内容目录
前言
图片来自于网络,若涉及侵权,私信作者删除(希尔排序图片被表记为可能被保护,其他均被标记为 创做共用)
希望点赞,互关~
后续内容函数声明(.h文件内容)
#pragma once
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
#include <string.h>;
#include <windows.h>
#include <windows.h>
#include <time.h>
#include <assert.h>
#include<stdbool.h>
//!!!!!所有的排序都以排升序为列! ! ! ! ! !
//堆排序
typedef int HPDataType;
typedef struct Heap
{
HPDataType* arr;
int size;
int capacity;
}HP;
// 堆的插入 //插入后还是堆
void HeapSort(int* a, int size);
//向下调整
void AdjustDown(int* a, int n, int root);
//数组打印
void Print(int* a,int size);
//冒泡排序
void BubbleSort(int* a, int size);
//插入排序
void InsertSorting(int* a, int size);
//希尔排序
void ShellSort(int* a,int size);
//快速排序 递归写法 hoare版本
void QuickSort(int* a, int begin, int end);
//快速排序 递归写法 挖坑法
void QuickSort1(int* a, int begin, int end);
//单次排序
int PartSort(int* a, int begin, int end);
//快速排序 非递归写法 用队列存下标
void QuickSort2(int* a, int left, int right);
//归并排序 // 递归写法
void MergeSort(int* a, int n);
//归并排序的子函数
void _MergeSort(int* a, int* tmp, int begin, int end);
//归并排序 非递归写法 边界调整法
void MergeSort2(int* a, int n);
//计数排序 //利用下标存数值,下标代表数,下标里的值是下标代表的数出现的次数
void CountSort(int* arr, int n);
//因为快速排序要用到堆(stack),故以下为堆相关操作声明
typedef int STDataType;
typedef struct Stack {
STDataType* a;
int top;
int capacity;
}ST;
void StackInit(ST* ps);
//初始化
void StackDestory(ST* ps);
//销毁
void StackPush(ST* ps, STDataType x);
//入栈
void StackPop(ST* ps);
//出栈
STDataType StackTop(ST* ps);
//返回栈顶元素
int StackSize(ST* ps);
//计算数据个数
bool StackEmpty(ST* ps);
//判断是否为空
void StackInit(ST* ps);
//初始化
冒泡排序
思路简述:最基础的排序方法通过交换相邻两个元素的位置来排序,每一轮都将最大(或小)的元素放到最后。

代码实现:
#include"Sort .h"
void Swap(int* a,int* b)
{
int tem = *a;
*a = *b;
*b = tem;
return;
}
//冒泡排序
void BubbleSort(int* a, int size)
{
int j = 0; // j 是用来针对数组本身就有序或很接近有序的情况的优化
while (size > 1)
{
for (int i = 0; i < size - 1; i = i + 1)
{
if (a[i] > a[i + 1])
{
Swap(&a[i], &a[i + 1]);
j = 1;
}
}
size = size - 1;
if (j == 0 ) //如果一次遍历没发生过交换那么数组有序,不需要在进行冒泡了
{
break;
}
}
}
- 时间复杂度:O(n^2)
- 空间复杂度:O(1)
- 稳定性:稳定
- 优点:简单易写,空间复杂度低
- 缺点:效率较低,不适用于数据量较大的情况
插入排序
类似于打扑克牌时摸牌并排序,原理是将未排序部分的每一个元素插入到已排序部分中合适的位置。

代码实现:
//插入排序
//核心思想:类似于打扑克,每次摸到一张牌都插入合适位置;
void InsertSorting(int* a, int size)
{
for (int i = 0; i < size - 1; i++)
{
int cur = i;
int tem = a[i + 1];
while (cur >= 0)
{
if (tem < a[cur]) //
{
a[cur + 1] = a[cur];
cur = cur - 1;
}
else
{
break;
}
}
a[cur + 1] = tem;
}
}
- 时间复杂度:O(n^2)
- 空间复杂度:O(1)
- 稳定性:稳定
- 优点:简单易写,对于基本有序的数组来说效率较高
- 缺点:对于大规模数据的排序效率较低,内存开支较大
希尔排序
思路:希尔排序是一种优化的插入排序算法,它的思路是将数组分成若干个子序列进行插入排序,最终将整个序列进行一次插入排序。(插入排序的gap一直为1,希尔是在插入排序的基础上进行了预先排序)

代码实现:
//希尔排序
void ShellSort(int* a, int size)
{
int gap = size ;
while (gap > 1)
{
gap = gap / 2;
for (int i = 0; i < size - gap;i = i + 1) //这里改为i=i+1 //因为其实无论gap是几,从一到size-gap 都要被插排一次,只不过插排顺序从一组第一个,一组第二个……变成了一组第一个,二组第一个……
{
int cur = i;
int tem = a[cur + gap];
while (cur >= 0)
{
if (a[cur] > tem)
{
a[cur + gap] = a[cur];
cur = cur - gap;
}
else
{
break;
}
a[cur + gap] = tem;
}
}
}
}
- 时间复杂度:O(n^1.3)
- 空间复杂度:O(1)
- 稳定性:不稳定
- 优点:相对于插入排序来说,对于大规模数据的排序效率较高
- 缺点:复杂度分析较困难
选择排序
思路简述: 原理是每一轮找到最小的元素,然后将它放到当前未排序部分的最前面。

代码实现:
//选择排序
void SelectSort(int* a, int size)
{
int left = 0;
int right = size - 1;
while (left < right)
{
int cur_min = left;
int cur_max = right;
int cur_left = left;
int cur_right = right;
int min = a[left];
int max = a[right];
while (cur_left <= right)
{
if (a[cur_left] < min)
{
cur_min = cur_left;
min = a[cur_min];
}
cur_left = cur_left + 1;
}
while (cur_right >= left)
{
if (a[cur_right] > max)
{
cur_max = cur_right;
max = a[cur_max];
}
cur_right = cur_right -1 ;
}
a[cur_max] = a[right];
a[cur_min] = a[left];
a[left] = min;
a[right] = max;
left = left + 1;
right = right - 1;
}
}
- 时间复杂度:O(n^2)
- 空间复杂度:O(1)
- 稳定性:不稳定
- 优点:简单易写,空间复杂度低
- 缺点:效率较低,不适用于数据量较大的情况
堆排序
基于堆的数据结构的排序算法,它的基本思路是将待排序数组构造成一个最大堆,然后将堆顶元素取出并删除(删除即是每次把最大数放入末尾,下次不再将其带入排序),循环这个过程。

代码实现:
typedef int HPDataType;
typedef struct Heap
{
HPDataType* arr;
int size;
int capacity;
}HP;
// 堆的插入 //插入后还是堆
void HeapSort(int* a, int size);
//向下调整
void AdjustDown(int* a, int n, int root);
void AdjustDown(int* a, int n, int root)
{
int parent = root;
int child = parent * 2 + 1;
//孩子超过数组下标结束
while (child < n)
{
//child始终左右孩子中小的那个
if (a[child + 1] > a[child] && child + 1 < n)//防止没有右孩子
{
++child;
}
//小的往上浮,大的往下浮
if (a[child] > a[parent])
{
int tem = a[parent];
a[parent] = a[child];
a[child] = tem;
parent = child;
child = parent * 2 + 1;
}
//中途child>parent则已满足小堆,直接break
else
{
break;
}
}
}
void HeapSort(int* a, int size)
{
for (int i = (size - 1 - 1) / 2; i >= 0; i = i - 1)
{
AdjustDown(a, size, i);
}
for (int i = size - 1; i > 0; i = i - 1)
{
int tem = a[i];
a[i] = a[0];
a[0] = tem;
AdjustDown(a, i, 0);
}
}
- 时间复杂度:O(nlogn)
- 空间复杂度:O(1)
- 稳定性:不稳定
- 优点:效率较高,常用于大规模数据的排序
- 缺点:不稳定,需要额外的空间开销
快速排序(1.hoare-递归写法 2.挖坑-递归写法 3.非递归写法)
简述思路: 快速排序是一种基于分治思想的排序算法,它的基本思路是选择一个元素作为基准(key),然后将数组中小于基准的元素都放在基准的左边,大于等于基准的元素都放在基准的右边,在左右两个部分分别递归地进行排序(非递归写法也是模拟以模拟递归的思路去写,优点是不用考虑栈溢出)。
总思路图:

挖坑法思路:
先将key值存储起来,key起始位置为第一个坑,key值选取的对面先走,对面走到比key小的位置上,把其内容抛入坑中,这样又出来一个坑,按此循环,最后将key值填入最后一个坑
非递归法思路:
类似于二叉树的层序遍历,用stack存储下次要排序的区间下标。
代码实现:
//快速排序 递归写法 hoare版本
void QuickSort(int* a, int begin, int end)
{
if (begin >= end)
{
return;
}
int right = begin;
int left = end;
int k = a[begin]; //定了左边为k则对面先走
int ki = begin;
while (right < left)
{
while (right < left)
{
if (a[left] < k)
{
break;
}
left = left - 1;
}
while (right < left)
{
if (a[right] > k)
{
break;
}
right = right + 1;
}
Swap(&a[right], &a[left]);
}
Swap(&a[ki], &a[left]);
QuickSort(a, begin, right);
QuickSort(a, right + 1, end);
}
//快速排序 递归写法 挖坑法
void QuickSort1(int* a, int begin, int end)
{
if (begin >= end)
{
return;
}
int k = a[begin];
int left = begin;
int right = end;
int pit = begin;
while (left < right)
{
while (left < right)
{
if (a[right] < k)
{
a[pit] = a[right];
pit = right;
break;
}
right = right - 1;
}
while (left < right)
{
if (a[left] > k)
{
a[pit] = a[left];
pit = left;
break;
}
left = left + 1;
}
}
a[pit] = k;
QuickSort1(a, begin, pit - 1);
QuickSort1(a, pit + 1, end);
}
/*单次排序 */ //用于非递归写法内部,返回值为相遇位置下标
int PartSort(int* a, int begin, int end)
{
int right = begin;
int left = end;
int k = a[begin]; //定了左边为k则对面先走
int ki = begin;
while (right < left)
{
while (right < left)
{
if (a[left] < k)
{
break;
}
left = left - 1;
}
while (right < left)
{
if (a[right] > k)
{
break;
}
right = right + 1;
}
Swap(&a[right], &a[left]);
}
Swap(&a[ki], &a[left]);
return left;
}
//快速排序,非递归写法
void QuickSort2(int* a, int left, int right)
{
// 栈
ST st;
StackInit(&st);
StackPush(&st, left);
StackPush(&st, right);
while (!StackEmpty(&st))
{
int end = StackTop(&st);
StackPop(&st);
int begin = StackTop(&st);
StackPop(&st);
// 单趟排序
int keyi = PartSort(a, begin, end);
// 先入右区间
if (keyi + 1 < end)
{
StackPush(&st, keyi + 1);
StackPush(&st, end);
}
// 再入左区间
if (begin < keyi - 1)
{
StackPush(&st, begin);
StackPush(&st, keyi - 1);
}
}
StackDestory(&st);
}
- 时间复杂度:O(nlogn)
- 空间复杂度:O(logn)
- 稳定性:不稳定
- 优点:效率较高,常用于大规模数据的排序
- 缺点:最坏情况下时间复杂度达到O(n^2),需要优化
归并排序(1.递归写法 2。非递归写法)
思路简述:基本思路是将待排序数组划分成若干个子数组,对每一个子数组进行排序,最终将这些有序子数组合并成一个有序的数组。

实现具体过程抽象思路:

代码实现:(非递归写法用for循环模拟递归,非递归写的写法难点在于越界问题,所以边界调整部分是难点)
//归并排序 递归写法
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc((sizeof(int) * n));
if (tmp == NULL)
{
printf("malloc fail");
exit(-1);
}
_MergeSort(a, tmp, 0, n - 1);
free(tmp);
tmp = NULL;
}
void _MergeSort(int* a, int* tmp, int begin, int end)
{
if (begin >= end) //但个或不存在即返回
{
return;
}
int tmpi = begin;
int begin1 = begin;
int end1 = (begin + end) / 2;
int begin2 = (begin + end) / 2 + 1;
int end2 = end;
_MergeSort(a, tmp, begin1, end1);
_MergeSort(a, tmp, begin2, end2);
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[tmpi] = a[begin1];
tmpi = tmpi + 1;
begin1 = begin1 + 1;
}
else
{
tmp[tmpi] = a[begin2];
tmpi = tmpi + 1;
begin2 = begin2 + 1;
}
}
while (begin1 <= end1)
{
tmp[tmpi] = a[begin1];
tmpi = tmpi + 1;
begin1 = begin1 + 1;
}
while (begin2 <= end2)
{
tmp[tmpi] = a[begin2];
tmpi = tmpi + 1;
begin2 = begin2 + 1;
}
//因为往上递归还是要从原数组中拿数据,拿到的数据须是有序的,故立刻将排好的放入原数组
while (begin <= end)
{
a[begin] = tmp[begin];
begin = begin + 1;
}
}
//归并排序 非递归写法 边界调整法
void MergeSort2(int* a, int n) //注意传进来的是数组大小,不是末尾下标
{
int* tmp = (int*)malloc((sizeof(int) * n));
if (tmp == NULL)
{
printf("malloc fail");
exit(-1);
}
int gap = 1; //模拟递归一开始两个两个数的比较
while (gap < n)
{
for (int i = 0; i < n;i = i + (2 * gap))
{
int tmpi = i;
int begin1 = i;
int end1 = i + gap - 1;
int begin2 = i + gap;
int end2 = i + 2 * gap - 1;
//边界调整部分
//因为进入for循环的条件为 i < n 故begin1必定不会越界
if (end1 >= n)
{
end1 = n - 1;
begin2 = 1;
end2 = 0;
}
if (begin2 >= n)
{
begin2 = 1;
end2 = 0;
}
if (end2 >= n)
{
end2 = n - 1;
}
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[tmpi] = a[begin1];
tmpi = tmpi + 1;
begin1 = begin1 + 1;
}
else
{
tmp[tmpi] = a[begin2];
tmpi = tmpi + 1;
begin2 = begin2 + 1;
}
}
while (begin1 <= end1)
{
tmp[tmpi] = a[begin1];
tmpi = tmpi + 1;
begin1 = begin1 + 1;
}
while (begin2 <= end2)
{
tmp[tmpi] = a[begin2];
tmpi = tmpi + 1;
begin2 = begin2 + 1;
}
}
for (int j = 0; j < n - 1; j++)
{
a[j] = tmp[j];
}
gap = gap * 2;
}
}
- 时间复杂度:O(nlogn)
- 空间复杂度:O(n)
- 稳定性:稳定
- 优点:效率较高且稳定,适用于大规模数据的排序
- 缺点:需要额外的空间开支
计数排序
基本思路:利用下标存数值,下标代表数,下标里的值是下标代表的数值出现的次数,
(前面的过程本质是存储)上述过程完成之后,放入原数组。
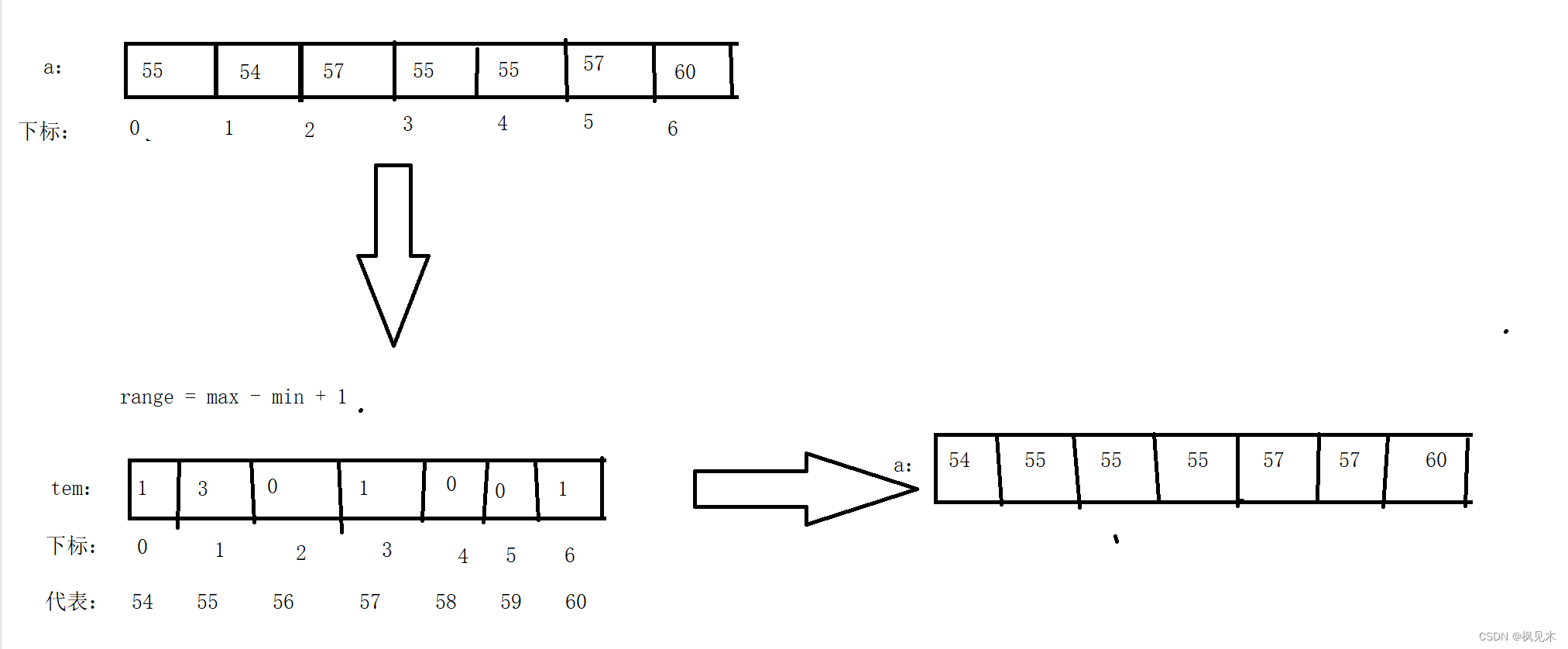
代码实现:
//计数排序 //利用下标存数值,下标代表数,下标里的值是下标代表的数出现的次数
void CountSort(int* arr, int n)
{
int i = 0;
int min = arr[0];
int max = arr[0];
//先遍历一遍求出出最大值和最小值,以便于后续确定范围range
while (i < n)
{
if (arr[i] < min)
{
min = arr[i];
}
if (arr[i > max])
{
max = arr[i];
}
i = i + 1;
}
//range为开辟数组的大小
int range = max - min + 1;
int* tem = (int*)malloc((sizeof(int) * range));
if (tem == NULL)
{
printf("malloc fail");
exit(-1);
}
//想用tem数组的下标来计数需先将其内容全部初始化为0
memset(tem, 0, sizeof(int) * range);
i = 0;
while ( i < n)
{
tem[arr[i] - min] = tem[arr[i] - min] + 1;
i = i + 1;
}
//已存储完成,存的是相对位置,因为这样可节省空间,开始从小到大输入原数组
i = 0; //在tem里走
int j = 0; //在arr里走
while (i < range)
{
while (tem[i] != 0)
{
arr[j] = i + min; //因为存的是相对位置 + min 才是原数值
j = j + 1;
tem[i] = tem[i] - 1;
}
i = i + 1;
}
free(tem);
}
计数排序的时间复杂度和最大数据与最小数据的差值有关
优点:最大数据与最小数据的差值较小排序能展现出优势
缺点:不适应最大数据与最小数据的差值较大的
稳定性:稳定
写在最后
本人为小白,水平有限,如有错误不足,恳请指出。