
众所周知,大模型的训练和推理需要大量的GPU资源,70B参数的大模型需要130G的GPU显存来存储,需要两个A100(显存为100G)。
在推理过程中,整个输入序列也需要加载到内存中进行复杂的“注意力”计算,这种注意力机制的内存需求与输入长度成二次方关系。
一、分层推理(Layer-wise Inference)
分层推理是计算机科学中分而治之的基本方法。今天的大型语言模型都采用谷歌论文《Attention is all you need》中提出的多头自注意力结构,这就是人们后来所说的Transformer结构,Transformer结构如下图所示:

大型语言模型首先是embedding投影层,之后是80个完全相同的transformer层,每个transformer层有一个LN和MLP层来预测token ID概率。
在推理过程中,层按顺序执行,上一层的输出是下一层的输入,一次只执行一个层。因此,完全没有必要将所有层都保存在GPU内存中。我们可以在执行该层时从磁盘加载所需的任何层,进行所有计算,然后完全释放内存。这样,每层所需的GPU内存仅为一个transformer层的参数大小,即整个模型的1/80,约1.6GB。
此外,一些输出缓存也存储在GPU内存中,最大的是KV缓存,以避免重复计算。对于70B模型,这个KV缓存大小大约是:
2*input_length*num_layers*num_heads*vector_dim*4
输入长度为100时,此缓存=2*100*80*8*128*4=30MB GPU内存。
二、Flash Attention
Flash attention可能是当今大型语言模型开发中最重要、最关键的优化之一,几乎所有的大型语言模型都采用该技术来优化。Flash attention思想受论文《Self-attention Does Not Need O(n²) Memory》启发,最初self-attention需要O(n²)内存(n是序列长度),论文认为实际上不需要保留O(n²)的中间结果,我们可以按顺序计算它们,不断更新一个中间结果,并丢弃其他所有结果,这将内存复杂性降低到O(logn)。
Flash attention本质上是相似的,内存复杂度O(n)略高,但 Flash attention深度优化了cuda内存访问,实现了推理和训练的多倍加速。
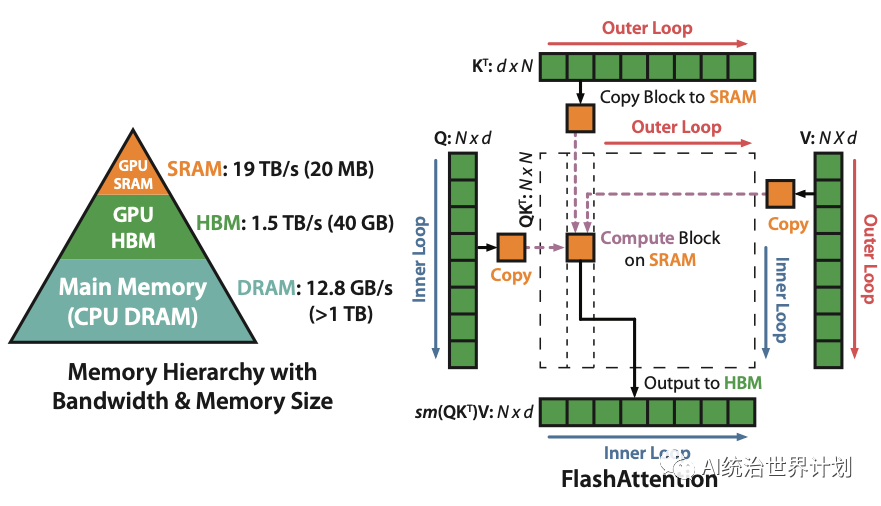
如图所示,最初的self-attention计算并存储O(n²)中间结果。Flash attention将计算拆分为许多小块,逐块计算,并将内存减少到一个块的大小。
三、模型文件共享
原始模型文件通常被分为多个块,通常每个块10GB。我们的执行过程是一层一层的。每层只有1.6GB。如果我们基于原始10GB碎片进行加载,则每层执行都需要重新加载整个10GB文件,但仅使用1.6GB。这个过程浪费了大量用于加载和磁盘读取的内存。磁盘读取速度实际上是整个推理过程中最慢的瓶颈,所以我们希望尽可能地将其最小化。因此,我们首先对原始的HuggingFace模型文件进行预处理,并对其进行分层分割。
对于存储,我们使用安全张量技术(https://github.com/huggingface/safetensors)。Safetensor确保存储格式和内存中格式紧密匹配,并使用内存映射进行加载以最大限度地提高速度。
四、元设备(Meta Device)
我们使用HuggingFace Accelerate提供的Meta Device功能(https://huggingface.co/docs/accelerate/usage\\_guides/bigh\\_modeling)来实施。Meta Device是一种专门为运行超大型模型而设计的虚拟设备。当您通过Meta Device加载模型时,模型数据实际上并没有被读入,只是加载了代码,内存使用率为0。
在执行过程中,您可以将模型的部分内容从Meta Device动态转移到CPU或GPU等真实设备。只有到那时,它才真正加载到内存中。
使用init_empty_weights()可以通过Meta Device加载模型,代码如下:
from accelerate import init_empty_weightswith init_empty_weights():my_model = ModelClass(...)
五、开源项目
上述所有技术已经集成到AirLLM(https://github.com/lyogavin/anima/tree/main/air_llm)。使用参考如下:
首先安装程序包:
pip install airllm像传统的Transformer模型一样执行分层推理,代码如下:
from airllm import AirLLMLlama2MAX_LENGTH = 128# could use hugging face model repo id:model = AirLLMLlama2("garage-bAInd/Platypus2-70B-instruct")# or use model's local path...#model = AirLLMLlama2("/home/ubuntu/.cache/huggingface/hub/models--garage-bAInd--Platypus2-70B-instruct/snapshots/b585e74bcaae02e52665d9ac6d23f4d0dbc81a0f")input_text = ['What is the capital of United States?',]input_tokens = model.tokenizer(input_text,return_tensors="pt",return_attention_mask=False,truncation=True,max_length=MAX_LENGTH,padding=True)generation_output = model.generate(input_tokens['input_ids'].cuda(),max_new_tokens=20,use_cache=True,return_dict_in_generate=True)output = model.tokenizer.decode(generation_output.sequences[0])print(output)
我们已经在16GB的Nvidia T4 GPU上测试了此代码。整个推理过程使用的GPU内存不足4GB。
PS:像T4这样的低端GPU的推理速度将相当慢。不太适合聊天机器人等交互式场景。更适合一些离线数据分析,如RAG、PDF分析等。目前仅支持基于Llam2的型号。
六、70B训练可以在单个GPU上进行吗?
虽然推理可以通过分层进行优化,但训练在单个GPU上也能类似地工作吗?
在执行下一个transformer层时,推理只需要上一层的输出,因此可以使用有限的数据进行分层执行。训练需要更多的数据,训练过程首先计算正向传播,得到每一层和张量的输出,然后进行反向传播来计算每个张量的梯度,梯度计算需要保存之前正向层的结果,因此分层执行不会减少内存。
还有一些其他技术,如梯度检查点,可以实现类似的效果。
参考文献:
[1] https://ai.gopubby.com/unbelievable-run-70b-llm-inference-on-a-single-4gb-gpu-with-this-new-technique-93e2057c7eeb
[2] https://www.kaggle.com/code/simjeg/platypus2-70b-with-wikipedia-rag/notebook