目的:在一个server端使用TensorFlow框架对模型进行训练和保存模型文件后用TensorFlow Serving进行部署,使得能在客户端上传输入数据后得到server端返回的结果,实现远程调用的效果。
环境:
操作系统: ubuntu 20.04.1当然可以自己用Flask框架甚至写一个前端页面,这样同样能达到同样的效果。不过,如果是在真的实际生产环境中部署,这样的方式就显得力不从心了。这时,TensorFlow 为我们提供了 TensorFlow Serving 这一组件,能够帮助我们在实际生产环境中灵活且高性能地部署机器学习模型。
这次我们的案例很简单,使用MLP训练一个mnist手写数字识别,并在客户端中在数据集中取10个数据放入server端进行验证得到的结果返回给client端再与真实标签做对比,下面准备代码:
# server.py
import tensorflow as tf
import numpy as np
class MNISTLoader():
def __init__(self):
mnist = tf.keras.datasets.mnist
(self.train_data, self.train_label), (self.test_data, self.test_label) = mnist.load_data()
# MNIST中的图像默认为uint8(0-255的数字)。以下代码将其归一化到0-1之间的浮点数,并在最后增加一维作为颜色通道
self.train_data = np.expand_dims(self.train_data.astype(np.float32) / 255.0, axis=-1) # [60000, 28, 28, 1]
self.test_data = np.expand_dims(self.test_data.astype(np.float32) / 255.0, axis=-1) # [10000, 28, 28, 1]
self.train_label = self.train_label.astype(np.int32) # [60000]
self.test_label = self.test_label.astype(np.int32) # [10000]
self.num_train_data, self.num_test_data = self.train_data.shape[0], self.test_data.shape[0]
def get_batch(self, batch_size):
# 从数据集中随机取出batch_size个元素并返回
index = np.random.randint(0, self.num_train_data, batch_size)
return self.train_data[index, :], self.train_label[index]
class MLP(tf.keras.Model):
def __init__(self):
super().__init__()
self.flatten = tf.keras.layers.Flatten() # Flatten层将除第一维(batch_size)以外的维度展平
self.dense1 = tf.keras.layers.Dense(units=100, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units=10)
@tf.function
def call(self, inputs): # [batch_size, 28, 28, 1]
x = self.flatten(inputs) # [batch_size, 784]
x = self.dense1(x) # [batch_size, 100]
x = self.dense2(x) # [batch_size, 10]
output = tf.nn.softmax(x)
return output
num_epochs = 1
batch_size = 50
learning_rate = 0.001
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(100, activation=tf.nn.relu),
tf.keras.layers.Dense(10),
tf.keras.layers.Softmax()
])
data_loader = MNISTLoader()
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=[tf.keras.metrics.sparse_categorical_accuracy]
)
model.fit(data_loader.train_data, data_loader.train_label, epochs=num_epochs, batch_size=batch_size)
tf.saved_model.save(model, "saved/1")运行 server.py 后会在当前目录下创建saved文件夹存放模型文件
# client.py
import json
import numpy as np
import requests
class MNISTLoader():
def __init__(self):
mnist = tf.keras.datasets.mnist
(self.train_data, self.train_label), (self.test_data, self.test_label) = mnist.load_data()
# MNIST中的图像默认为uint8(0-255的数字)。以下代码将其归一化到0-1之间的浮点数,并在最后增加一维作为颜色通道
self.train_data = np.expand_dims(self.train_data.astype(np.float32) / 255.0, axis=-1) # [60000, 28, 28, 1]
self.test_data = np.expand_dims(self.test_data.astype(np.float32) / 255.0, axis=-1) # [10000, 28, 28, 1]
self.train_label = self.train_label.astype(np.int32) # [60000]
self.test_label = self.test_label.astype(np.int32) # [10000]
self.num_train_data, self.num_test_data = self.train_data.shape[0], self.test_data.shape[0]
def get_batch(self, batch_size):
# 从数据集中随机取出batch_size个元素并返回
index = np.random.randint(0, self.num_train_data, batch_size)
return self.train_data[index, :], self.train_label[index]
data_loader = MNISTLoader()
data = json.dumps({
"instances": data_loader.test_data[0:3].tolist()
})
headers = {"content-type": "application/json"}
json_response = requests.post(
'http://localhost:8501/v1/models/MLP:predict',
data=data, headers=headers)
predictions = np.array(json.loads(json_response.text)['predictions'])
print(np.argmax(predictions, axis=-1))
print(data_loader.test_label[0:10])client.py暂时不急着运行,先执行下面的步骤
TensorFlow Serving 安装
TensorFlow Serving 可以使用 apt-get 或 Docker 安装。在生产环境中,推荐使用Docker部署 TensorFlow Serving 。不过此处出于教学目的,介绍依赖环境较少的 apt-get 安装(具体参考官方文档https://www.tensorflow.org/tfx/serving/setup)。
首先设置安装源:
echo "deb [arch=amd64] http://storage.googleapis.com/tensorflow-serving-apt stable tensorflow-model-server tensorflow-model-server-universal" | sudo tee /etc/apt/sources.list.d/tensorflow-serving.list && \
curl https://storage.googleapis.com/tensorflow-serving-apt/tensorflow-serving.release.pub.gpg | sudo apt-key add -更新源后,即可使用 apt-get 安装 TensorFlow Serving:
sudo apt-get update
sudo apt-get install tensorflow-model-serverTensorFlow Serving 模型部署
在命令行运行下面的命令
tensorflow_model_server \
--rest_api_port=8501 \
--model_name=MLP \
--model_base_path="SavedModel格式模型的文件夹绝对地址(不含版本号)"运行成功后会得到下面的结果,可以看到8501端口已经开启
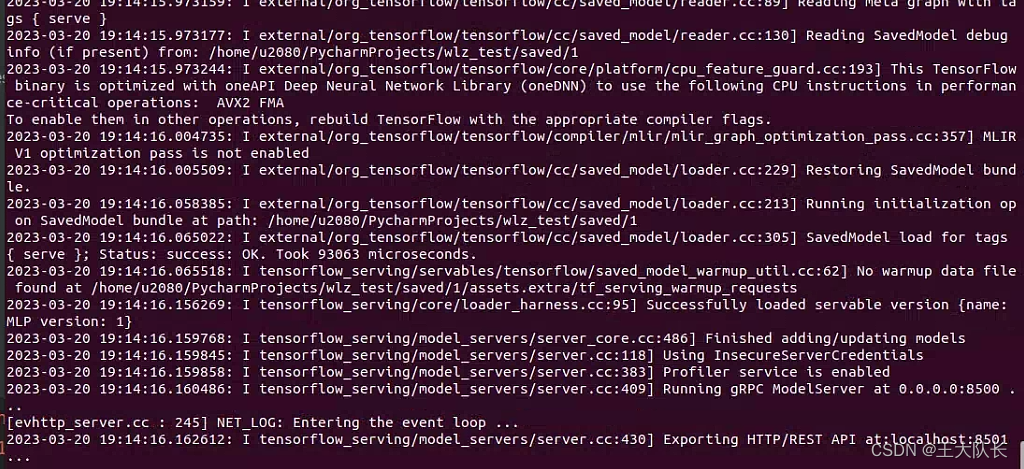
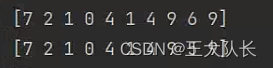
下面我们执行上面的client.py 便能得到结果,可以发现预测结果与真实标签值非常接近。
参考资料:
TensorFlow Serving — 简单粗暴 TensorFlow 2 0.4 beta 文档 (tf.wiki)