初心
,这篇论文在 的代码中有用到,我看了这篇论文看了挺久的,本着知识共享,不做重复劳动,最大化社(吹)会(牛)资(不)源(打)利(草)用(稿)的原则,现就我的理解与大家分享一下,方便大家更快的理解(并不是翻译论文,只是说下我的理解),以免重复劳动。若有不足或错误之处,还望批评指正。
简介
在 部分中,作者介绍了目前的多人二维人体姿态估计的一些方式,分两种:自上而下的方式( )和自下而上的方式( )。
自上而下的方式
自上而下的方式,对人体姿态的估计分两步:当一张图片输入后,首先会有一个人体探测器( )将图片中的人找出来,然后用单个人体姿态估计,文中给了一些单个人体姿态估计的文章【17, 31, 18, 28, 29, 7, 30, 5, 6, 20】,对每一个找到的人体进行姿态估计。这种方法很直观,但是它的缺点是随着图片中的人的数量的增加,姿态估计的速度也会增加。因此自下而上的方法在这方面就显示出了很大的优势。
自下而上的方式
自下而上的方式与自上而下的方式最大的区别在于,自下而上的方式是先检测各个关节的位置,在把这些点组合成一个一个人。这篇文章采用的就是自下而上的思路。这样做的好处是理论上随着人数的增加,处理时间并不会增加。
方法
论文中提到两个关键的概念,一个叫局部置信图( )和一个叫局部相似域( )。前者用于定位各个关节的位置,后者影响各个关节的连接,比如手腕有三个点,肘有三个点,那么哪个腕和哪个肘相连就是要参考PAF的信息。结合代码,整个的处理流程分三步,预处理,接着得到PCM和PAF,最后连接组合成每个人的人体姿态。
预处理
文中对预处理知识粗略的讲了一下采用了VGG-19网络的前10层,实际上代码中给出的模型对这个前十层还是有改动的,具体的改动参照keras_Realtime_Multi-Person_Pose_Estimation代码中给出的模型,这里就不细讲了。经过预处理后,图片的尺度缩小了很多,因为在预处理过程中使用了池化操作,具体使用了几层,由于在写这篇博文的时候,我记得不是很清楚,因此同样可以去上面的代码中的模型找到。
获得PCM和PAF
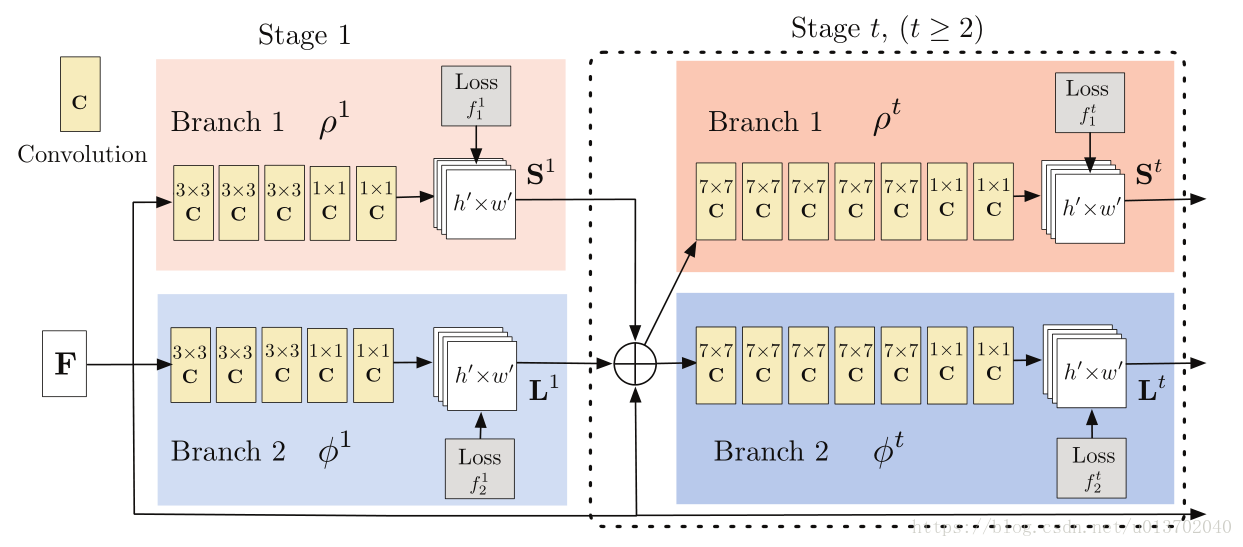
文中图3如下
接下来对上图进行一下解读。
首先图中
表示卷积神经网络,3*3表示卷积核的大小,至于输出的维度是多少,需要去上面给的代码模型去看,文中并没有给出具体的维度,F表示经过预处理的输出结果,这个结果将在网络后面的每一个阶段(
)都会拼接到前一阶段的输出后面,再一起作为当前阶段的输入。
表示
阶段的PCM预测网络的处理过程,输出
阶段预测的PCM。
表示
阶段的PAF预测网络的处理过程,输出
阶段预测的PAF。中间的一个圆圈加加号,文中将它叫串级(
),实际上就是将PCM、PAF和F叠在一起。
第一层输出的是每个阶段预测的PCM,第二层输出的是每个阶段的PAF。我们可以把出了最后一个阶段输出的PCM和PAF当做是临时的,最后一个Stage输出的就是整个深度学习网络预测的PCM和PAF,为什么这么说,因为后面的误差计算公式可以看到每一层的输出都是和同一个label作比较。(由此,我的理解是,这个网络是一个逐渐精确的一个过程,有个词叫由粗到细,这是我的理解,不是文中的意思)。
图片解读完了,再来解读下公式。
第一组公式比较好理解
这里其实就是把上面图的意思用数学公式的形式表示出来而已。
注意:有很多人看这篇论文的时候会把训练和预测两个过程搞混淆,实际上,我们得到模型参数后,直接用于预测,是没有后面的误差计算的,直接将图片输入,直接取第 个阶段的输出就是我们要得到的PCM和PAF,中间的误差,在预测阶段其实没有什么用,误差是用来训练模型所需要的,预测一般不需要误差,如果只是预测,那么到这一步就行了。下面的公式是用来训练的,千万别搞混了,一定要弄清楚哪些是预测出来的,哪些是需要label计算的。
第二组公式是用来计算误差的,先摆公式
其中
是一个二值的函数,如果在图片上
点处没有标记,则为0,否则为1,相当于一个掩码,只把label附近的一圈给显出来,其他的都隐藏起来。
和 ,表示了 阶段第 个或第 个特征图在 点处的值,接下去很多人会对这里的 和 表示很模糊,其实 的取值范围为从0到18,表示了18个关节的PCM,比如说0代表鼻子,那么输出的第0个特征图表示图片中鼻子的分布。以此类推。 表示PAF的编号,取值范围为0到37,有人会发现刚好是19的两倍。因为论文中写的是比较笼统的,我这里是按照代码中给的人体模型来说明的,不同的人体模型是不一样的数值。像上述代码中给的模型共19个点,所以编号0到18,那么PAF是一个向量,一张特征图,在该点上只有一个值,因此,需要两个特征图合在一起来表示PAF的向量,因此PAF的特征图的个数是PCM的两倍。
到这里,网络的输出我们得到了,但是标准值还不知道。没错,后面带星号的就是标准值,那么这个值时怎么来的呢?这就要讲到文中(6)(7)(8)(9)这四个公式了。后面再说。
为什么把这三个公式放在一起,因为这三个公式表示了误差计算的详细过程,深度学习的目的就是为了使这个值越来越小。
接下去就是要获得标准的PCM,也就是
,首先我们要明确这个是什么东西,这其实是一张图,这是一张根据关节坐标生成的一张热图,这张图是怎么得到的呢,是由下面的一组公式得到的,公式如下:
这个公式中
表示第
个人,
代表第
个关节,
表示第
个人第
个关节认为标定的坐标,
表示标准差,这个标准差是认为设定的,很多人都能看出这是一个高斯函数,表示的是关节
的特征图(之前说的热图)在
点的
值与
点到
点的距离有关,是一个高斯函数。如果
大于1怎么办,每个人的该关节在该点上都有一个值,该取谁的呢?上面的第二个公式(文中公式7),就告诉我们,去最大值。
至此,我们已经可以计算出PCM的标准值了,那么PAF的标准值怎么求呢?这就要用到文中(8)(9)两个公式了,公式如下:
这里需要摆张图

这张图说明什么呢?我们假设从
指向
,由
可知,这里的
就是从
指向
的单位向量,由第一个公式可知,只要
点在肢体上,就取为
,否则取0,那么问题又来了,怎么判断是不是在肢体上呢?文中给出了两个公式:
,这个公式的意思是p点在沿肢体方向的投影大于0小于肢体长度,另一个公式:
,这个公式表示p点在沿肢体垂直方向的投影长度,小于肢体的宽度。满足上述两个条件,我们定义为在肢体上,赋值
。那么肢体宽度怎么定义呢?文中没说(或者说我没看到),我曾在计算PAF标准值的时候,将宽度设为长度的一半。当然这不是文中的意思,是我个人的意思,其实没有什么意思,就是随便意思意思。
至此,我们得到的是多个人的PAF,针对某张图片中某个肢体的PAF应该有上面公式组中的第二行公式得到,就是重叠的向量相加,除以重叠的人数。
但是这里需要注意的是,PAF是一个向量,而网络输出的特征图在每个点上只有一个数字,怎么用让特征图表示一个向量呢?这时,实际操作中,将两个特征图进行意念组合(所谓意念,就是人为认定这两个特征图是一组的)。代码中给的模型输出的PAF有38个,这是因为两个表示一个向量,共有38个特征图。
到这,才真正得出了肢体的PAF的标准值,就可以和网络输出的PCM和PAF相减,求平方和得到误差,进行深度学习了。\
解析人体姿态
人体姿态的解析根据PAF在PCM两点之间求线积分,再通过非极大值抑制,求取最大的两点作为相连的两个点。由于这部分还有一些盲点没有搞清楚,因此就不详细写了。等弄清楚了之后,在另行补充。
总结
有空再写剩下的。
