基础理论:
图像分类是深度学习在视觉领域第一个取得突破性成果的任务。本章首先介绍了图像分类任务的发展历程与评价指标。然后分为三个角度分别介绍了在图像分类领域具有重要地位的三种模型。第一种是基于残差网络的模型,本章重点介绍了ResNet、DenseNet和DPN。第二种是基于Transformer思想的模型,本章重点介绍了ViT和Swin-Transformer模型。第三种是用于移动端设备的轻量级模型,本章重点介绍了MobileNet和PP-LCNet。最后,本章使用飞桨框架完成了桃子分拣项目。学完本章,希望读者能够掌握以下知识点:
- 了解图像分类的发展历程;
- 掌握基于残差思想的模型特点;
- 掌握基于Transformer思想的模型特点;
- 掌握轻量级网络模型的特性。
图像分类任务是最早使用深度学习方法的计算机视觉任务,很多经典的网络架构都是首先应用到图像分类任务上,因此图像分类中的深度学习网络模型可以看做其他计算机视觉任务的基石。
早期的图像分类方法主要通过手工提取特征对整个图像进行描述,然后使用分类器判别图像类别,因此图像分类的核心在于对特征进行分类,而如何提取图像的特征至关重要。底层特征中包含了大量冗余噪声,为了提高特征表达的鲁棒性,需要使用一种特征变换算法对底层特征进行编码,称作特征编码。特征编码之后一般会经过空间特征约束,也称作特征汇聚,具体只在一个空间范围内对每一位特征取最大值或者平均值,可以获得一定特征不变性的特征表达。
图像经过底层特征提取特征编码特征汇聚后可以表示为一个固定维度的向量描述,将该特征向量经过分类器分类便可实现对图像的分类。
基于核方法的svm是传统方法中使用最广泛的分类器,在传统图像分类任务上性能很好。传统的图像分类方法对于一些简单且具有明显特征的图像分类场景是有效的,但由于实际情况非常复杂,在面对复杂场景时,传统的分类方法就无法达到满意的分类效果,这是因为传统分类方法使用的手工提取特征方法无法全面准确的描述图像特征,并且手工提取的特征无法应对,多视角,多角度,不同光照遮挡同物,多形态等问题。
CNN转变到Transformer类似从着眼于局部转变到专用于全局,更加符合人类的视觉特点(人类擅长快速捕获全局中的特征),CNN擅长提取局部小而精的信息,但存在提取能力不足的缺点,Transformer依赖全局长距离的建模,不关注局部信息,也就丧失了CNN平移不变,翻转不变等特性,会产生捕捉信息冗余和对数据需求量更大的缺点。
综合来看,深度学习方法在图像分类问题上,经历了朴素MLP,CNN 、Transformer,复杂MLP等模型发展的过程。这些模型都具有各自的特点,卷积仅包含局部连接,因此计算高效;自注意力采用了动态权值,因此模型容量更大,它同时还具有全局感受野;MLP同样具有全局感受野,但没有使用动态权值。可以看出,卷积与自注意力具有互补特性,卷积具有最好的泛化能力,而Transformer在三种架构中具有最大的模型容量。卷积是设计轻量级模型的最佳选择,但设计大型模型应考虑 Transformer。因此,可以考虑使用卷积的局部建模帮助提升Transformer与MLP的性能。考虑到上述结构特憧人稀疏连接有助于提升泛化性能,而动态权值与全局感受野有助于提升模型容量。因此,在图像分类任务上,不断有革新性的方法出现,为计算机视觉提供了更广泛的应用空间。
实验名称:桃子分类模型的搭建与训练
1.实验目标
本实验主要讲解:用paddlepaddle深度学习框架搭建桃子分类模型,并完成训练和测试的全过程。
完成此实验后,可以掌握的能力有:
- 掌握paddlepaddle深度学习框架的使用方法;
- 掌握如何用paddlepaddle深度学习框架搭建 桃子分类模型;
- 掌握如何完成模型的训练、评估、保存、预测等深度学习工作过程;
2.实验背景介绍
图像分类是计算机视觉的基础,也是其他计算机复杂任务的基础。深度学习技术发展到现在,诞生了许多优秀的图像分类算法。本次桃子分拣,我们就使用其中的典型算法代表resnet。
3. 使用paddlepaddle框架一般流程介绍
如今,paddlepaddle已经推出了2.0版本,在2.0版本中,推出了高阶API,使得代码更简洁,变成更容易。
目前飞桨高层API由五个模块组成,分别是数据加载、模型组建、模型训练、模型可视化和高阶用法。如下图所示:
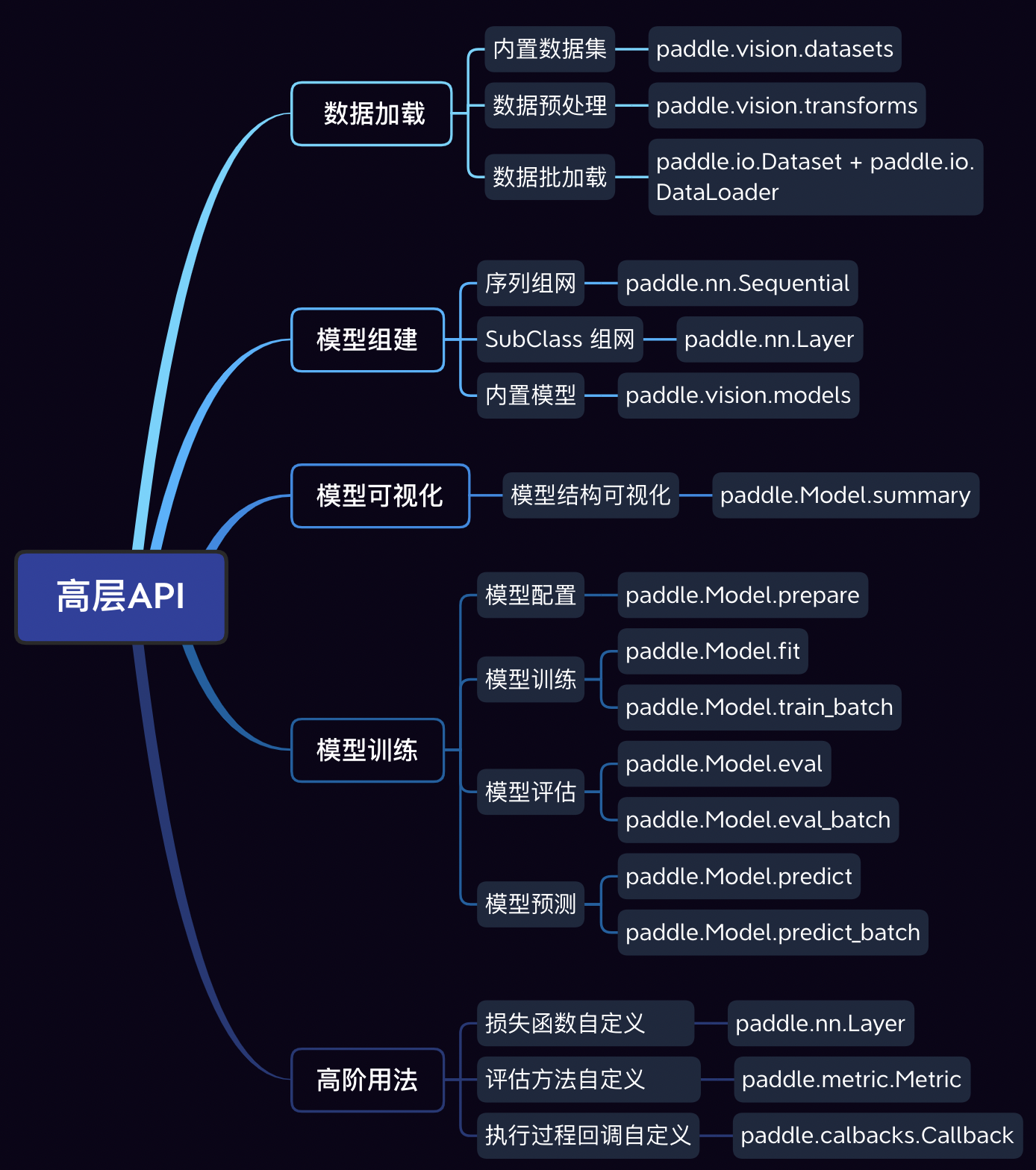
用paddlepaddle框架进行深度学习项目十分容易,按照一般流程即可完成深度学习项目(下图为项目实施一般流程)。该流程主要包含五大步骤分别为数据处理、模型设计、训练配置、训练过程和模型保存。在数据处理阶段主要是为模型准可用的数据,包括本地或者网络数据的收集与预处理。模型设计阶段就是深度学习项目中大家讨论最多的模型搭建,在这阶段关键就是网络结构的设计与实现,飞桨框架为开发者准备好了大量的经过工业验证的模型库和预训练模型方便开发者直接使用。在训练配置阶段开发者需要设定优化器类型和学习率衰减等参数,同时还需要指定使用GPU还是CPU完成计算。在训练过程阶段,就是框架真实运行计算过程的阶段。在该阶段,飞桨框架不断的完成正向传播、反向传播和梯度下降的过程。最后是模型保存,当模型达到预定指标或者达到预定的训练次数后,开发者可以将“训练好”的模型保存起来用以下次训练或者用以部署。

用paddlepaddle框架进行深度学习项目流程
4. 实验内容
4.1 数据集介绍
本次实验我们使用的数据集是四个种类桃子,这些桃子被分在四个文件夹中,每一个文件夹的名字就对应着一类桃子。
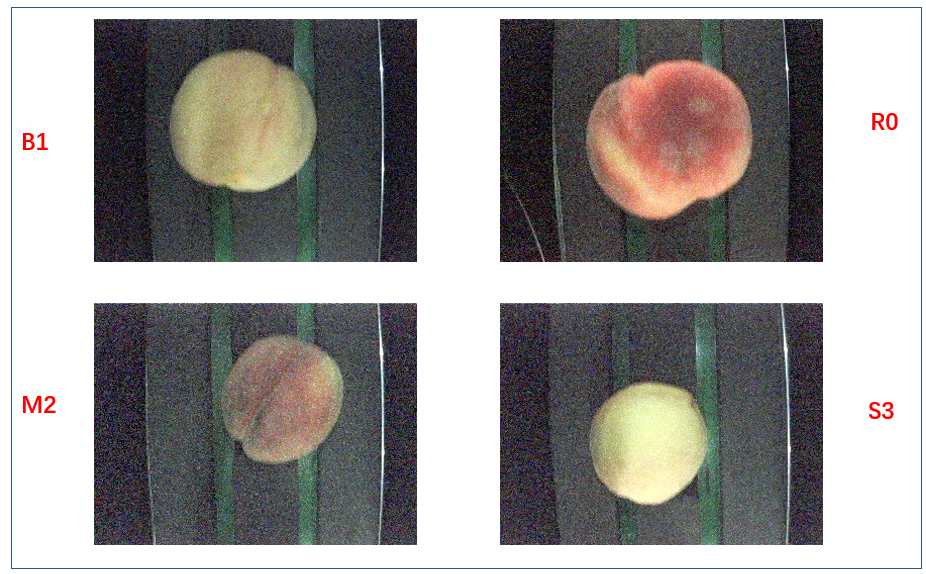
桃子数据集
用我们自己的眼睛来观察,好像这些桃子是按照 大小、颜色 来划分的四类;究竟是不是这样呢?等做完了这个实验,深度学习模型自己就能判断出来是按照什么来划分了。
本次实验,已经为大家提供好了数据集,数据集存储在 “data/enhancement/” 文件夹下。图片分为2个文件夹,一个是训练集一个是测试集。每个文件夹中有4个分类:R0,B1,M2,S3。 桃子分拣原数据集,包含两个文件夹:“train”、“test”
每个文件夹下有:“B1”、“M2”、“R0”、“S3”
训练集:
train_B1:1601张图片
train_M2:1800张图片
train_R0:1601张图片
train_S3:1635张图片
测试集:
test_B1:16张图片
test_M2:18张图片
test_R0:18张图片
test_S3:15张图片
实验文件介绍
本次实验文件结构如下:
本次实验的代码、数据集 都已经为大家准备好,目录结构如下图所示:
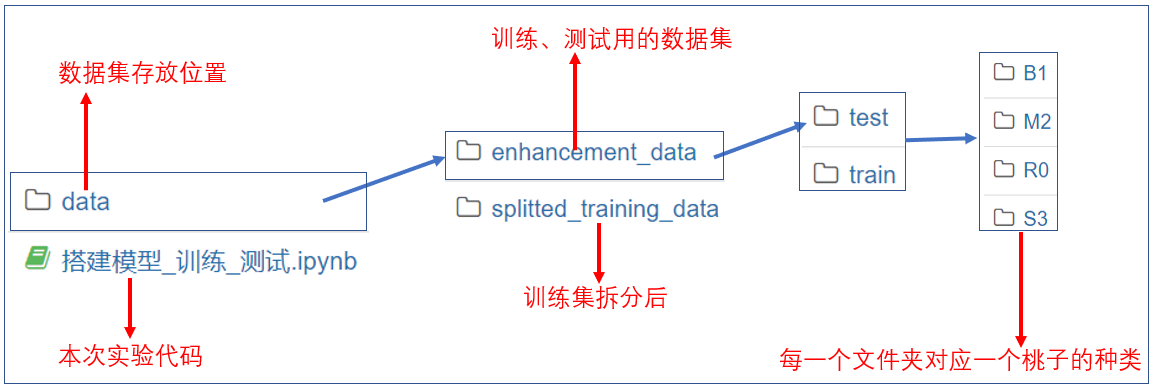
本次实验文件结构
4.2 导入实验需要的库
实验第一步,需要导入相关的库,最主要的是如下几个:
- os : OS模块提供了非常丰富的方法用来处理文件和目录。
- sys:sys模块提供了一系列有关Python运行环境的变量和函数。
- shutil:用于文件拷贝的模块
- numpy:numpy 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
- random:Python中的random模块用于生成随机数。
- paddle.vision.datasets:该模块包含数据加载的相关函数,比如可以用来加载常用的数据集等,如mnist。
- paddle.vision.transforms:该模块包含对图像进行转换的函数,比如把HWC格式的图片,转变成CHW模式的输入张量。也包含飞桨框架对于图像预处理的方式,可以快速完成常见的图像预处理,如调整色调、对比度,图像大小等;
- paddle.io.Dataset:该模块包含了飞桨框架数据加载方式,可以“一键”完成数据的批加载与异步加载。
4.3 数据集准备
本次实验,已经为大家提供好了数据集,数据集存储在 “data/enhancement/” 文件夹下。
本次实验的数据预处理包括:
1.生成txt文件
2.拆分训练集、验证集
4.3.1 生成txt文件
为什么要生成txt文件呢?我们看到,在数据集中,每一个文件夹对应一个类别;但是并没有一个txt 文件来指定标签(label);于是我们首先要生成txt文件;
为了代码的整齐和简洁,我们把数据集路径等参数配置在一个全局变量train_parameters中。其解释如下:
- 'train_data_dir'是提供的经增强后的原始训练集;
- 'test_image_dir'是提供的原始测试集;
- 'train_image_dir'和'eval_image_dir'是由原始训练集经拆分后生成的实际训练集和验证集
- 'train_list_dir'和'test_list_dir'是生成的txt文件路径
- 'saved_model' 存放训练结果的文件夹
以上步骤操作完之后,就会在 data/enhancement_data/目录下生成 train.txt test.txt两个文件。

4.3.2 划分训练集和验证集
- 我们已经有了训练集、测试集;最好还要把训练集再次拆分,从训练集中拆分出来一个验证集。
- 这样,我们训练的时候,就可以用验证集来验证我们的模型训练效果,通过实时的观察训练效果,便于我们及时的调参。
creating training and eval images
划分训练集和验证集完成!
运行完上面的代码,就完成了训练集、验证集的拆分。拆分放在 ./data/splitted_training_data/ 目录下:

4.5 自定义数据集类
飞桨框架将一些我们常用的数据集做成了API,对用户开放,对应API为paddle.vision.datasets与paddle.text.datasets。我们使用的时候可以直接调用这些API就可以完成数据集的下载和使用。这些集成好的数据集有:
- 视觉相关数据集: ['DatasetFolder', 'ImageFolder', 'MNIST', 'FashionMNIST', 'Flowers', 'Cifar10', 'Cifar100', 'VOC2012']
- 自然语言相关数据集: ['Conll05st', 'Imdb', 'Imikolov', 'Movielens', 'UCIHousing', 'WMT14', 'WMT16']
但是,在实际的使用场景中,我们往往需要用到自己的数据集。比如本次实验,我们就使用自己的桃子数据集。
飞桨为用户提供了paddle.io.Dataset基类,让用户通过类的集成来快速实现数据集定义。
PaddlePaddle对数据集的加载方式是:统一使用Dataset(数据集定义) + DataLoader(多进程数据集加载)。
数据集定义-Dataset
- 首先我们先进行数据集的定义 ;
- 数据集定义主要是实现一个新的Dataset类,继承父类paddle.io.Dataset;
- 然后实现父类中以下两个抽象方法,“__ getitem __ ”和 “__ len __”:

数据集加载-DataLoader
DataLoader 返回一个迭代器,迭代器返回的数据中的每个元素都是一个Tensor,其调用方法如下:
class paddle.io.DataLoader(dataset, feed_list=None, places=None, return_list=False, batch_sampler=None, batch_size=1, shuffle=False, drop_last=False, collate_fn=None, num_workers=0, use_buffer_reader=True, use_shared_memory=True, timeout=0, worker_init_fn=None) DataLoader 迭代一次给定的 dataset(顺序由 batch_sampler 给定)
DataLoader支持单进程和多进程的数据加载方式,当 num_workers 大于0时,将使用多进程方式异步加载数据。
详细介绍 https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/io/DataLoader_cn.html
下面的代码用来展示如何使用 DataLoader
opencv 版本号为:4.1.1
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/__init__.py:107: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import MutableMapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Iterable, Mapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Sized
mini_batch 的类型为:<class 'list'>
mini_batch 的大小为:2
(3, 224, 224)
(3, 224, 224)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2349: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
if isinstance(obj, collections.Iterator):
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2366: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
return list(data) if isinstance(data, collections.MappingView) else data
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
<matplotlib.image.AxesImage at 0x7fb4678d8350>

如上图所示,这时候取得的图片并不是原始图片的样子。那是因为在 PeachDataset 类中,对图片数据使用了 transform 方法,也就是对图片做了一些变化。为了说明这一点,可以使用下面的方法作对比。
下图为已经发生变化图片:
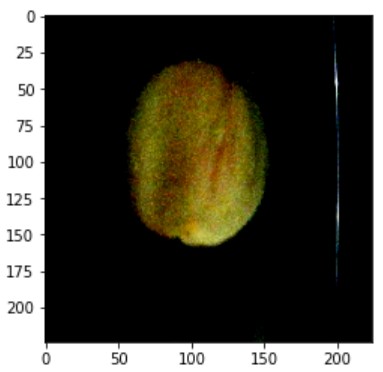
为了对比说明请修改 PeachDataset 类中的代码,加入一个注释符号,代码如下:
这样做的目的是,既可以改变图片的大小而且符合paddle的要求,又可以避免产生归一化引起的数据变动。
transform_test = T.Compose([ T.Resize(size=(224,224)) ,T.Transpose() #,T.Normalize(mean, std) ]) 修改完该代码后,请打开下面的代码的注释,重启执行器,点击右上角的 “运行->运行当前选中及之前的所有cell”
就可以看到原始数据集中的图片,如下图所示:
查看完数据后,请不要忘记,打开 PeachDataset 类中的注释。和加入下方代码的注释。
4.6 搭建分类模型
接下来,我们就要搭建一个图像分类模型,用这个模型可以实现桃子数据集的分类。
怎么搭建分类模型呢?
- 我们可以按照自己的想法搭建DNN网络模型,或者CNN网络模型,或者其他网络模型,但是这对我们的算法研究能力要求很高;
- 我们可以使用已经成熟的、经典的网络模型,比如VGG、ResNet等;用paddle框架来搭建这些模型,来为我们所用。
本次实验,我们就采用50层的残差网络ResNet作为我们的分类模型。
并且,本次实验,为了增加我们的模型效果,我们还是使用了迁移学习方法。那么为什么要用迁移学习呢?怎么使用迁移学习呢?
4.6.1 迁移学习
现实的工程开发中,很少有人从零开始训练一个完整的神经网络。
为什么?
因为一般我们的数据集都不是很大,所以训练出的模型泛化能力往往不强。且训练非常耗时。
怎么做?
常用的方法是找到一个很大的公有数据集(比如ImageNet,包含了120万张图片和1000个类别),在这个数据集上先训练好一个神经网络模型A(这个A一般别人已经训练好了),然后将这个A作为一个起始点,经过微调,再训练我们自己的数据集。这个A也叫做 “预训练模型”。
这就是 迁移学习 的一种方法,也叫做 fine tune。
那么fine tune的理论依据是什么?也即是:为什么我们可以在别人训练好的模型的基础上进行微调?这就要从卷积神经网络的结构原理上进行分析。
- 对于卷积网络来说:前面几层都学习到的是通用的特征(generalfeature),比如图像的边缘;随着网络层次的加深,后面的网络更偏重于学习特定的特征(specific feature),例如身体部位、面部和其他组合性特征。
- 最后的全连接层通常被认为是捕获了与解决相应任务相关的信息,例如 AlexNet 的全连接层可以指出提取的这些特征属于1000 类物体中的哪一类。
- 比如在人脸识别过程中,初级的若干层卷积会提取到直线、曲线等通用特征;中间若干层卷积会进一步学习到眼睛、鼻子等特定部位,高层卷积则可以学习到组合特征,从而判断出这是一张人脸图像。 -卷积神经网络的这种特性,就是我们的fine tune理论依据。
可能有同学会问:那为什么我们不直接用别人在大数据集(比如ImageNet)上训练好的模型,而是还要微调呢?
- 因为别人训练好的模型,可能并不是完全适用于我们自己的任务。可能别人的网络能做比我们的任务更多的事情;可能别人的网络比较复杂,我们的任务比较简单。 -举一个例子,假如我们想训练一个猫狗图像二分类的网络,我们首先会想到直接使用别人在 ImageNet上训练好的网络模型。但是 ImageNet 有 1000 个类别,而我们只需要2 个类别。此时,就需要针对我们自己的任务,来进行微调了,比如可以固定原始网络的相关层,修改网络的输出层,以使结果更符合我们的需要。
在PaddlePaddle2.0中,使用预训练模型只需要设定模型参数pretained=True。
4.6.2 搭建模型
使用飞桨,很便利的一点是:飞桨框架内置了许多模型,真正的一行代码实现深度学习模型。
目前,飞桨框架内置的模型都是CV领域的模型,在paddle.vision.models目录下,具体包含如下的模型:
飞桨框架内置模型: ['ResNet', 'resnet18', 'resnet34', 'resnet50', 'resnet101', 'resnet152', 'VGG', 'vgg11', 'vgg13', 'vgg16', 'vgg19', 'MobileNetV1', 'mobilenet_v1', 'MobileNetV2', 'mobilenet_v2', 'LeNet']
比如我们本次使用的resnet50,就已经有内置模型了。

100%|██████████| 69183/69183 [00:01<00:00, 47292.60it/s]
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1301: UserWarning: Skip loading for fc.weight. fc.weight receives a shape [512, 1000], but the expected shape is [512, 4].
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1301: UserWarning: Skip loading for fc.bias. fc.bias receives a shape [1000], but the expected shape is [4].
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
使用 model.summary 观察网络情况
参考文档: https://github.com/PaddlePaddle/Paddle/blob/release/2.1/python/paddle/hapi/model.py#L883
API 文档写的和真实代码之间稍有不同
# 以下为源代码 def summary(self, input_size=None, dtype=None): """Prints a string summary of the network. Args: input_size (tuple|InputSpec|list[tuple|InputSpec], optional): size of input tensor. if not set, input_size will get from ``self._inputs`` if network only have one input, input_size can be tuple or InputSpec. if model have multiple input, input_size must be a list which contain every input's shape. Default: None. dtypes (str, optional): if dtypes is None, 'float32' will be used, Default: None. Returns: Dict: a summary of the network including total params and total trainable params. Examples: .. code-block:: python import paddle from paddle.static import InputSpec input = InputSpec([None, 1, 28, 28], 'float32', 'image') label = InputSpec([None, 1], 'int64', 'label') model = paddle.Model(paddle.vision.models.LeNet(), input, label) optim = paddle.optimizer.Adam( learning_rate=0.001, parameters=model.parameters()) model.prepare( optim, paddle.nn.CrossEntropyLoss()) params_info = model.summary() print(params_info) """ assert (input_size is not None or self._inputs is not None ), "'input_size' or 'self._input' must be set" if input_size is not None: _input_size = input_size else: _input_size = self._inputs return summary(self.network, _input_size, dtype) 参数:
- input_size (tuple|InputSpec|list) - 输入张量的大小。如果网络只有一个输入,那么该值需要设定为tuple或InputSpec。如果模型有多个输入。那么该值需要设定为list[tuple|InputSpec],包含每个输入的shape。如果该值没有设置,会将 self._inputs 作为输入。默认值:None。
- dtypes (str,可选) - 输入张量的数据类型,如果没有给定,默认使用 float32 类型。默认值:None。
返回:字典。包含网络全部参数的大小和全部可训练参数的大小。
-------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===============================================================================
Conv2D-1 [[1, 3, 224, 224]] [1, 64, 112, 112] 9,408
BatchNorm2D-1 [[1, 64, 112, 112]] [1, 64, 112, 112] 256
ReLU-1 [[1, 64, 112, 112]] [1, 64, 112, 112] 0
MaxPool2D-1 [[1, 64, 112, 112]] [1, 64, 56, 56] 0
Conv2D-2 [[1, 64, 56, 56]] [1, 64, 56, 56] 36,864
BatchNorm2D-2 [[1, 64, 56, 56]] [1, 64, 56, 56] 256
ReLU-2 [[1, 64, 56, 56]] [1, 64, 56, 56] 0
Conv2D-3 [[1, 64, 56, 56]] [1, 64, 56, 56] 36,864
BatchNorm2D-3 [[1, 64, 56, 56]] [1, 64, 56, 56] 256
BasicBlock-1 [[1, 64, 56, 56]] [1, 64, 56, 56] 0
Conv2D-4 [[1, 64, 56, 56]] [1, 64, 56, 56] 36,864
BatchNorm2D-4 [[1, 64, 56, 56]] [1, 64, 56, 56] 256
ReLU-3 [[1, 64, 56, 56]] [1, 64, 56, 56] 0
Conv2D-5 [[1, 64, 56, 56]] [1, 64, 56, 56] 36,864
BatchNorm2D-5 [[1, 64, 56, 56]] [1, 64, 56, 56] 256
BasicBlock-2 [[1, 64, 56, 56]] [1, 64, 56, 56] 0
Conv2D-7 [[1, 64, 56, 56]] [1, 128, 28, 28] 73,728
BatchNorm2D-7 [[1, 128, 28, 28]] [1, 128, 28, 28] 512
ReLU-4 [[1, 128, 28, 28]] [1, 128, 28, 28] 0
Conv2D-8 [[1, 128, 28, 28]] [1, 128, 28, 28] 147,456
BatchNorm2D-8 [[1, 128, 28, 28]] [1, 128, 28, 28] 512
Conv2D-6 [[1, 64, 56, 56]] [1, 128, 28, 28] 8,192
BatchNorm2D-6 [[1, 128, 28, 28]] [1, 128, 28, 28] 512
BasicBlock-3 [[1, 64, 56, 56]] [1, 128, 28, 28] 0
Conv2D-9 [[1, 128, 28, 28]] [1, 128, 28, 28] 147,456
BatchNorm2D-9 [[1, 128, 28, 28]] [1, 128, 28, 28] 512
ReLU-5 [[1, 128, 28, 28]] [1, 128, 28, 28] 0
Conv2D-10 [[1, 128, 28, 28]] [1, 128, 28, 28] 147,456
BatchNorm2D-10 [[1, 128, 28, 28]] [1, 128, 28, 28] 512
BasicBlock-4 [[1, 128, 28, 28]] [1, 128, 28, 28] 0
Conv2D-12 [[1, 128, 28, 28]] [1, 256, 14, 14] 294,912
BatchNorm2D-12 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
ReLU-6 [[1, 256, 14, 14]] [1, 256, 14, 14] 0
Conv2D-13 [[1, 256, 14, 14]] [1, 256, 14, 14] 589,824
BatchNorm2D-13 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
Conv2D-11 [[1, 128, 28, 28]] [1, 256, 14, 14] 32,768
BatchNorm2D-11 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
BasicBlock-5 [[1, 128, 28, 28]] [1, 256, 14, 14] 0
Conv2D-14 [[1, 256, 14, 14]] [1, 256, 14, 14] 589,824
BatchNorm2D-14 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
ReLU-7 [[1, 256, 14, 14]] [1, 256, 14, 14] 0
Conv2D-15 [[1, 256, 14, 14]] [1, 256, 14, 14] 589,824
BatchNorm2D-15 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
BasicBlock-6 [[1, 256, 14, 14]] [1, 256, 14, 14] 0
Conv2D-17 [[1, 256, 14, 14]] [1, 512, 7, 7] 1,179,648
BatchNorm2D-17 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048
ReLU-8 [[1, 512, 7, 7]] [1, 512, 7, 7] 0
Conv2D-18 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,359,296
BatchNorm2D-18 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048
Conv2D-16 [[1, 256, 14, 14]] [1, 512, 7, 7] 131,072
BatchNorm2D-16 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048
BasicBlock-7 [[1, 256, 14, 14]] [1, 512, 7, 7] 0
Conv2D-19 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,359,296
BatchNorm2D-19 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048
ReLU-9 [[1, 512, 7, 7]] [1, 512, 7, 7] 0
Conv2D-20 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,359,296
BatchNorm2D-20 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048
BasicBlock-8 [[1, 512, 7, 7]] [1, 512, 7, 7] 0
AdaptiveAvgPool2D-1 [[1, 512, 7, 7]] [1, 512, 1, 1] 0
Linear-1 [[1, 512]] [1, 4] 2,052
===============================================================================
Total params: 11,188,164
Trainable params: 11,168,964
Non-trainable params: 19,200
-------------------------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 57.04
Params size (MB): 42.68
Estimated Total Size (MB): 100.30
-------------------------------------------------------------------------------
{'total_params': 11188164, 'trainable_params': 11168964}
4.6.3 训练配置
优化器配置
用paddle.Model完成模型的封装后,在训练前,需要对模型进行配置,通过Model.prepare接口来对训练进行提前的配置准备工作,包括设置模型优化器,Loss计算方法,精度计算方法等。

- 学习率(learning_rate)参数很重要。
- 如果训练过程中的准确率呈震荡状态,忽大忽小,可以试试把学习率调低
计算资源配置
设置该次计算使用的具体计算资源。
首先,可以查看当前使用的计算设备。(此步骤不是必须的)
然后,设置本次训练使用的计算设备。
4.6.4 训练模型
做好模型训练的前期准备工作后,我们正式调用fit()接口来启动训练过程,需要指定以下至少3个关键参数:训练数据集,训练轮次和单次训练数据批次大小。

训练时间说明:
- 在CPU上运行10个epoch,需要1.5小时左右;
- 在GPU上运行10个epoch,需要30分钟左右;
The loss value printed in the log is the current step, and the metric is the average value of previous steps.
Epoch 1/1
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:77: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
return (isinstance(seq, collections.Sequence) and
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/norm.py:641: UserWarning: When training, we now always track global mean and variance.
"When training, we now always track global mean and variance.")
step 2904/2904 [==============================] - loss: 0.0549 - acc: 0.5786 - 62ms/step
Eval begin...
step 415/415 [==============================] - loss: 0.0867 - acc: 0.7819 - 23ms/step
Eval samples: 830
4.6.5 模型评估和保存
模型训练结束后,我们得到了一个训练好的模型,但是这个模型效果怎么样,还需要我们去具体做下评估。
什么是模型评估呢?
- 模型评估其实就是:使用我们预留的测试数据放到所得到的模型中进行实际的预测,并基于标签进行校验,来看模型在测试集上的表现。
- 模型评估的代码实现,在高层API中也非常地简单,我们事先定义好用于评估使用的数据集后,对于训练好的模型进行评估操作可以使用model.evaluate接口;操作结束后会根据prepare接口配置的loss和metric来进行相关指标计算返回。
本实验评价指标:
本次实验,我们采用的评价指标是 准确率(accuracy),简称acc
同学们相互之间比较一下,你的模型评估结果怎么样?你的acc值达到多少了?
该实验如果进行了合理的 数据增强,准确率( accuracy)是可以达到很高的,请大家努力把acc值提升到90%以上。
Eval begin...
step 67/67 [==============================] - loss: 0.0052 - acc: 0.7910 - 13ms/step
Eval samples: 67
{'loss': [0.0051732725], 'acc': 0.7910447761194029}
4.6.6 模型预测
以上步骤,我们完成了模型的训练、模型的评估、模型保存;如果这个模型经过评估之后效果不错,那么就可以使用了。我们就可以使用这个保存的模型来进行预测。
如何进行模型预测呢?
- 飞桨高层API中提供了model.predict接口来方便用户对训练好的模型进行预测;
- 我们只需要将“预测数据+保存的模型”,放到model.predict接口进行计算即可,接口会把模型计算得到的预测结果返回,从而完成我们的任务。
Predict begin...
step 67/67 [==============================] - 12ms/step
Predict samples: 67
<class 'list'>
1
[[ 0.4494054 1.8589294 -2.709025 -0.98785317]]
[[ 0.80108535 2.0312922 -2.3985271 -1.667168 ]]
[[-0.487098 2.5169828 -3.8384209 0.09941977]]
[[ 1.1755923 1.9356494 -2.7956083 -1.824508 ]]
[[ 0.6587918 1.5227697 -1.9370861 -1.2466118]]
[[ 1.9423198 1.8514836 -2.0579038 -3.0512297]]
[[-0.12070499 2.1658874 -3.2705145 -0.2214822 ]]
[[ 2.30185 1.9300838 -2.6378424 -3.3231502]]
[[ 1.7931688 1.7564571 -2.713827 -2.3772974]]
[[ 1.018136 1.9348547 -2.1037087 -2.093875 ]]
[[ 1.2455556 1.7356219 -2.3573794 -1.9229555]]
[[ 1.3166553 2.0454793 -2.1393437 -2.5154655]]
[[ 2.2485528 2.5826378 -2.3228188 -4.113832 ]]
[[ 0.6856951 1.9657588 -2.340539 -1.5627216]]
[[ 0.34038985 2.5555618 -3.4037375 -1.1876322 ]]
[[ 1.7155951 2.2181606 -2.2069125 -3.0874062]]
[[-0.9589406 2.3568041 -3.914858 0.8861027]]
[[-2.2687616 3.561953 -6.1434994 2.204158 ]]
[[-0.8965972 2.812673 -4.498936 0.67248255]]
[[-1.7266133 3.0567627 -5.3219457 1.823607 ]]
[[-1.2236824 2.9153998 -5.2624416 1.1972692]]
[[-1.6313993 2.393093 -4.390437 1.8520648]]
[[-2.261466 3.1709478 -5.7391357 2.475055 ]]
[[-2.0998657 2.7529852 -5.1272326 2.396462 ]]
[[-1.6497151 2.9010382 -5.0573497 1.7648369]]
[[-2.6754675 2.9362612 -5.56551 2.9678605]]
[[-1.073315 2.3352654 -4.07773 1.1857122]]
[[-0.88414484 2.4533503 -4.0443926 0.775055 ]]
[[-1.7560171 3.3508494 -5.375548 1.4013046]]
[[-2.615417 4.013784 -6.8865647 2.4297483]]
[[-1.829337 3.1974657 -5.3266735 1.5116838]]
[[-1.1488906 2.4435222 -4.151718 1.1106087]]
[[-2.672726 3.7604275 -6.60363 2.6530373]]
[[-1.3436769 2.810868 -4.783174 1.3363845]]
[[-7.1727552 -4.178957 6.645717 1.3258969]]
[[-10.802859 -8.898961 13.038587 0.8829916]]
[[-6.100724 -3.6756551 5.3887143 2.429795 ]]
[[-6.956199 -4.8285522 7.192293 1.4987972]]
[[-6.806343 -4.737133 7.0949545 1.9803424]]
[[-10.631139 -8.797351 12.851841 0.9559243]]
[[-9.890509 -7.7998743 11.965744 1.0906614]]
[[-6.637445 -4.125729 6.246958 2.3932679]]
[[-4.850948 -3.7300088 5.50579 -0.28020984]]
[[-5.89312 -3.9382315 5.5570445 1.115171 ]]
[[-9.489717 -7.5113807 11.062157 1.4899993]]
[[-4.060526 -4.7304277 7.44195 -1.7170902]]
[[-6.123046 -5.145837 7.891695 -0.3783728]]
[[-6.7471647 -5.1568007 7.3376994 -0.14631017]]
[[-5.768033 -6.0288777 9.360904 -1.9037125]]
[[-7.037687 -5.0647235 7.345336 1.0650041]]
[[-6.3333025 -4.003666 6.096233 2.0686429]]
[[-8.165305 -4.0971665 5.59594 4.208836 ]]
[[-6.3591156 -0.0809775 -2.1494312 5.8446784]]
[[-5.998541 -0.3071279 -1.633659 5.444659 ]]
[[-5.982375 -0.13737446 -2.0219755 5.588227 ]]
[[-6.2784123 -0.28474385 -1.8074901 5.720227 ]]
[[-5.9097333 0.21499354 -2.4844441 5.4800773 ]]
[[-5.815046 0.34615326 -2.749436 5.516311 ]]
[[-6.144201 0.20839332 -2.5092714 5.6507225 ]]
[[-6.217258 -0.11974069 -2.2099724 5.8341565 ]]
[[-6.0395765 0.08458082 -2.2998967 5.641852 ]]
[[-6.292765 -0.22815469 -1.8958219 5.7871137 ]]
[[-5.9349203 0.03097157 -2.209548 5.578063 ]]
[[-4.8454432 0.6837326 -2.8405902 4.569208 ]]
[[-5.5436296 -0.4322207 -1.2610528 5.0055714]]
[[-5.8578863 -0.32924837 -1.6607574 5.3581743 ]]
[[-5.7073674 0.08094054 -2.3335297 5.431057 ]]
Tensor(shape=[67, 1, 4], dtype=float32, place=CUDAPlace(0), stop_gradient=True,
[[[0.18607847, 0.76180643, 0.00790692, 0.04420818]],
[[0.21990354, 0.75249618, 0.00896723, 0.01863303]],
[[0.04347746, 0.87683898, 0.00152336, 0.07816018]],
[[0.31181487, 0.66678441, 0.00587796, 0.01552279]],
[[0.27809274, 0.65979725, 0.02074026, 0.04136980]],
[[0.51592660, 0.47112727, 0.00944741, 0.00349878]],
[[0.08482961, 0.83483732, 0.00363582, 0.07669736]],
[[0.58813888, 0.40553078, 0.00420919, 0.00212116]],
[[0.50240386, 0.48429418, 0.00554229, 0.00775965]],
[[0.27857813, 0.69674349, 0.01227855, 0.01239989]],
[[0.37013263, 0.60421354, 0.01008376, 0.01557007]],
[[0.31991184, 0.66306269, 0.01009506, 0.00693045]],
[[0.41515639, 0.57983309, 0.00429428, 0.00071625]],
[[0.21048497, 0.75708681, 0.01020809, 0.02222010]],
[[0.09612054, 0.88075089, 0.00227385, 0.02085473]],
[[0.37300166, 0.61655551, 0.00738223, 0.00306051]],
[[0.02863417, 0.78866822, 0.00148986, 0.18120776]],
[[0.00232973, 0.79350960, 0.00004836, 0.20411235]],
[[0.02143462, 0.87504727, 0.00058431, 0.10293392]],
[[0.00643685, 0.76924914, 0.00017670, 0.22413737]],
[[0.01332989, 0.83638644, 0.00023486, 0.15004875]],
[[0.01116226, 0.62454951, 0.00070716, 0.36358106]],
[[0.00290894, 0.66527551, 0.00008983, 0.33172569]],
[[0.00456953, 0.58538061, 0.00022136, 0.40982854]],
[[0.00792769, 0.75078166, 0.00026256, 0.24102813]],
[[0.00179510, 0.49116838, 0.00009976, 0.50693673]],
[[0.02448242, 0.73991507, 0.00121354, 0.23438902]],
[[0.02903091, 0.81717736, 0.00123135, 0.15256041]],
[[0.00527186, 0.87065840, 0.00014126, 0.12392850]],
[[0.00109510, 0.82885396, 0.00001529, 0.17003568]],
[[0.00550288, 0.83888549, 0.00016662, 0.15544505]],
[[0.02129946, 0.77363062, 0.00105744, 0.20401244]],
[[0.00120668, 0.75071740, 0.00002368, 0.24805219]],
[[0.01260382, 0.80315262, 0.00040434, 0.18383917]],
[[0.00000099, 0.00001980, 0.99510950, 0.00486970]],
[[0.00000000, 0.00000000, 0.99999475, 0.00000526]],
[[0.00000973, 0.00011000, 0.95056945, 0.04931074]],
[[0.00000071, 0.00000600, 0.99663687, 0.00335647]],
[[0.00000091, 0.00000722, 0.99401951, 0.00597238]],
[[0.00000000, 0.00000000, 0.99999321, 0.00000682]],
[[0.00000000, 0.00000000, 0.99998105, 0.00001892]],
[[0.00000248, 0.00003062, 0.97920632, 0.02076050]],
[[0.00003168, 0.00009718, 0.99681073, 0.00306045]],
[[0.00001052, 0.00007432, 0.98827934, 0.01163586]],
[[0.00000000, 0.00000001, 0.99993038, 0.00006964]],
[[0.00001010, 0.00000517, 0.99987948, 0.00010525]],
[[0.00000082, 0.00000218, 0.99974102, 0.00025600]],
[[0.00000076, 0.00000375, 0.99943382, 0.00056168]],
[[0.00000027, 0.00000021, 0.99998665, 0.00001282]],
[[0.00000057, 0.00000407, 0.99812609, 0.00186927]],
[[0.00000393, 0.00004036, 0.98245114, 0.01750455]],
[[0.00000084, 0.00004937, 0.80008936, 0.19986045]],
[[0.00000500, 0.00266204, 0.00033643, 0.99699652]],
[[0.00001068, 0.00316434, 0.00083980, 0.99598515]],
[[0.00000940, 0.00324916, 0.00049351, 0.99624795]],
[[0.00000613, 0.00245906, 0.00053635, 0.99699843]],
[[0.00001125, 0.00514054, 0.00034567, 0.99450254]],
[[0.00001192, 0.00565004, 0.00025565, 0.99408239]],
[[0.00000751, 0.00430946, 0.00028455, 0.99539846]],
[[0.00000582, 0.00258814, 0.00032005, 0.99708599]],
[[0.00000841, 0.00384306, 0.00035409, 0.99579442]],
[[0.00000566, 0.00243412, 0.00045929, 0.99710089]],
[[0.00000996, 0.00388200, 0.00041306, 0.99569499]],
[[0.00007983, 0.02011120, 0.00059271, 0.97921628]],
[[0.00002605, 0.00432196, 0.00188679, 0.99376523]],
[[0.00001340, 0.00337382, 0.00089095, 0.99572182]],
[[0.00001447, 0.00472310, 0.00042231, 0.99484009]]])
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py:125: DeprecationWarning: `np.object` is a deprecated alias for the builtin `object`. To silence this warning, use `object` by itself. Doing this will not modify any behavior and is safe.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
if data.dtype == np.object:
为了观察预测结果,我们还需要把标签转换一下:

['M2', 'M2', 'M2', 'M2', 'M2', 'B1', 'M2', 'B1', 'B1', 'M2', 'M2', 'M2', 'M2', 'M2', 'M2', 'M2', 'M2', 'M2', 'M2', 'M2', 'M2', 'M2', 'M2', 'M2', 'M2', 'S3', 'M2', 'M2', 'M2', 'M2', 'M2', 'M2', 'M2', 'M2', 'R0', 'R0', 'R0', 'R0', 'R0', 'R0', 'R0', 'R0', 'R0', 'R0', 'R0', 'R0', 'R0', 'R0', 'R0', 'R0', 'R0', 'R0', 'S3', 'S3', 'S3', 'S3', 'S3', 'S3', 'S3', 'S3', 'S3', 'S3', 'S3', 'S3', 'S3', 'S3', 'S3']
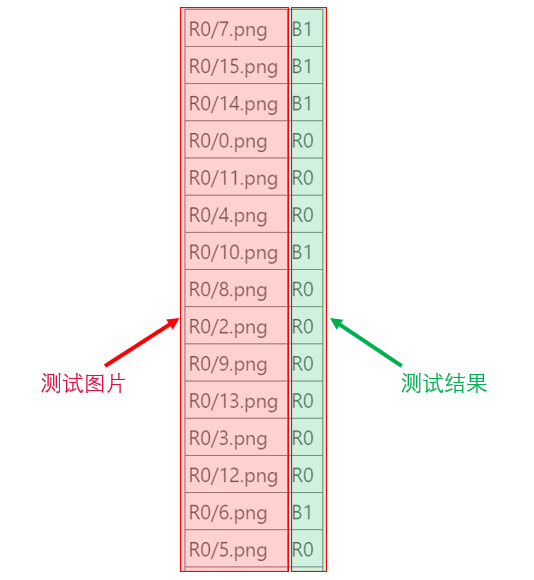
为了更直观的观察预测效果,我们生成一个result.csv文件,把预测的结果列在这个csv文件里,运行下面这段代码,就会在当前目录下生成一个result.csv文件。
打开result.csv文件,我们可以看到结果:
5.总结
本次实验,我们用paddlepaddle(飞桨)深度学习框架 搭建了一个 图像分类模型,完成了桃子的分类任务。
通过本次实验,我们学习了:
- paddlepaddle深度学习框架的使用方法;
- 如何用paddlepaddle深度学习框架搭建 桃子分类模型;
- 如何完成模型的训练、评估、保存、预测等深度学习工作过程;
图像分类任务是计算机视觉(CV)领域的基础性任务,虽然难度不大,但是却很重要,是其他计算机视觉任务的基石。我们一定要多动手,多调试代码,增加熟练程度,为更复杂的深度学习项目打下基础。