1. bank conflict
本文所有的实验针对 GTX980 显卡,Maxwell 架构,计算能力 5.2。
GPU 共享内存是基于存储体切换的架构(bank-switched-architecture)。在 Femi,Kepler,Maxwell 架构的设备上有 32 个存储体(也就是常说的共享内存分成 32 个bank),而在 G200 与 G80 的硬件上只有 16 个存储体。
每个存储体(bank)每个周期只能指向一次操作(一个 32bit 的整数或者一个单精度的浮点型数据),一次读或者一次写,也就是说每个存储体(bank)的带宽为 每周期 32bit。
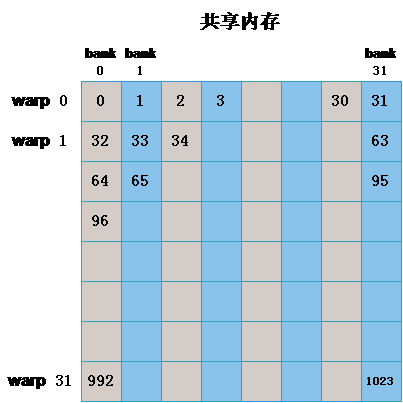
如下图所示,在一个线程块中申请如下的共享内存:
__shared__ float sData[32][32];- 1
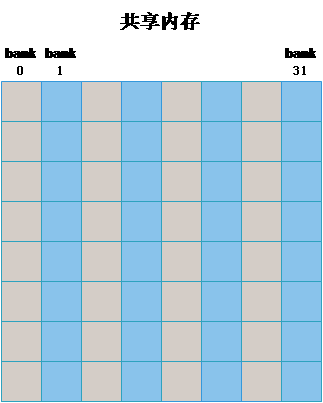
也就是说在上述的 32 * 32 的二维数组共享内存中,每一列对应同一个 bank。
- 同常量内存一样,当一个 warp 中的所有线程访问同一地址的共享内存时,会触发一个广播(broadcast)机制到 warp 中所有线程,这是最高效的。
- 如果同一个 warp 中的线程访问同一个 bank 中的不同地址时将发生 bank conflict。
- 每个 bank 除了能广播(broadcast)还可以多播(mutilcast)(计算能力 >= 2.0),也就是说,如果一个 warp 中的多个线程访问同一个 bank 的同一个地址时(其他线程也没有访问同一个bank 的不同地址)不会发生 bank conflict。
- 即使同一个 warp 中的线程 随机的访问不同的 bank,只要没有访问同一个 bank 的不同地址就不会发生 bank conflict。
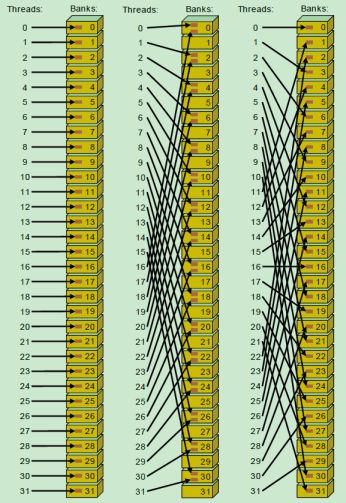
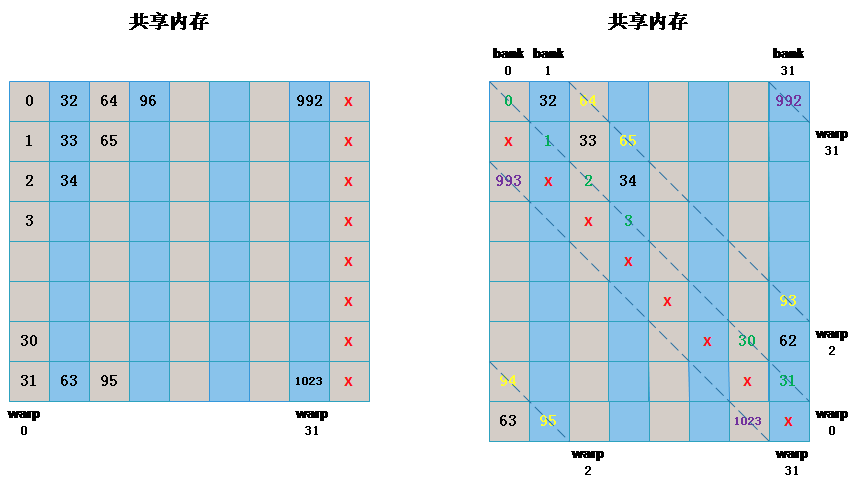
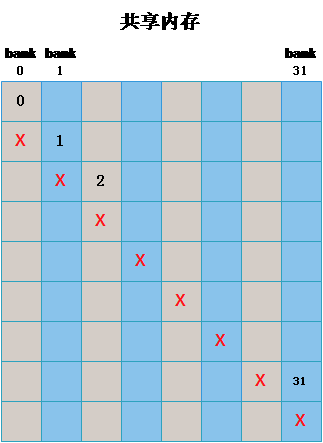
如上图所示,左侧和右侧的都没有发生 bank conflict。而中间的存在 bank conflcit,由于经过最多两次,该 warp 中的线程就都可以得到所要的数据,所有称为 2-way bank conflict,如果同一个 warp 中的所有线程访问一个 bank 中的 32 个不同地址,则需要分 32 次,称为 32-way bank conflict。
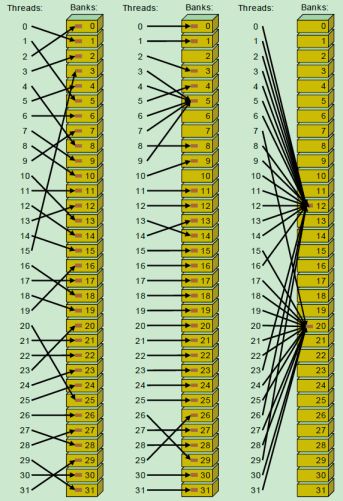
如上图所示,左中右均未发生 bank conflict。
依次我们可以总结:只要同一个 warp 的不同线程会访问到同一个 bank 的不同地址就会发生 bank conflict,除此之外的都不会发生 bank conflict。
既然广播是针对同一个 warp 而言的,那么如果不同的 warp 访问同一个 bank 中的同一个地址呢?由于 每个 SM 中有 4 个 warp scheduler (GTX980),可以很好的调度 warp,使其 warp 之间的访问冲突可以充分的隐藏,因此对效率的影响很小,远远小于 warp 内的 bank conflict。至于 warp scheduler 的调度机制,NVIDIA 没有说的特别清楚,可能也是想要开发者不要过于关注于此。
2. 实验 1
实现定义如下图所示的 32 * 32 线程块,共 1024 个线程,32 个 warp。
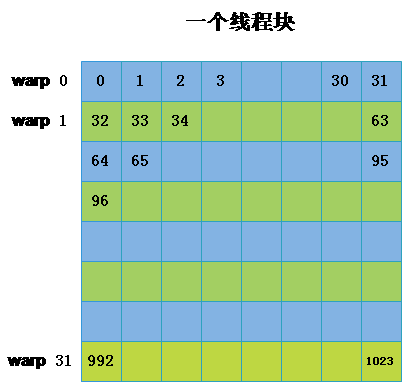
申请如 1 中所示的 32 * 32 的共享内存,共 32 个 bank,每个 bank 对应 32 个元素。
- 实验 1.1
该线程块中的每个 warp 读写不同的 bank,不同的 warp 不会访问一个地址,也就是一一对应的关系。图中的数字就表示上图中的线程标号。经分析可知,此时是没有 bank conflict 的。
代码如下:
int x_id = blockDim.x * blockIdx.x + threadIdx.x; // 列坐标
int y_id = blockDim.y * blockIdx.y + threadIdx.y; // 行坐标
int index = y_id * col + x_id;
__shared__ float sData[BLOCKSIZE][BLOCKSIZE];
if (x_id < col && y_id < row)
{
sData[threadIdx.y][threadIdx.x] = matrix[index];
__syncthreads();
matrixTest[index] = sData[threadIdx.y][threadIdx.x];
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 实验 1.2
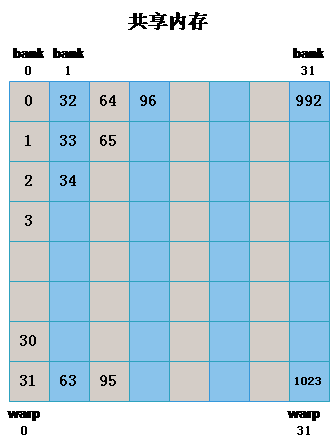
该线程块中的每个 warp 读写相同的 bank 的不同地址,不同的 warp 访问不同,也就是一一对应的关系。图中的数字就表示上图中的线程标号。经分析可知,此时是存在很严重的 bank conflict 。
代码如下:
int x_id = blockDim.x * blockIdx.x + threadIdx.x; // 列坐标
int y_id = blockDim.y * blockIdx.y + threadIdx.y; // 行坐标
int index = y_id * col + x_id;
__shared__ float sData[BLOCKSIZE][BLOCKSIZE];
if (x_id < col && y_id < row)
{
sData[threadIdx.x][threadIdx.y] = matrix[index];
__syncthreads();
matrixTest[index] = sData[threadIdx.x][threadIdx.y];
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 实验 1.3(避免 bank conflict 的技巧)
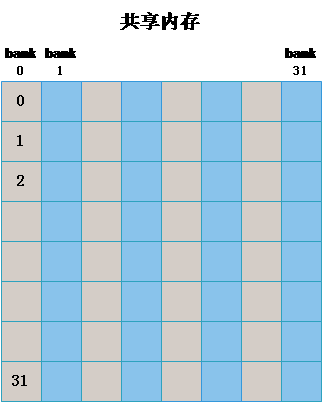
针对实验 1.2 中出现的严重的 bank conflict,我们可以通过添加一个附加列来避免 bank conflict,如下图所示,左图为申请的共享内存矩阵形式,右图是表示成 bank 后的形式,通过这种方式,原来在一个 bank 中的同一个 warp 都正好偏移到了不同的 bank 中。
代码如下:
int x_id = blockDim.x * blockIdx.x + threadIdx.x; // 列坐标
int y_id = blockDim.y * blockIdx.y + threadIdx.y; // 行坐标
int index = y_id * col + x_id;
__shared__ float sData[BLOCKSIZE][BLOCKSIZE+1];
if (x_id < col && y_id < row)
{
sData[threadIdx.x][threadIdx.y] = matrix[index];
__syncthreads();
matrixTest[index] = sData[threadIdx.x][threadIdx.y];
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
上述三个小实验的运行时间为:
实验 1.1 :0.052416 ms
实验 1.2 :0.131072 ms
实验 1.3 :0.053280 ms- 1
- 2
- 3
除去公共代码后的时间为:
实验 1.1 :0.034816 ms
实验 1.2 :0.113472 ms
实验 1.3 :0.035680 ms- 1
- 2
- 3
结论:
- 通过额外的一行,可以避免 bank conflict,运行时间与完全没有 bank conflict 的运行时间差距很小。
- 存在 bank conflict 的,运行时间几乎是没有 bank conflict 的运行时间的 4 倍。
其实只要添加的是奇数列就可以,只不过 1 列是最节省空间(共享内存太宝贵)的。
3. 实验 2
- 实验 2.1
同一个 block 中所有第 i 列的线程都计算第 i 行的元素的和,此时所有同一个warp 会访问同一个 bank 的不同地址。如下图所示,分别表示第 0 列访问 bank 0 中的第一个地址,第 1 列访问 bank 1 中的第 1 个地址,依次类推。
代码如下:
int x_id = blockDim.x * blockIdx.x + threadIdx.x; // 列坐标
int y_id = blockDim.y * blockIdx.y + threadIdx.y; // 行坐标
int index = y_id * col + x_id;
__shared__ float sData[BLOCKSIZE][BLOCKSIZE];
if (x_id < col && y_id < row)
{
sData[threadIdx.y][threadIdx.x] = matrix[index];
__syncthreads();
float data = 0.0f;
for (int j = 0; j < BLOCKSIZE; j++)
{
data += sData[threadIdx.x][j];
}
matrixTest[index] = data;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 实验 2.2
同实验 1.3 类似,添加额外的一列,如下图所示:
int x_id = blockDim.x * blockIdx.x + threadIdx.x; // 列坐标
int y_id = blockDim.y * blockIdx.y + threadIdx.y; // 行坐标
int index = y_id * col + x_id;
__shared__ float sData[BLOCKSIZE][BLOCKSIZE+1];
if (x_id < col && y_id < row)
{
sData[threadIdx.y][threadIdx.x] = matrix[index];
__syncthreads();
float data = 0.0f;
for (int j = 0; j < BLOCKSIZE; j++)
{
data += sData[threadIdx.x][j];
}
matrixTest[index] = data;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
上述两个实验的运行时间如下所示:
实验 2.1 :0.458144 ms
实验 2.2 :0.090848 ms- 1
- 2
从上图也可以看出,修改后的带宽相当于修改前的 32 倍。修改后的运行时间也明显得到改善。
4. 实验 3
- 实验 3.1
采用实验 1.1 的方式,同一个 warp 访问不同的 bank,不同的 warp 访问不同的地址。
代码如下:
int x_id = blockDim.x * blockIdx.x + threadIdx.x; // 列坐标
int y_id = blockDim.y * blockIdx.y + threadIdx.y; // 行坐标
int index = y_id * col + x_id;
__shared__ float sData[BLOCKSIZE][BLOCKSIZE];
if (x_id < col && y_id < row)
{
sData[threadIdx.y][threadIdx.x] = matrix[index];
__syncthreads();
float data = 0.0f;
for (int j = 0; j < 1000; j++)
{
data = sData[threadIdx.y][threadIdx.x];
}
matrixTest[index] = data;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 实验 3.2
同一个 warp 访问不同的 bank,所有 warp 访问同一个地址,也就是说所有的行都会访问第 0 行。
代码如下:
int x_id = blockDim.x * blockIdx.x + threadIdx.x; // 列坐标
int y_id = blockDim.y * blockIdx.y + threadIdx.y; // 行坐标
int index = y_id * col + x_id;
__shared__ float sData[BLOCKSIZE][BLOCKSIZE];
if (x_id < col && y_id < row)
{
sData[threadIdx.y][threadIdx.x] = matrix[index];
__syncthreads();
float data = 0.0f;
for (int j = 0; j < 1000; j++)
{
data = sData[0][threadIdx.x];
}
matrixTest[index] = data;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
上述两个实验的运行时间如下所示:
实验 2.1 :0.053800 ms
实验 2.2 :0.055328 ms- 1
- 2
在实验 2.2 中存在明显的不同 warp 间的冲突,但是运行时间差距很小,也就是说 warp 间冲突的影响很小。
5. visual profiler
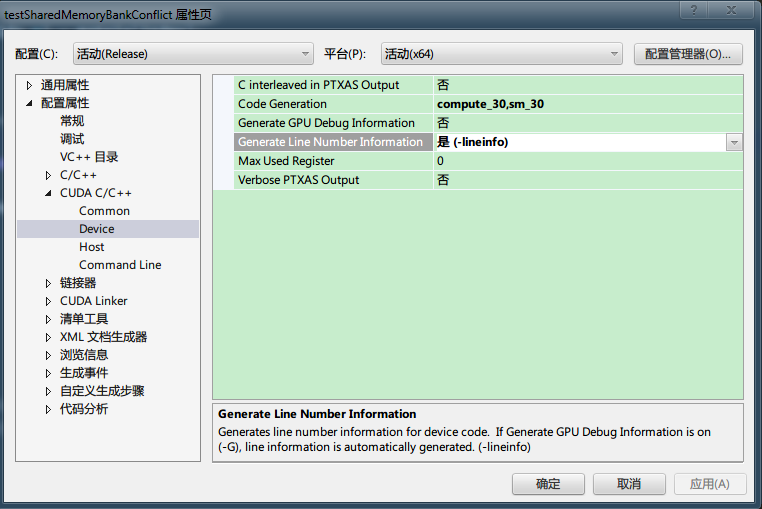
通过 visual profiler 可以判断程序中是否存在 bank conflict,在运行 visual profiler 前需要添加 -lineinfo选项,在 visual studio 中可以设置,如下所示:
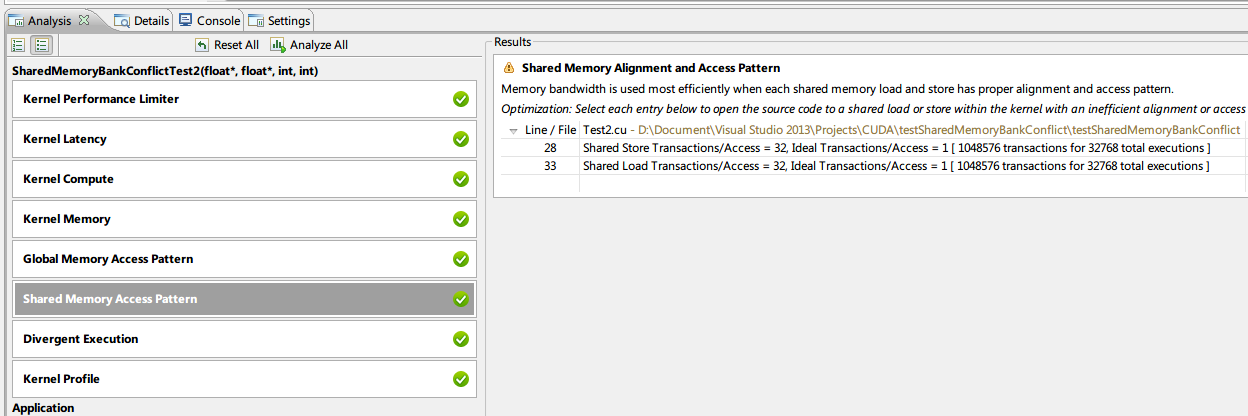
在 visual profiler 中分析实验 1.2,结果如下所示,可以直接定位到出现 bank conflict 的行。
6. 完整代码
7. 参考
- 《CUDA_C_Programming_Guide》7.0 Appendix G. COMPUTE CAPABILITIES / 4.1 / 4.2
- 《CUDA_C_Best_Practices_Guide》7.0
- 《CUDA 并行程序设计:GPU编程指南》6.4
- 《GPU 高性能运算之 CUDA》4.7.1.3/4.4.3
- 《Performance modeling of atomic additions on
GPU scratchpad memory》 - 《stackoverflow》
--------------------- 作者:木子超同学 来源:CSDN 原文:https://blog.csdn.net/endlch/article/details/47043069?utm_source=copy 版权声明:本文为博主原创文章,转载请附上博文链接!