1. 熟悉排序的相关概念:什么是排序,排序的稳定性,内部排序与外部排序
排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。
稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。
选择排序、快速排序、希尔排序、堆排序不是稳定的排序算法
冒泡排序、插入排序、归并排序和基数排序都是稳定的排序算法。
内部排序:数据元素全部放在内存中的排序。
外部排序:数据元素太多不能同时放在内存中,根据排序过程的要求不能在内外存之间移动数据的排序。
2. 熟悉插入、希尔、选择、堆排、冒泡、归并、计数、基数排序的以下内容:
排序原理、代码实现、稳定性、时间空间复杂度、应用场景
插入排序:直接插入排序是一种简单的插入排序法,其基本思想是:把待排序的记录按其关键码值的大小逐个插入到一 个已经排好序的有序序列中,直到所有的记录插入完为止,得到一个新的有序序列 。
直接插入排序的特性总结:
1. 元素集合越接近有序,直接插入排序算法的时间效率越高
2. 时间复杂度:O(N^2)
3. 空间复杂度:O(1),它是一种稳定的排序算法
4. 稳定性:稳定
#include <stdio.h>
#include <stdlib.h>
void Printf(int array[],int size)
{
for (int i = 0; i < size; ++i)
{
printf("%d ", array[i]);
}
printf("\n");
}
void Printf(int array[],int size)
{
for (int i = 0; i < size; ++i)
{
printf("%d ", array[i]);
}
printf("\n");
}
void Insert_Sort(int *array, int size)
{
int i, j;
for (i = 1; i < size; ++i) //待排序的
{
for (j = 0; j < i; ++j) //排好序的
{
if (array[i] < array[j])
{
int tmp = array[i]; //需要排序的元素array[i]
array[i] = array[j]; //向后搬移
array[j] = tmp; //填入记录的数据
}
}
}
}
int main()
{
int array[] = { 8,3,2,1,9,5,6,0,4,7 };
int size = sizeof(array)/sizeof(array[0]);
printf("原始数据:\n");
Printf(array, size);
//插入排序
Insert_Sort(array, size);
printf("插入排序后的数据:\n");
Printf(array, size);
system("pause");
return 0;
}
希尔排序:希尔排序法又称缩小增量法。希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。
希尔排序的特性总结:
1. 希尔排序是对直接插入排序的优化。
2. 当gap > 1时都是预排序,目的是让数组更接近于有序。当gap == 1时,数组已经接近有序的了,这样就 会很快。这样整体而言,可以达到优化的效果。我们实现后可以进行性能测试的对比。
3. 希尔排序的时间复杂度不好计算,需要进行推导,推导出来平均时间复杂度: O(N^1.3—N^2)
4. 稳定性:不稳定
#include <stdio.h>
#include <stdlib.h>
void Printf(int array[],int size)
{
for (int i = 0; i < size; ++i)
{
printf("%d ", array[i]);
}
printf("\n");
}
void Shell_Sort(int *array, int size)
{
int i, j;
int gap;
int tmp;
for (gap = size / 2; gap > 0; gap = gap / 2)
{
for (i = gap; i < size; i++)
{
tmp = array[i];
for (j = i - gap; (j >= 0) && (array[j] > tmp); j = j - gap)
{
array[j + gap] = array[j];
}
array[j + gap] = tmp;
}
}
}
int main()
{
int array[] = { 8,3,2,1,9,5,6,0,4,7 };
int size = sizeof(array)/sizeof(array[0]);
printf("原始数据:\n");
Printf(array, size);
//希尔排序
Shell_Sort(array, size);
printf("希尔排序后的数据:\n");
Printf(array, size);
system("pause");
return 0;
}
选择排序:每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的 数据元素排完 。
直接选择排序的特性总结:
1. 直接选择排序思考非常好理解,但是效率不是很好,实际中很少使用。
2. 时间复杂度:O(N^2)
3. 空间复杂度:O(1)
4. 稳定性:不稳定
#include <stdio.h>
#include <stdlib.h>
void Printf(int array[],int size)
{
for (int i = 0; i < size; ++i)
{
printf("%d ", array[i]);
}
printf("\n");
}
void Printf(int array[],int size)
{
for (int i = 0; i < size; ++i)
{
printf("%d ", array[i]);
}
printf("\n");
}
void Select_Sort(int *array, int size)
{
int i, j, k, tmp;
for (i = 0; i < size; ++i)
{
for (j = i + 1; j < size; ++j)
{
//k = i;
if (array[j] < array[i])
{
//k = j;
tmp = array[j];
array[j] = array[i];
array[i] = tmp;
}
}
}
}
int main()
{
int array[] = { 8,3,2,1,9,5,6,0,4,7 };
int size = sizeof(array)/sizeof(array[0]);
printf("原始数据:\n");
Printf(array, size);
//选择排序
Select_Sort(array, size);
printf("选择排序后的数据:\n");
Printf(array, size);
system("pause");
return 0;
}
堆排序:堆排序(Heapsort)是指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。它是 通过堆来进行选择数据。需要注意的是排升序要建大堆,排降序建小堆。
#include <stdio.h>
#include <stdlib.h>
void Printf(int array[],int size)
{
for (int i = 0; i < size; ++i)
{
printf("%d ", array[i]);
}
printf("\n");
}
void Swap(int *a, int *b)
{
int t = 0;
t = *a;
*a = *b;
*b = t;
}
void AdjustDown(int *array, int i, int size)
{
int child = i * 2 + 1;
int tmp;
for (tmp = array[i]; 2 * i + 1 < size; i = child) {
child = 2 * i + 1; //注意数组下标是从0开始的,所以左孩子的求发不是2*i
if (child != size - 1 && array[child + 1] > array[child])
++child; //找到最大的儿子节点
if (tmp < array[child])
array[i] = array[child];
else
break;
}
array[i] = tmp;
}
void Heap_Sort(int *array, int size)
{
int i;
for (i = (size - 2) / 2; i >= 0; i--)
{
AdjustDown(array, i, size);
}
for (i = size - 1; i > 0; --i)
{
Swap(&array[0], &array[i]);
AdjustDown(array, 0, i);
}
}
int main()
{
int array[] = { 8,3,2,1,9,5,6,0,4,7 };
int size = sizeof(array)/sizeof(array[0]);
printf("原始数据:\n");
Printf(array, size);
//堆排序
Heap_Sort(array, size);
printf("堆排序后的数据:\n");
Printf(array, size);
system("pause");
return 0;
}
冒泡排序:它重复地走访过要排序的元素列,依次比较两个相邻的元素,如果他们的顺序(如从大到小、首字母从A到Z)错误就把他们交换过来。走访元素的工作是重复地进行直到没有相邻元素需要交换,也就是说该元素列已经排序完成。
冒泡排序的特性总结:
1. 冒泡排序是一种非常容易理解的排序
2. 时间复杂度:O(N^2)
3. 空间复杂度:O(1)
4. 稳定性:稳定
#include <stdio.h>
#include <stdlib.h>
void Printf(int array[],int size)
{
for (int i = 0; i < size; ++i)
{
printf("%d ", array[i]);
}
printf("\n");
}
void Printf(int array[],int size)
{
for (int i = 0; i < size; ++i)
{
printf("%d ", array[i]);
}
printf("\n");
}
//冒泡排序(升序)
void Bubble_Sort(int *array, int size)
{
int i = 0;
int j = 0;
for (int i = 0; i < size - 1; ++i)
{
for (j = 0; j < size - i - 1; ++j)
{
if (array[j] > array[j + 1])
{
int tmp = array[j];
array[j] = array[j + 1];
array[j + 1] = tmp;
}
}
}
}
int main()
{
int array[] = { 8,3,2,1,9,5,6,0,4,7 };
int size = sizeof(array)/sizeof(array[0]);
printf("原始数据:\n");
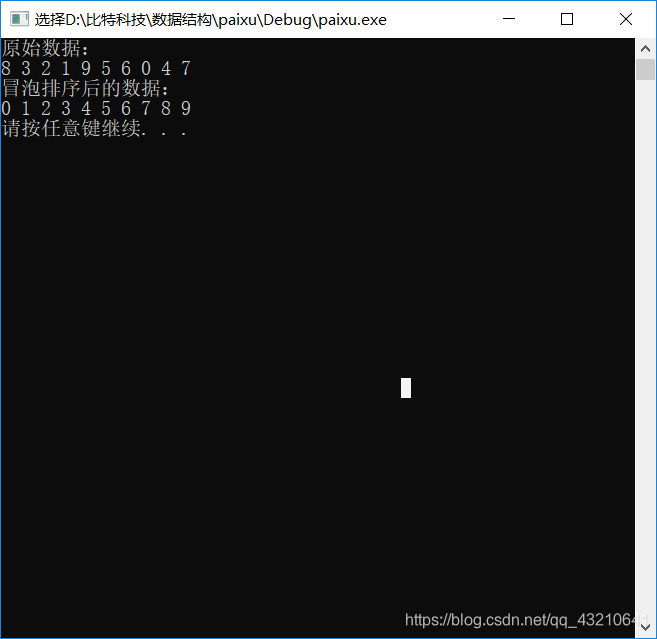
Printf(array, size);
//冒泡排序
Bubble_Sort(array, size);
printf("冒泡排序后的数据:\n");
Printf(array, size);
system("pause");
return 0;
}
归并排序:归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有 序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
归并排序的特性总结:
1. 归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。
2. 时间复杂度:O(N*logN)
3. 空间复杂度:O(N)
4. 稳定性:稳定
#include <stdio.h>
#include <stdlib.h>
#define N 10
void Printf(int array[],int size)
{
for (int i = 0; i < size; ++i)
{
printf("%d ", array[i]);
}
printf("\n");
}
void merge(int arr[], int low, int mid, int high)
{
int i, k;
int *tmp = (int *)malloc((high - low + 1) * sizeof(int));
int left_low = low;
int left_high = mid;
int right_low = mid + 1;
int right_high = high;
for (k = 0; left_low <= left_high && right_low <= right_high; k++)
{
if (arr[left_low] <= arr[right_low])
{
tmp[k] = arr[left_low++];
}
else
{
tmp[k] = arr[right_low++];
}
}
if (left_low <= left_high)
{
for (i = left_low; i <= left_high; i++)
tmp[k++] = arr[i];
}
if (right_low <= right_high)
{
for (i = right_low; i <= right_high; i++)
tmp[k++] = arr[i];
}
for (i = 0; i < high - low + 1; i++)
arr[low + i] = tmp[i];
free(tmp);
return;
}
void Merge_Sort(int arr[], unsigned int first, unsigned int last)
{
int mid = 0;
if (first < last)
{
mid = (first + last) / 2; /* 注意防止溢出 */
/*mid = first/2 + last/2;*/
//mid = (first & last) + ((first ^ last) >> 1);
Merge_Sort(arr, first, mid);
Merge_Sort(arr, mid + 1, last);
merge(arr, first, mid, last);
}
return;
}
int main()
{
int array[] = { 8,3,2,1,9,5,6,0,4,7 };
int size = sizeof(array)/sizeof(array[0]);
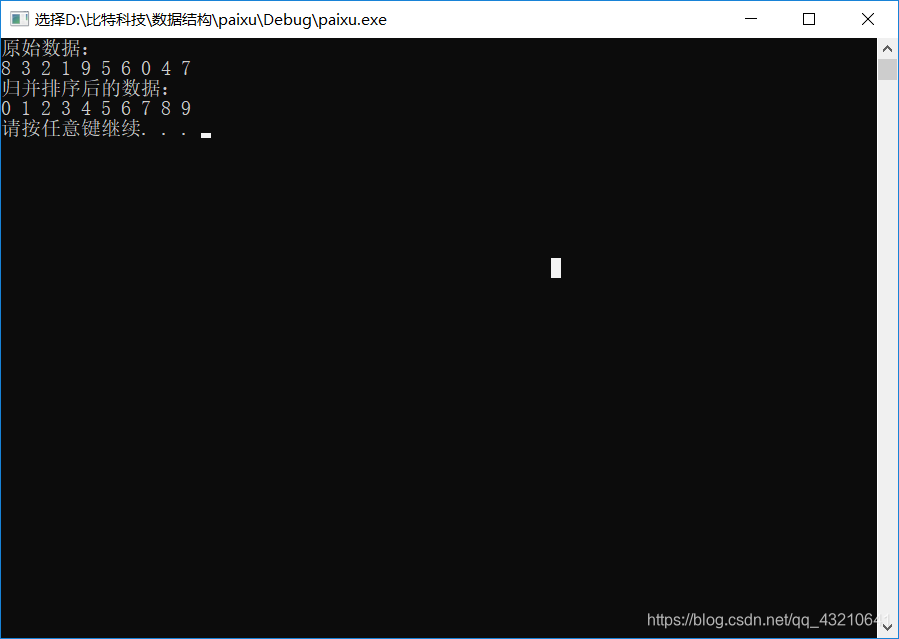
printf("原始数据:\n");
Printf(array, size);
//归并排序
Merge_Sort(array, 0, size - 1);
printf("归并排序后的数据:\n");
Printf(array, size);
system("pause");
return 0;
}
计数排序:计数排序的基本思想是对于给定的输入序列中的每一个元素x,确定该序列中值小于x的元素的个数(此处并非比较各元素的大小,而是通过对元素值的计数和计数值的累加来确定)。一旦有了这个信息,就可以将x直接存放到最终的输出序列的正确位置上。
如果用快速排序,该算法的复杂度为O(nlog^2n)。改用计数排序后,复杂度降为O(nlogn)
计数排序算法是一个稳定的排序算法
#include <stdio.h>
#include <stdlib.h>
void Printf(int array[],int size)
{
for (int i = 0; i < size; ++i)
{
printf("%d ", array[i]);
}
printf("\n");
}
void Count_Sort(int *array, int size)
{
int max = array[0];
int min = array[0];
for (int i = 0; i < size; i++)
{
if (array[i] > max)
max = array[i];
if (array[i] < min)
min = array[i];
}
int range = max - min + 1;
int *b = (int *)calloc(range, sizeof(int));
for (int i = 0; i < size; i++)
{
b[array[i] - min] += 1;
}
int j = 0;
for (int i = 0; i < range; i++)
{
while (b[i]--)
{
array[j++] = i + min;
}
}
free(b);
b = NULL;
}
int main()
{
int array[] = { 8,3,2,1,9,5,6,0,4,7 };
int size = sizeof(array)/sizeof(array[0]);
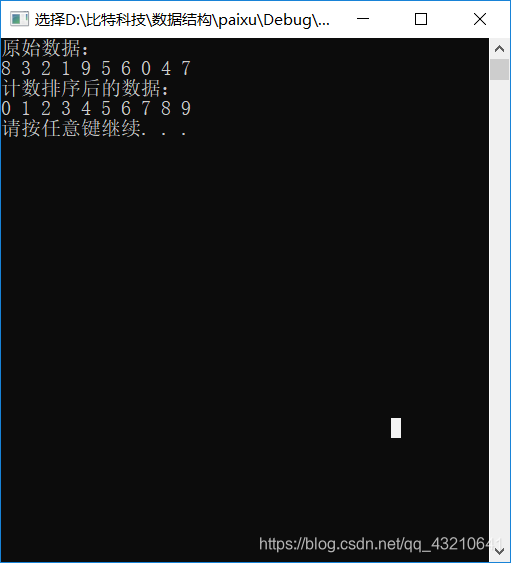
printf("原始数据:\n");
Printf(array, size);
Count_Sort(array, size);
printf("计数排序后的数据:\n");
Printf(array, size);
system("pause");
return 0;
}
基数排序:将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
时间效率 [1] :设待排序列为n个记录,d个关键码,关键码的取值范围为radix,则进行链式基数排序的时间复杂度为O(d(n+radix)),其中,一趟分配时间复杂度为O(n),一趟收集时间复杂度为O(radix),共进行d趟分配和收集。 空间效率:需要2*radix个指向队列的辅助空间,以及用于静态链表的n个指针。
#include <stdio.h>
#include <stdlib.h>
#define RADIX_10 10
#define KEYNUM_31 10
void Printf(int array[],int size)
{
for (int i = 0; i < size; ++i)
{
printf("%d ", array[i]);
}
printf("\n");
}
//基数排序(升序)
int GetNumInPos(int num, int pos)
{
int temp = 1;
for (int i = 0; i < pos - 1; i++)
temp *= 10;
return (num / temp) % 10;
}
void Radix_Sort(int *array, int size)
{
int *array1[RADIX_10];
for (int i = 0; i < 10; i++)
{
array1[i] = (int *)malloc(sizeof(int) * (size + 1));
array1[i][0] = 0;
}
for (int pos = 1; pos <= KEYNUM_31; pos++)
{
for (int i = 0; i < size; i++)
{
int num = GetNumInPos(array[i], pos);
int index = ++array1[num][0];
array1[num][index] = array[i];
}
for (int i = 0, j = 0; i < RADIX_10; i++)
{
for (int k = 1; k <= array1[i][0]; k++)
array[j++] = array1[i][k];
array1[i][0] = 0;
}
}
}
int main()
{
int array[] = { 8,3,2,1,9,5,6,0,4,7 };
int size = sizeof(array)/sizeof(array[0]);
printf("原始数据:\n");
Printf(array, size);
//基数排序
Radix_Sort(array, size);
printf("基数排序后的数据:\n");
Printf(array, size);
system("pause");
return 0;
}