参考视频:
BERT 论文逐段精读【论文精读】_哔哩哔哩_bilibili
背景
BERT算是NLP里程碑式工作!让语言模型预训练出圈!
使用预训练模型做特征表示的时候一般有两类策略:
1. 基于特征 feature based (Elmo)把学到的特征和输入一起放进去做一个很好的特征表达
2. 基于微调 fine-tuning (GPT)
但是都用的是单向语言模型↑ 预测模型,所以限制了语言架构,比如说只能从左往右读
Masked Language Model
为了接触限制,BERT用的是一个带掩码的语言模型(MLM)(Masked Language Model),随机选字元,盖住,预测盖住的字
看多模态模型的时候有提到过!↑
next sentence prediction
在原文中随机取两个句子,让模型判断句子是否相邻
贡献
1. 说明双向信息的重要性
2.假设有比较好的预训练模型就不用对特定任务做特定的模型改动了
主要就是把前人的结果拓展到深的双向的模型架构上
相关工作
1. Unsupervised Feature-based Approches
2. Unsupervised Fine-tuning Approaches(GPT)
3. 在有标号的数据上进行迁移学习 (Transfer Learning from Supervised Data)
方法
模型
本篇工作调整了L:Transformer模块的个数,H:隐藏层的个数以及A:自注意力头的个数
BERT Base(L=12, H=768, A=12)
BERT Large(L=24, H=1024, A=16)
如何把超参数换算成可学习参数的大小?
可学习参数主要来自嵌入层以及Transformer Block
嵌入层
输入:字典的大小
↓
Transformer Block(自注意力,MLP)
自注意力头个数A x 64
Transformer Block 的可学习参数是H^2 *4 (自注意力)
MLP H^2 *8
此处合起来Transformer的参数是(H^2 *12)*L
↓
输出:隐藏单元的个数H
总参数(36K * H + L*H*12)=110M
输入和输出
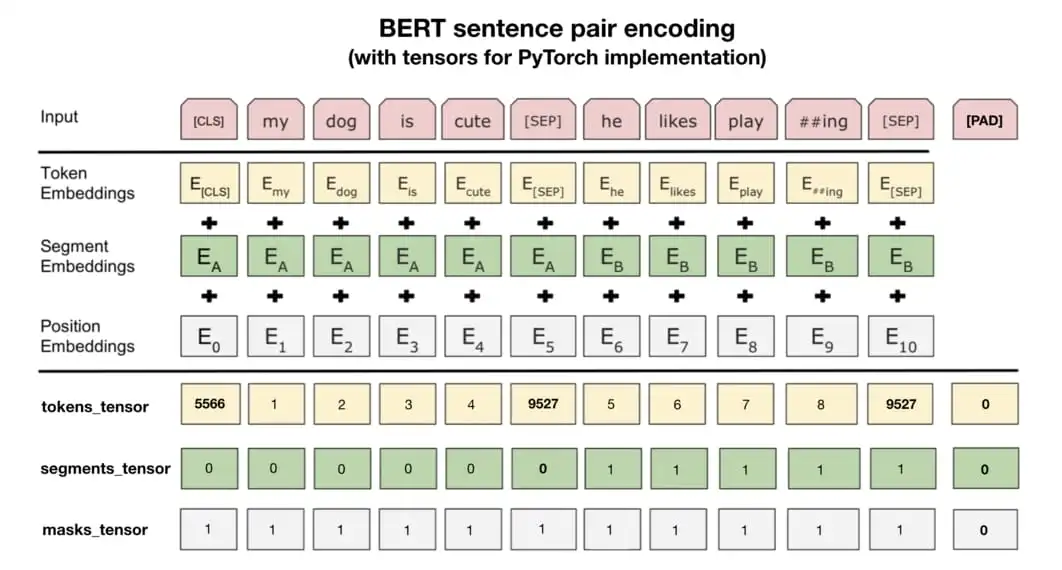
输入:
序列(sequence):既可以是句子,也可是句子对
切词方法: WordPiece,节省参数
序列的第一个词永远是序列[CLS],因为bert希望它最后输出代表整个序列的一个信息
把两个句子合在一起的时候需要区分两个句子:
1)把每个句子后面放上特殊的词[SEP]
2) 学一个嵌入层

对每个词元进入BERT的向量表示,是词元本身的embedding,加句子embedding加position embedding
缺点:
与GPT(Improving Language Understanding by Generative Pre-Training)比,BERT用的是编码器,GPT用的是解码器。BERT做机器翻译、文本的摘要(生成类的任务)不好做。
写的不算全,后面看到后面补。