GPU在管理线程的时候是以block为单元调度到SM上执行,每个block中以warp作为一次执行的单位,每个warp包括32个线程。
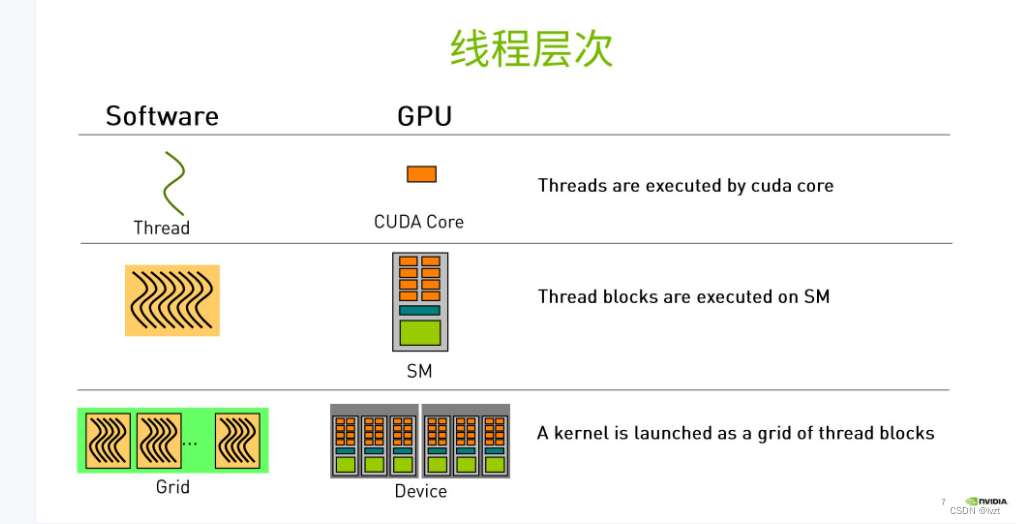
1.线程层次
Thread
thread是最基本单元,32个thread组成一个warp,一个 warp 对应一条指令流。
Thread Block: a group of threads
block内部的线程可以共享存储单元,SM是硬件层次,一个硬件SM可以执行多个blook,一个block只能在一个SM中执行
Thread Grid: a collection of thread blocks
线程网格是由多个线程块组成,每个线程块又包含若干个线程
2.多线程核函数.线程索引
通过threadIdx来得到当前的线程在线程块中的序号,通过blockIdx来得到该线程所在的线程块在grid当中的序号
threadIdx.x 是执行当前kernel函数的线程在block中的x方向的序号
blockIdx.x 是执行当前kernel函数的线程所在block,在grid中的x方向的序号
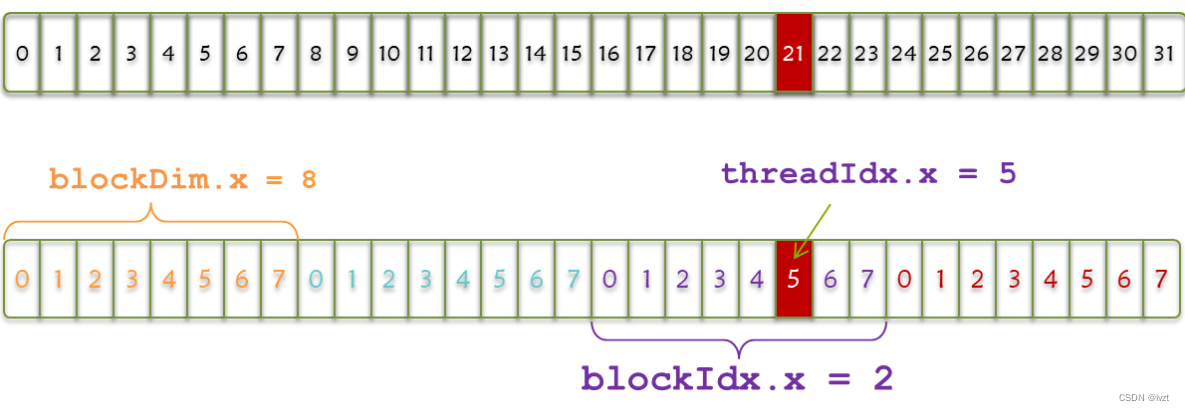
如上图所示,第一行是一个warp,32个thread,block中将其分为4组,每组8个,threadIdx.x代表组内的索引,blockIdx.x代表组索引,blockDim.x代表每组线程个数。
实验
向量加法:
CPU执行
#include <math.h>
#include <stdlib.h>
#include <stdio.h>
void add(const double *x, const double *y, double *z, const int N)
{
for (int n = 0; n < N; ++n)
{
z[n] = x[n] + y[n];
}
}
void check(const double *z, const int N)
{
bool has_error = false;
for (int n = 0; n < N; ++n)
{
if (fabs(z[n] - 3) > (1.0e-10))
{
has_error = true;
}
}
printf("%s\n", has_error ? "Errors" : "Pass");
}
int main(void)
{
const int N = 100000000;
const int M = sizeof(double) * N;
double *x = (double*) malloc(M);
double *y = (double*) malloc(M);
double *z = (double*) malloc(M);
for (int n = 0; n < N; ++n)
{
x[n] = 1;
y[n] = 2;
}
add(x, y, z, N);
check(z, N);
free(x);
free(y);
free(z);
return 0;
}
改为GPU执行
先要将数据传输给GPU,并在GPU完成计算的时候,将数据从GPU中传输给CPU内存。这时我们就需要考虑如何申请GPU存储单元,以及内存和显存之前的数据传输。
#include <math.h>
#include <stdio.h>
void __global__ add(const double *x, const double *y, double *z, int count)
{
const int n = blockDim.x * blockIdx.x + threadIdx.x;
if( n < count)
{
z[n] = x[n] + y[n];
}
}
void check(const double *z, const int N)
{
bool error = false;
for (int n = 0; n < N; ++n)
{
if (fabs(z[n] - 3) > (1.0e-10))
{
error = true;
}
}
printf("%s\n", error ? "Errors" : "Pass");
}
int main(void)
{
const int N = 1000;
const int M = sizeof(double) * N;
double *h_x = (double*) malloc(M);
double *h_y = (double*) malloc(M);
double *h_z = (double*) malloc(M);
for (int n = 0; n < N; ++n)
{
h_x[n] = 1;
h_y[n] = 2;
}
double *d_x, *d_y, *d_z;
cudaMalloc((void **)&d_x, M);
cudaMalloc((void **)&d_y, M);
cudaMalloc((void **)&d_z, M);
cudaMemcpy(d_x, h_x, M, cudaMemcpyHostToDevice);
cudaMemcpy(d_y, h_y, M, cudaMemcpyHostToDevice);
const int block_size = 128;
const int grid_size = (N + block_size - 1) / block_size;
add<<<grid_size, block_size>>>(d_x, d_y, d_z, N);
cudaMemcpy(h_z, d_z, M, cudaMemcpyDeviceToHost);
check(h_z, N);
free(h_x);
free(h_y);
free(h_z);
cudaFree(d_x);
cudaFree(d_y);
cudaFree(d_z);
return 0;
}
编译并查看结果: