目前市面上的教材普遍翻译得都有点问题,且经常会互相矛盾
因此主要内容参考官方的CUDA C++ Programming Guide
1 GPU的关于储存的硬件
- DRMA/HBM:这个部分的概念类似CPU的主存
- L2缓存(L2 Cache)
- L1缓存(L1 Cache)
- 寄存器(Register)
- Shared Memory
- Read-only data cache
注意:以上硬件配置可能随着GPU版本的不同产生一些变化
2 CUDA内存模型
2.1 全局内存(Global Memory)
- Global memory is large, on-board memory and is characterized by relatively high latencies.
- 可以在CPU中用
cudaMalloc动态地分配全局内存 - 可以用
__device__静态地声明
设备内存(device memory)定义出处:The CUDA programming model also assumes that both the host and the device maintain their own separate memory spaces in DRAM, referred to as host memory and device memory, respectively(感觉和全局内存定义差不多?有的教材也把这两当成一个东西)
2.2 常量内存(Constant Memory)
- The constant memory space resides in device memory and is cached in the constant cache.
- 具有常量缓存的全局内存
- 对内核代码是只读的,但它对主机是可读可写的
- 一个Wrap中访问同一个地址的前提下速度最快(广播,似乎是以半线程束的形式进行),若访问不同的地址,则访问要串行
目前关于常量缓存没有找到什么比较可靠的资料,只知道有专用的片上缓存(has a dedicated on-chip cache),并且每个SM的常量缓存有64KB的大小限制
此外Nvidia官方有个教程,内有这么一张图,猜测常量缓存应该在SM内

2.3 纹理内存/表面内存(Texture Memory/Surface Memory)
- The texture and surface memory spaces reside in device memory and are cached in texture cache
- 具有缓存的全局内存
- 只读
- 针对 2D 和 3D 局部性进行了优化,更加适合分散读取(scattered read)
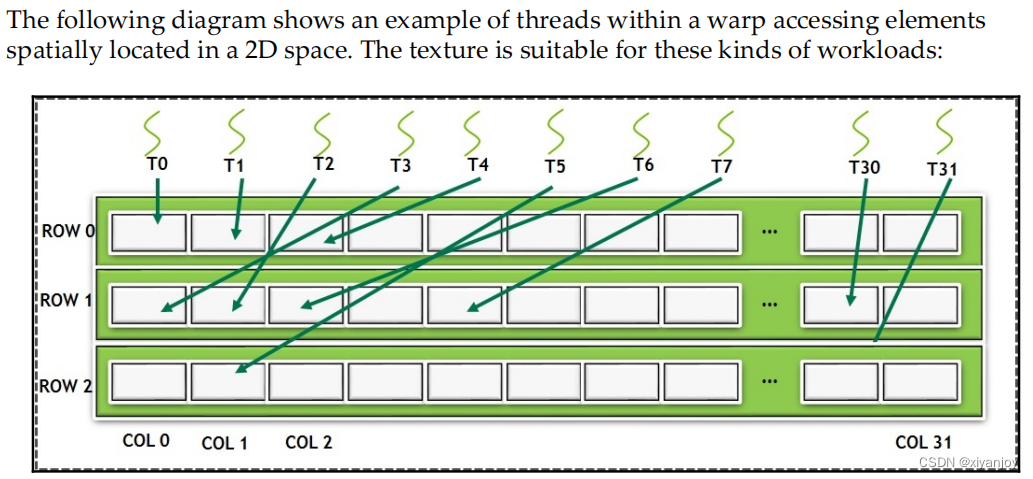
关于texture cache,①可能放在Read-only data cache;②也可能与L1缓存放一块,共享内存独立;③也可能L1 缓存、纹理缓存及共享内存三者统一起来
2.4 共享内存(Shared Memory)
- Shared memory is smaller(than Global Memory), low-latency on-chip memory
- 使用
__shared__内存空间说明符分配 - program-managed cache
- Each thread block has shared memory visible to all threads of the block and with the same lifetime as the block.
- 一个 SM 可同时运行多个板块,这时多个板块共用同一块共享内存
- 支持1D、2D、3D的共享内存数组的声明
- 注意Bank Conflict
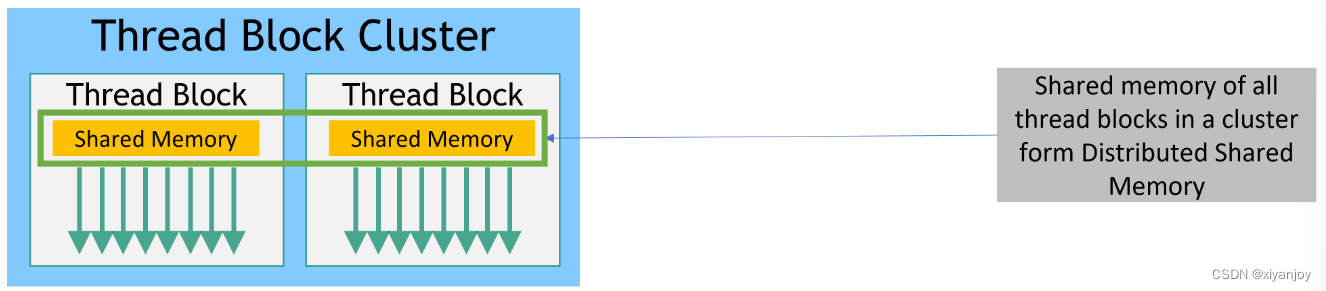
- With the introduction of NVIDIA Compute Capability 9.0, the CUDA programming model introduces an optional level of hierarchy called Thread Block Clusters that are made up of thread blocks. Thread blocks in a thread block cluster can perform read, write, and atomics operations on each other’s shared memory.
2.5 寄存器(Register)
- An automatic variable declared in device code without any of the
__device__,__shared__and__constant__memory space specifiers described in this section generally resides in a register. - 寄存器内存在芯片上(on-chip),是所有内存中访问速度最高的,但是其数量也很有限
2.6 局部内存(Local Memory)
- Each thread has private local memory.
- Automatic variables that the compiler is likely to place in local memory are:
- Arrays for which it cannot determine that they are indexed with constant quantities(索引值不能在编译时就确定的数组),
- Large structures or arrays that would consume too much register space,
- Any variable if the kernel uses more registers than available(register spilling).