1.BERT-wwm
1-1 Whole Word Masking
Whole Word Masking (wwm)是谷歌在2019年5月31日发布的一项BERT的升级版本,主要更改了原预训练阶段的训练样本生成策略。
原有基于WordPiece的分词方式会把一个完整的词切分成若干个子词,在生成训练样本时,这些被分开的子词会随机被mask。 在Whole Word Masking (wwm)中,如果一个完整的词的部分WordPiece子词被mask,则同属该词的其他部分也会被mask。这缓解了在训练前 BERT 中屏蔽部分 Wordpiece 分词的缺点。
2.Chinese-BERT-wwm
2-1 中文BERT-WWM
2019年哈工大和科大讯飞联合发表中文BERT-WWM模型的论文,使用中文文本对整个单词进行掩蔽,即屏蔽整个单词而不是屏蔽汉字。由于谷歌官方发布的BERT中,中文以字粒度进行切分,没有考虑到传统NLP中的中文分词。 Chinese-BERT-wwm将 Whole Word Mask的方法应用在了中文中,使用了中文维基百科(包括简体和繁体)进行训练,并且使用了哈工大LTP作为分词工具,即对组成同一个词的汉字全部进行Mask。
2-2 样例
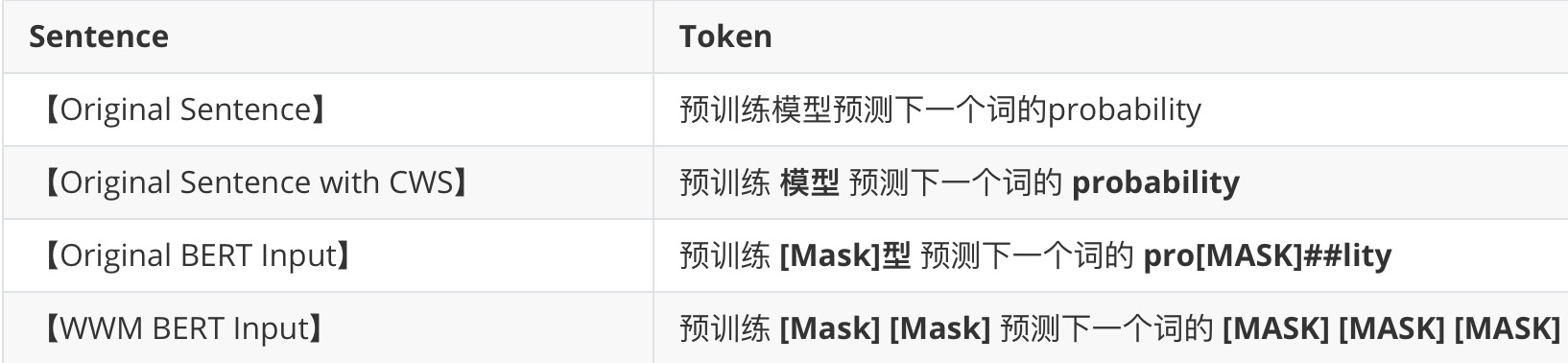
3.总结
BERT-WWM对Bert的改进主要体现在mask的方式上,使用全词mask。
其改进点如下:BERT-WWM不仅仅是连续mask实体词和短语,而是连续mask所有能组成中文词语的字。具体做法是,针对中文,如果一个完整的词的部分字被mask,则同属该词的其他部分也会被mask,即对组成同一个词的汉字全部进行Mask,即为全词Mask。
这样做的目的是:预训练过程中,模型能够学习到词的语义信息,训练完成后字的embedding就具有了词的语义信息了,这对各类中文NLP任务都是友好的。