
一、BERT概述
BERT是由Google在2018年提出的一种预训练语言模型。BERT的创新之处在于采用了双向Transformer编码器来生成上下文相关的词向量表示。
传统的单向语言模型只考虑了左侧或右侧的上下文信息,而BERT则同时考虑了左侧和右侧的上下文信息,使得生成的词向量具有更好的语义表达能力。
BERT的训练包括两个阶段:预训练和微调:
-
在预训练阶段,BERT使用了大规模的未标记语料来学习通用的语言表示。预训练任务包括“掩码语言模型”和“下一句预测”。掩码语言模型任务要求模型预测被掩码的词语,而下一句预测任务要求模型判断两个句子是否是相邻的。
-
在微调阶段,BERT使用已标记的任务特定数据进行微调,比如文本分类、命名实体识别等。通过在特定任务上微调,BERT可以将通用的语言表示应用到具体的任务中。
BERT的出现对自然语言处理领域产生了重大影响。它在多个语言任务上取得了最先进的性能,并且可以通过简单的微调适应不同的任务。BERT的开源代码和预训练模型使得它成为了自然语言处理研究和应用中的重要工具。
github开源地址:https://github.com/google-research/bert
二、BERT架构
2.1 主体架构
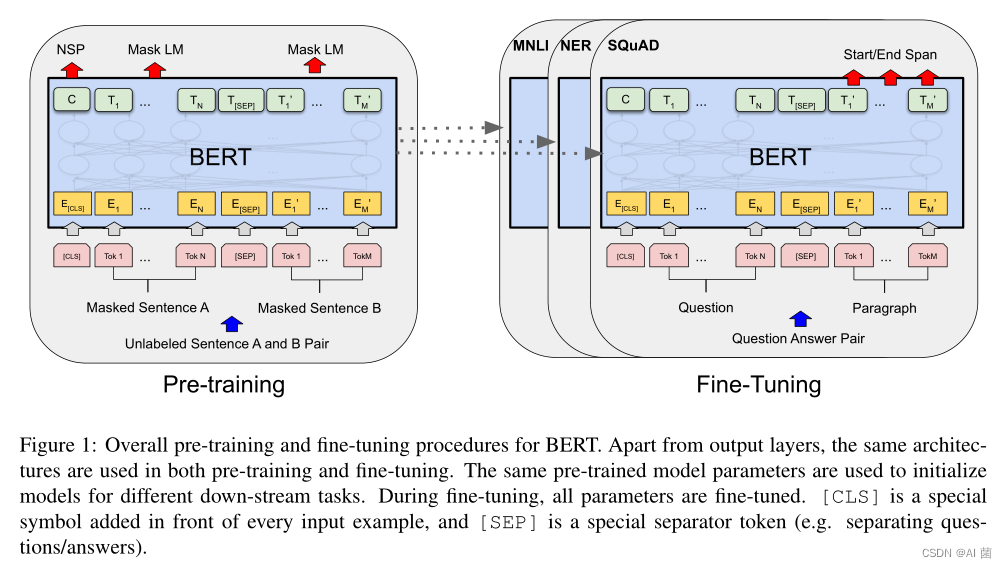
BERT 框架分为两个步骤:预训练和微调。在预训练过程中,模型在不同的预训练任务上对未标记数据进行训练。对于微调,首先使用预训练的参数初始化BERT模型,然后使用来自下游任务的标记数据对所有参数进行微调。每个下游任务都有单独的微调模型,即使它们是用相同的预训练参数初始化的。如图1所示:
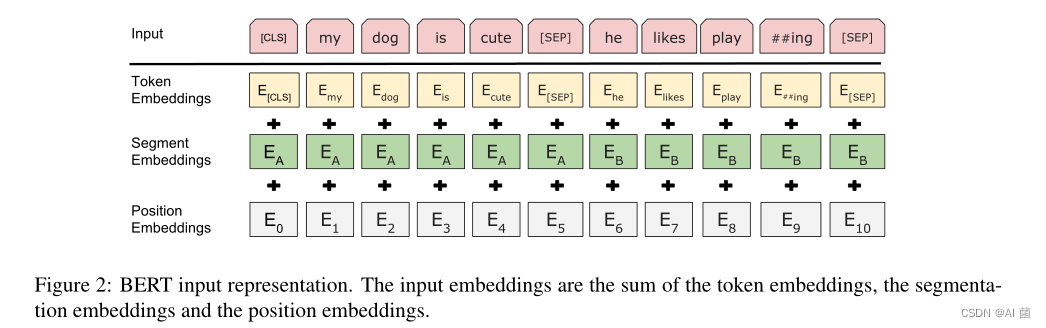
2.2 预训练方法
Task1: Masked LM (MLM)
随机屏蔽(masking)掉输入序列的部分输入token,然后只预测那些被屏蔽的token。论文将这个过程称为“masked LM”(MLM),而在其他文献中它经常被称为完形填空(Cloze)任务(Taylor, 1953)。这样做的好处是学习到的表征能够融合左右两个方向上的context。过去的同类算法在这里有所欠缺,比如ELMo模型,它用的是两个单向的LSTM然后把结果拼接起来;还有OpenAI GPT,虽然它一样使用了transformer,但是只利用了一个方向的注意力机制,本质上也一样是单项的语言模型。
不过MLM虽然确实能获得双向预训练模型,但这种方法有以下缺点:预训练和fine tuning之间可能不匹配,因为在fine tuning期间从未看到masking token。为了解决这个问题,本文并不总是用实际的masking token替换被masked的词汇。而是对于选取到的15%的词汇。例如在句子“my dog is hairy”中,它选择的token是“hairy”。执行以下过程:
- 80%的时间:用[MASK]标记替换单词,例如,my dog is hairy → my dog is [MASK]
- 10%的时间:用一个随机的单词替换该单词,例如,my dog is hairy → my dog is apple
- 10%的时间:保持单词不变,例如,my dog is hairy → my dog is hairy. 这样做的目的是将表示偏向于实际观察到的单词。
因此,通过这样的方式,Transformer编码器不知道最终要预测哪个词,更不知道输入句子对里哪个词是被随机替换成其他词了,所以它必须保留每个词语的语境表达分布信息。也就是说,要充分利用上下文信息。此外,因为随机替换只发生在所有token的1.5%(即15%的10%),这似乎不会损害模型的语言理解能力。
Task2: Next Sentence Prediction(NSP)
Next Sentence Prediction (NSP):在第一阶段MLM训练结束后,此时模型基本具备语言模型的能力,但是,在一些任务中,比如问答和常识推理,这些任务往往看重的不是模型的语言能力,而是模型能够判断句子之间的关系,因此,论文又进行了第二阶段的训练,即NSP。该训练的目的是判别给定的两个句子A和B,判断B是否是A的下一句,本文从预训练的语料库中构造了一个训练集,其中,有50%的样本中,A和B是上下文的关系,其标签为“IsNext”,有50%的样本中,B是随机从语料抽取的句子,这时两者的标签是“NotNext”,然后将A 和B拼接后输入预训练的模型进行训练
2.3、模型微调和feature-based
BERT的微调方法非常直观。在预训练阶段结束后,此时可以将模型迁移到具体的NLP任务中,由于BERT对输入进行了良好的设计,因此,迁移到很多NLP任务时需要改动的地方非常少,比如对于文本分类,则直接将文本传入序列传入模型,然后用[CLS]的输出向量C 传入输出层即可。对于配对文本的输入,比如问答、文本蕴涵等,则直接将文本作为A,B句输入模型即可,不需要做什么修改。
可以发现,BERT与ELMo和GPT等模型相比,其迁移能力和语言表达能力更强了,但是此时也有一个问题,就是模型的参数量也很庞大,此时,如果对于每一个NLP任务,都直接用预训练模型进行微调,可能会有点大材小用,因此,本文也尝试像ELMo那样,直接利用预训练模型各层的输出作为各个NLP任务的输入,然后在每个NLP任务时单独训练一个新的小型模型,即基于“Feature-based”的方法而不是“Fine-tuning”。作者以NER任务为例,选取了BERT最后四层的输出向量进行拼接,作为NER任务的输入,然后用两层BiLstm进行命名实体识别,最后发现模型效果也很强。
三、实验效果
- BERT刷新了11项NLP任务的性能记录。
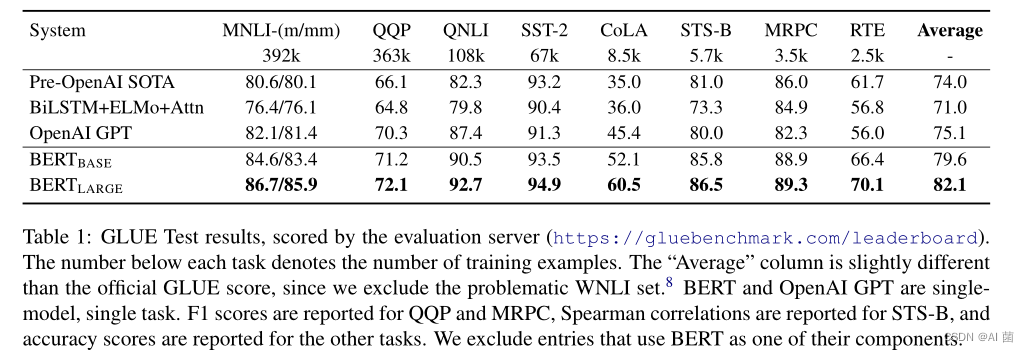
3.1 GLUE (通用语音理解能力评估)
- GLUE基准测试包含一系列不同的自然语言理解任务。在所有的GLUE任务上,作者使用了batch-size=32,epochs=3。对于每个任务,都通过开发集的验证来选择了最佳的微调学习率(在5e- 5,4e - 5,3e -5和2e-5之间)。另外,对于BERT的large模型,作者发现微调有时候在小数据集上不稳定,所以随机训练了几次,并选择了开发集上表现最佳的模型。
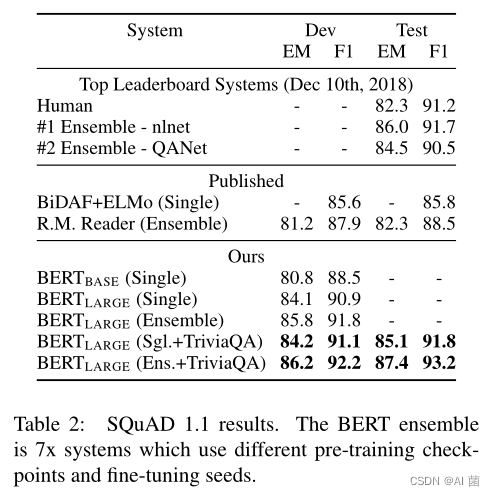
3.2 SQuAD v1.1(斯坦福问答数据集)
- 这是一个100k的问答对集合。给定一个问题和一篇短文,以及对应的答案,任务是预测出短文中的答案文本范围(the answer text span in the passage)。 本文微调了3个epochs,学习率设置为5e-5,batch-size设置为32。得到结果如下:
3.3 SWAG
- 具有对抗性生成的情况 (SWAG)数据集包含113k个句子对示例,用于评估一些基于常识的推理。任务是给定一个句子,然后从四个给出的选项中选择出最有可能是对的一个作为这个句子的延续。
- 在对SWIG数据集进行微调时,我们构建了四个输入序列,每个序列都包含给定句子(句子A)和可能的延续(句子B)的连接。引入的唯一特定于任务的参数是一个向量,它与单词的点积C表示每个选项的分数,该分数使用Softmax层进行了归一化。
- 论文对模型进行了3个阶段的微调,学习率为2E-5,batch大小为16。BERTLARGE的性能比ESIM+ELMO模型高+27.1%,比OpenAI GPT高8.3%。结果如下图:

四、模型选择
BERT(Bidirectional Encoder Representations from Transformers)是一种预训练的自然语言处理模型,它在各种NLP任务中取得了显著的成果。下面列举一些常见的BERT模型:
-
BERT-base:BERT-base是最基本的BERT模型,它包含12个Transformer编码器层,总共有110M个参数。BERT-base的输入嵌入向量维度为768,隐藏层的维度也是768。
-
BERT-large:BERT-large相对于BERT-base来说更大,它包含24个Transformer编码器层,总共有340M个参数。BERT-large的输入嵌入向量维度和隐藏层维度都是1024。
-
BERT-wwm:BERT-wwm是BERT的一种改进版本,它采用了整词(Whole Word Masking)的方式进行预训练,可以更好地处理中文的分词问题。
-
BERT-multilingual:BERT-multilingual是一种支持多语言的BERT模型,它可以同时处理多种语言的文本。该模型的预训练任务包括了来自多个语言的大规模文本。
-
BERT-uncased:BERT-uncased是将英文文本中的大写字母转换为小写字母后训练的模型。这种模型适用于不区分大小写的任务。
-
BERT-cased:BERT-cased是保留英文文本中的大小写信息后训练的模型。这种模型适用于区分大小写的任务。
-
除了以上列举的几种,还有一些其他的BERT模型,如BERT-tiny、BERT-mini等,这些模型规模更小,适用于资源受限的环境或小规模任务。
需要注意的是,BERT模型是通过预训练和微调的方式使用的,预训练任务通常是掩码语言建模(Masked Language Modeling)和下一句预测(Next Sentence Prediction)。在实际应用中,可以将预训练的BERT模型微调到特定的任务上,如文本分类、命名实体识别、情感分析等。
- 其中,L表示层数(即 Transformer blocks),H表示隐藏大小。

五、结论
本文提出了Bert模型,主要贡献有以下两点:
- 1、证明了双向预训练对语言表示模型的重要性。与之前使用的单向语言模型进行预训练不同,BERT使用掩盖语言模型来实现预训练的深度双向表示,并且取得了非常优良的效果。
- 2、BERT是第一个基于微调的表示模型,它在大量的句子级和token级任务上实现了最先进的性能,强于许多面向特定任务体系架构的系统。刷新了11项NLP任务的性能记录。并且作为预训练模型,Bert可以随时接到其他的NLP任务中进行训练。
参考资料:https://www.zhihu.com/people/wei-zhi-jiao-yu-11