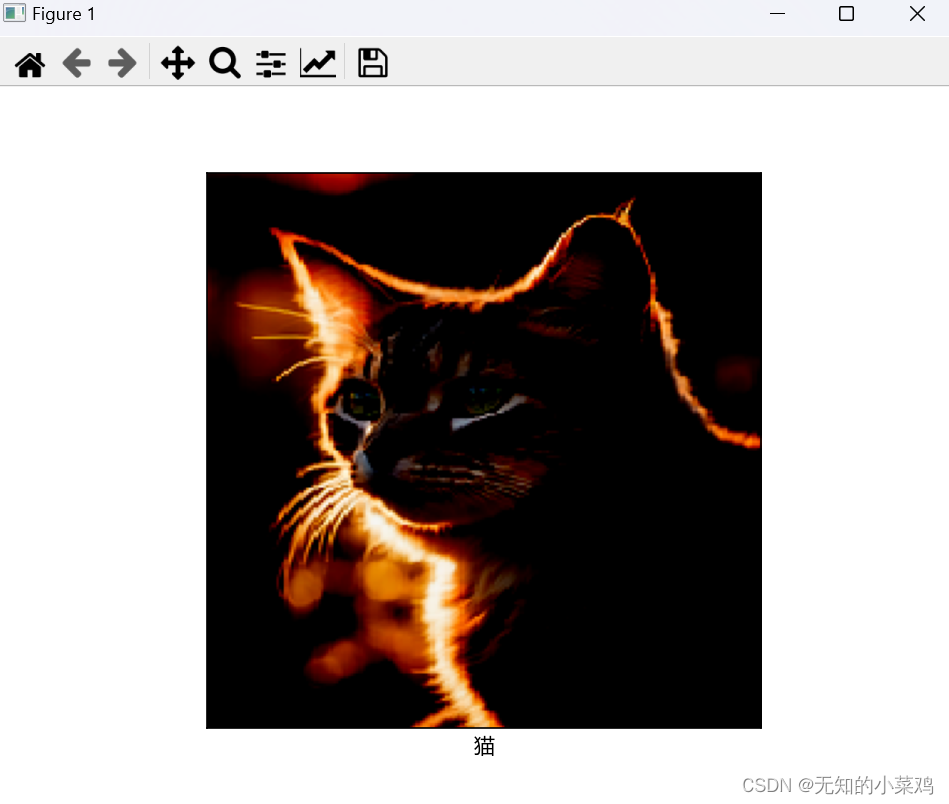
image = tf.keras.preprocessing.image.load_img('./images/cat.png',target_size=(224,224))
# 2、转成数组
image = tf.keras.preprocessing.image.img_to_array(image)
print("图片形状:",image.shape)
# 3、扩展维度
image = image.reshape(1,image.shape[0],image.shape[1],image.shape[2])
# 4、处理输入,因为我们是基于mobilenet_v2训练的,因此可以使用mobilenet_v2处理图片
image = tf.keras.applications.mobilenet_v2.preprocess_input(image)
# 5、加载模型
model = tf.keras.models.load_model('./tmp/cat_dog_model')
# 6、预测
predictions = model.predict(image)
index = np.argmax(predictions,axis=1)[0]
label = ['猫','狗'][index]
print("预测结果:",predictions,index,label)
#7、可视化显示
font = FontProperties()
font.set_family('Microsoft YaHei')
plt.figure() # 创建图像窗口
plt.xticks([])
plt.yticks([])
plt.grid(False) # 取消网格线
plt.imshow(image[0]) # 显示图片
plt.xlabel(label[0],fontproperties=font)
plt.show() # 显示图形窗口