目录
1. 背景
在bert之前,将预训练的embedding应用到下游任务的方式大致可以分为2种,一种是feature-based,例如ELMo这种将经过预训练的embedding作为特征引入到下游任务的网络中;一种是fine-tuning,例如GPT这种将下游任务接到预训练模型上,然后一起训练。然而这2种方式都会面临同一个问题,就是无法直接学习到上下文信息,像ELMo只是分别学习上文和下文信息,然后concat起来表示上下文信息,抑或是GPT只能学习上文信息。因此,作者提出一种基于transformer encoder的预训练模型,可以直接学习到上下文信息,叫做bert。bert base使用了12个transformer encoder block(12头注意力 隐层维度768)(bert large 使用了24个transformer encoder block,16头注意力 隐层维度1024),在13G的数据上进行了预训练,可谓是nlp领域大力出奇迹的代表。
2. Bert流程和技术细节
bert是在transformer encoder的基础之上进行改进的,因此在整个流程上与transformer encoder没有大的差别,只是在embedding,multi-head attention,loss上有所差别。
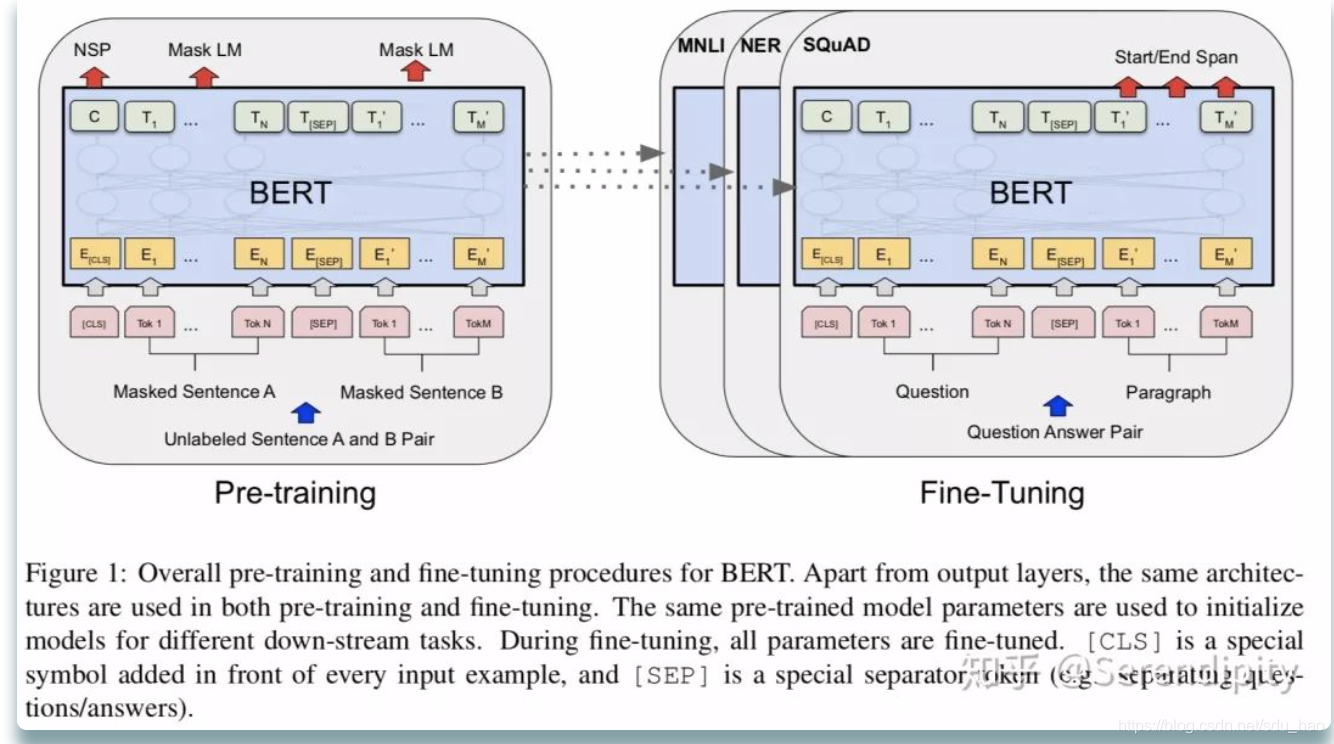
- bert和transformer在embedding上的差异
bert和transformer在embedding上的差异主要有3点:
<1> transformer的embedding由2部分构成,一个是token embedding,通过token_ids(token在词表上的索引) 在embedding matrix lookup生成表示token的向量;一个是position embedding,是通过sin和cos函数创建的定值向量。而bert的embedding由3部分构成,第一个同样是token embedding,通过token_ids在embedding matrix lookup生成表示token的向量;第二个是segment embedding,用来表达当前token是来自于第一个segment,还是第二个segment(输入是句子对时,如问答任务),因此segment vocab size是2;第三个是position embedding,与transformer不同的是,bert创建了一个position embedding matrix,通过token_ids的位置(位置索引)在position embedding matrix lookup生成表示token位置的位置向量。
为什么bert需要额外的segment embedding?
因为bert预训练的其中一个任务是判断segment A和segment B之间的关系,这就需要embedding中能包含当前token属于哪个segment的信息,然而无论是token embedding,还是position embedding都无法表示出这种信息,因此额外创建一个segment embedding matrix用来表示当前token属于哪个segment的信息,segment vocab size就是2,其中index=0表示token属于segment A,index=1表示token属于segment B。(bert中填充部分token的segment_id/token_type_ids=0)
<2> transformer在embedding之后跟了一个dropout,但是bert在embedding之后先跟了一个layer normalization,再跟了一个dropout。
为什么transformer的embedding后面接了一个dropout,而bert是先接了一个layer normalization,再接dropout?
LN是为了解决梯度消失的问题,dropout是为了解决过拟合的问题。在embedding后面加LN有利于embedding matrix的收敛。
<3> bert在token序列之前加了一个特定的token“[cls]”,这个token对应的向量后续会用在分类任务上;如果是句子对的任务,那么两个句子间使用特定的token“[seq]”来分割。尾部再接一个token“[seq]”,然后在尾部进行填充,作为模型输入(XLNet在头部填充)。
- bert和transformer在multi-head attention上的差异
bert和transformer在multi-head attention上的差异主要有2点:
<1> transformer在<4.7>会concat<4.6>的attention的结果(只拼接当前block的多头注意力结果)。而bert不仅会concat<4.6>的attention的结果,还会把前N-1个encoder block中attention的结果(多头注意力结果)都concat进来。
为什么在multi-head attention中,bert不仅会concat<4.6>的attention的结果,还会把前N-1个encoder block中attention的结果都concat进来?
有ensemble的思路在里面,比起单纯只用第N个encoder block中的attention结果,将前N个encoder block中的attention结果concat起来显然能够get到更多的信息,而下一步的linear操作又将结果的大小重新变回[batch size, max seq length, hidden size]。该问题和transformer的问题3.4的本质是一样的,通过ensemble可以得到更多的信息。
<2> transformer在<4.7>之后没有linear的操作(也可能是因为我看的transformer代码不是官方transformer的缘故),而bert在transformer的<4.7>之后有一个linear的操作。
- bert和transformer在loss上的差异
bert和transformer在loss上的差异主要有2点:
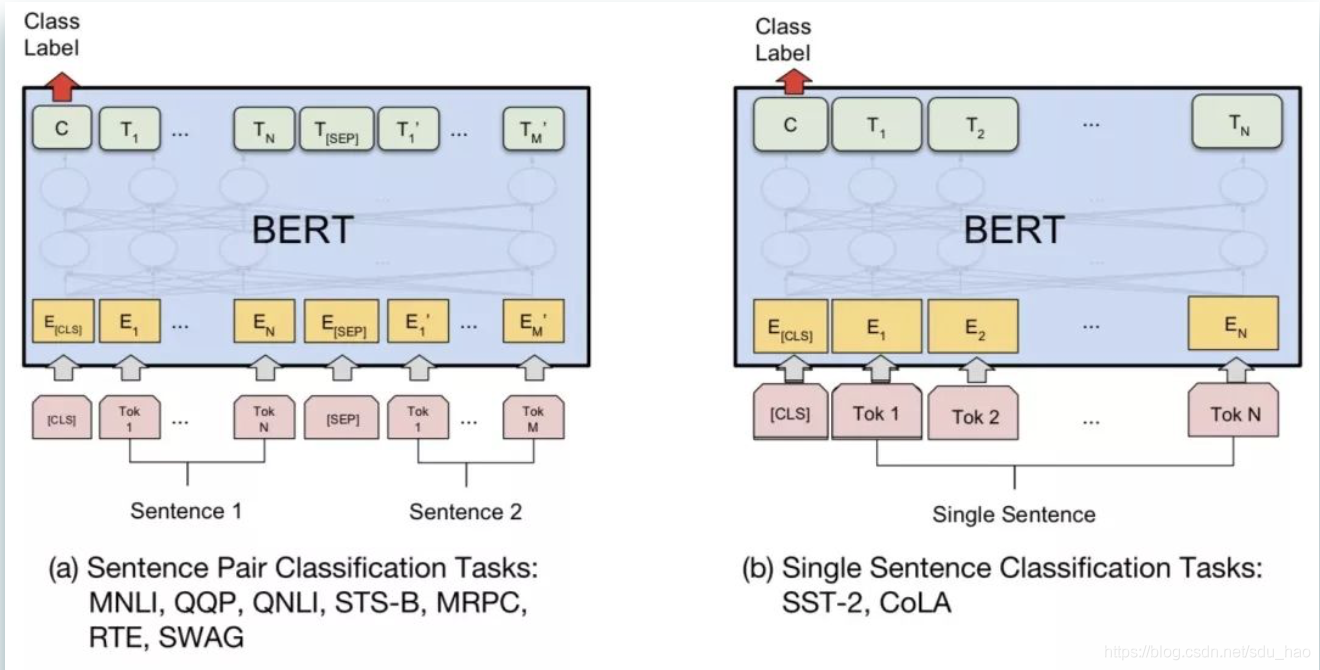
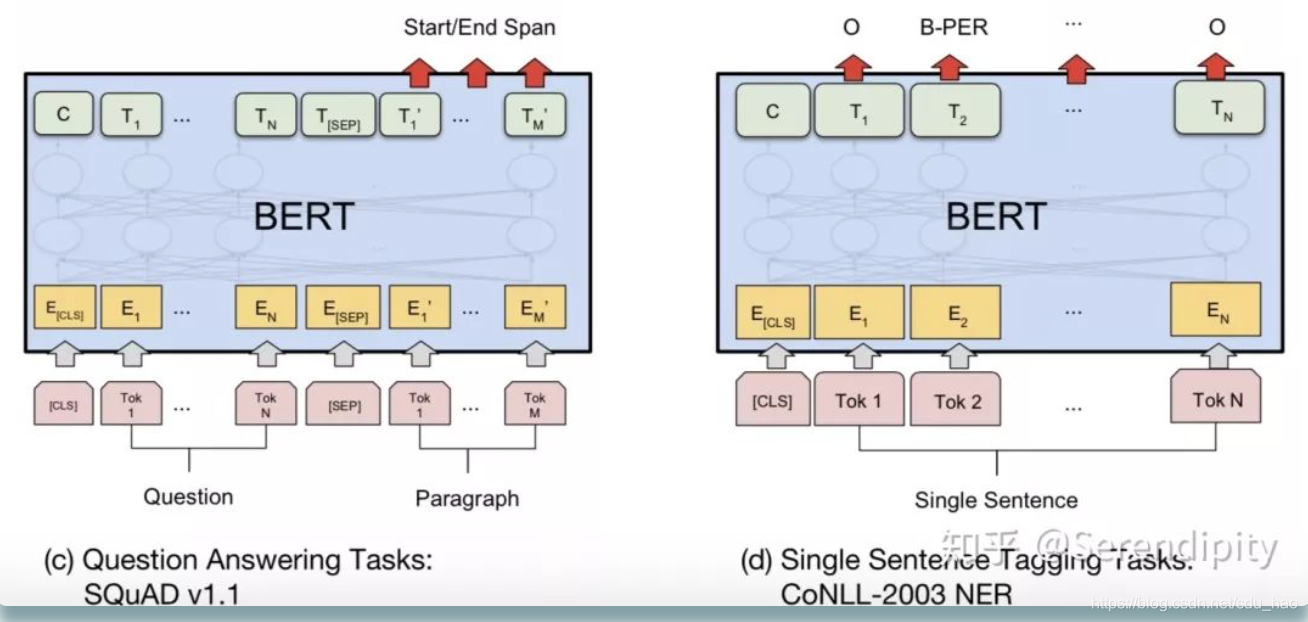
<1> transformer的loss是在decoder阶段计算的,loss的计算方式是transformer的<19>。bert预训练的loss由2部分构成,一部分是NSP的loss,就是token“[cls]”经过1层Dense,然后接一个二分类的loss,其中0表示segment B是segment A的下一句,1表示segment A和segment B来自2篇不同的文本;另一部分是MLM的loss,segment中每个token都有15%的概率被mask,而被mask的token有80%的概率用“<mask>”表示,有10%的概率随机替换成某一个token,有10%的概率保留原来的token,被mask的token经过encoder后乘以embedding matrix的转置会生成在vocab上的分布(预测被mask的token),然后计算分布和真实的token的one-hot形式的cross entropy,最后sum起来当作loss。这两部分loss相加起来当作total loss,利用adam进行训练。bert fine-tune的loss会根据任务性质来设计,例如分类任务中就是token“[cls]”经过1层Dense,然后接了一个二分类的loss;例如问题回答任务中会在paragraph上的token中预测一个起始位置,一个终止位置,然后以起始位置和终止位置的预测分布和真实分布为基础设计loss;例如序列标注,预测每一个token的词性,然后以每一个token在词性的预测分布和真实分布为基础设计loss。
为什么token被mask的概率是15%?为什么被mask后,还要分3种情况?
15%的概率是通过实验得到的最好的概率,xlnet也是在这个概率附近,说明在这个概率下,既能有充分的mask样本可以学习,又不至于让segment的信息损失太多,以至于影响mask样本上下文信息的表达。然而因为在下游任务中不会出现token“<mask>”,所以预训练和fine-tune出现了不一致,为了减弱不一致性给模型带来的影响,被mask的token有80%的概率用“<mask>”表示,有10%的概率随机替换成某一个token,有10%的概率保留原来的token,这3个百分比也是多次实验得到的最佳组合,在这3个百分比的情况下,下游任务的fine-tune可以达到最佳的实验结果。
<2> bert在encoder之后,在计算NSP和MLM的loss之前,分别对NSP和MLM的输入加了一个Dense操作,这部分参数只对预训练有用,对fine-tune没用。而transformer在decoder之后就直接计算loss了,中间没有Dense操作。
3. 总结
相比于那些说自己很好,但是在实际场景中然并软的论文,bert是真正地影响了学术界和工业界。无论是GLUE,还是SQUAD,现在榜单上的高分方法都是在bert的基础之上进行了改进。bert在nlp领域的地位可以类比cv领域的inception或者resnet,cv领域的算法效果在几年前就已经超过了人类的标注准确率,而nlp领域直到bert的出现才做到这一点。不过bert也并不是万能的,bert的框架决定了这个模型适合解决自然语言理解的问题,因为没有解码的过程,所以bert不适合解决自然语言生成的问题。因此如何将bert改造成适用于解决机器翻译,文本摘要问题的框架,是今后值得研究的一个点。
