大家好,我是微学AI,今天给大家带来深度学习实战23(进阶版)-语义分割实战,实现人物图像抠图的效果。语义分割是计算机视觉中的一项重要任务,其目标是将图像中的每个像素都分配一个语义类别标签。与传统的目标检测或分类任务不同,语义分割不仅需要识别图像中存在的对象以及它们的位置,还需要对每个像素进行精细的分类。
一、计算机视觉中的语义分割应用
语义分割可以在许多应用中使用,例如自动驾驶车辆感知道路、医学图像分析中的肿瘤分割、视频监控中的行人追踪等等。通常情况下,语义分割使用卷积神经网络来完成,例如 U-Net、FCN、DeepLab 等。通过这些深度学习模型的训练和优化,我们可以更好地理解图像中的语义信息,并且可以实现高效准确的语义分割任务。
二、人物语义分割应用
要实现语义分割功能,我们需要使用预训练过的神经网络模型。我将使用DeepLabV3模型,可以在Pytorch中直接获取。
原始的DeepLab方法基于空洞卷积将全连接层替换为可学习的参数,以解决上采样问题。比较于普通的卷积,空洞卷积可以增加卷积核的感受野,从而保留更多的上下文信息。同时使用空洞率(dilation rate)可以一定程度上改变输出的分辨率。
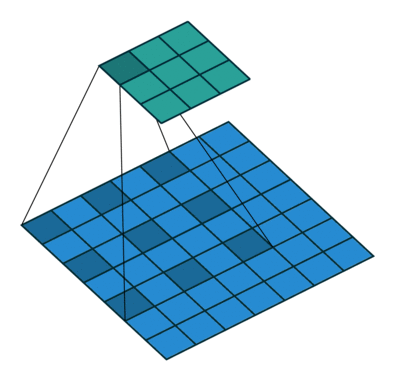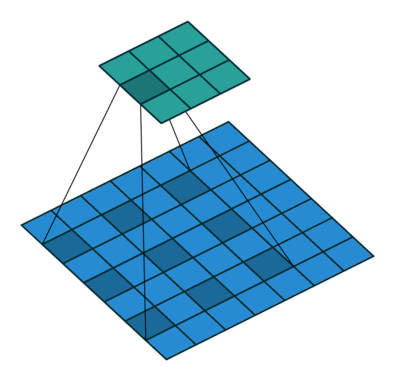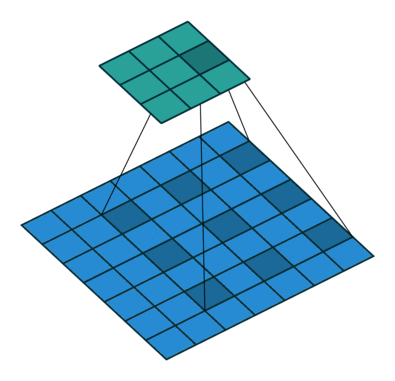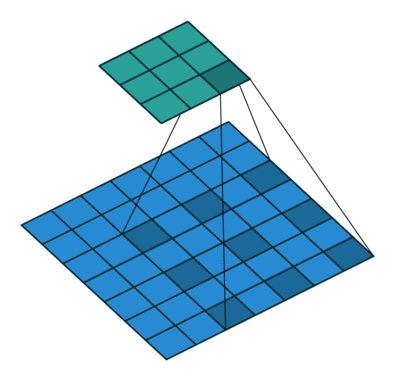
在传统的卷积操作中,每个卷积核只处理其邻近像素的信息,而使用空洞卷积后,卷积核可以 "看到" 更多的像素,即更大的感受野,从而能够更好地捕获图像中的全局信息。同时,空洞卷积还增加了卷积层的有效感受野大小,这样可以避免在保持分辨率的同时丢弃有用信息的问题。
空洞卷积创建案例:
import torch
# 定义空洞卷积层
conv = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, dilation=2)
# 定义输入
input = torch.randn(1, 3, 32, 32)
# 进行空洞卷积操作
output = conv(input)
# 查看输出形状
print(output.shape)三、DeepLabV3模型
在DeepLabV3中,使用了ASPP模块。ASPP是通过在空洞卷积中设置不同的采样率来捕捉图像中各种尺度的信息,这种多尺度信息获取方式可以帮助模型更好地捕捉到不同大小物体的轮廓和上下文信息。最后,将这些并行的分支进行平均池化和1x1卷积来融合,并上采样得到像素级别的分割结果。
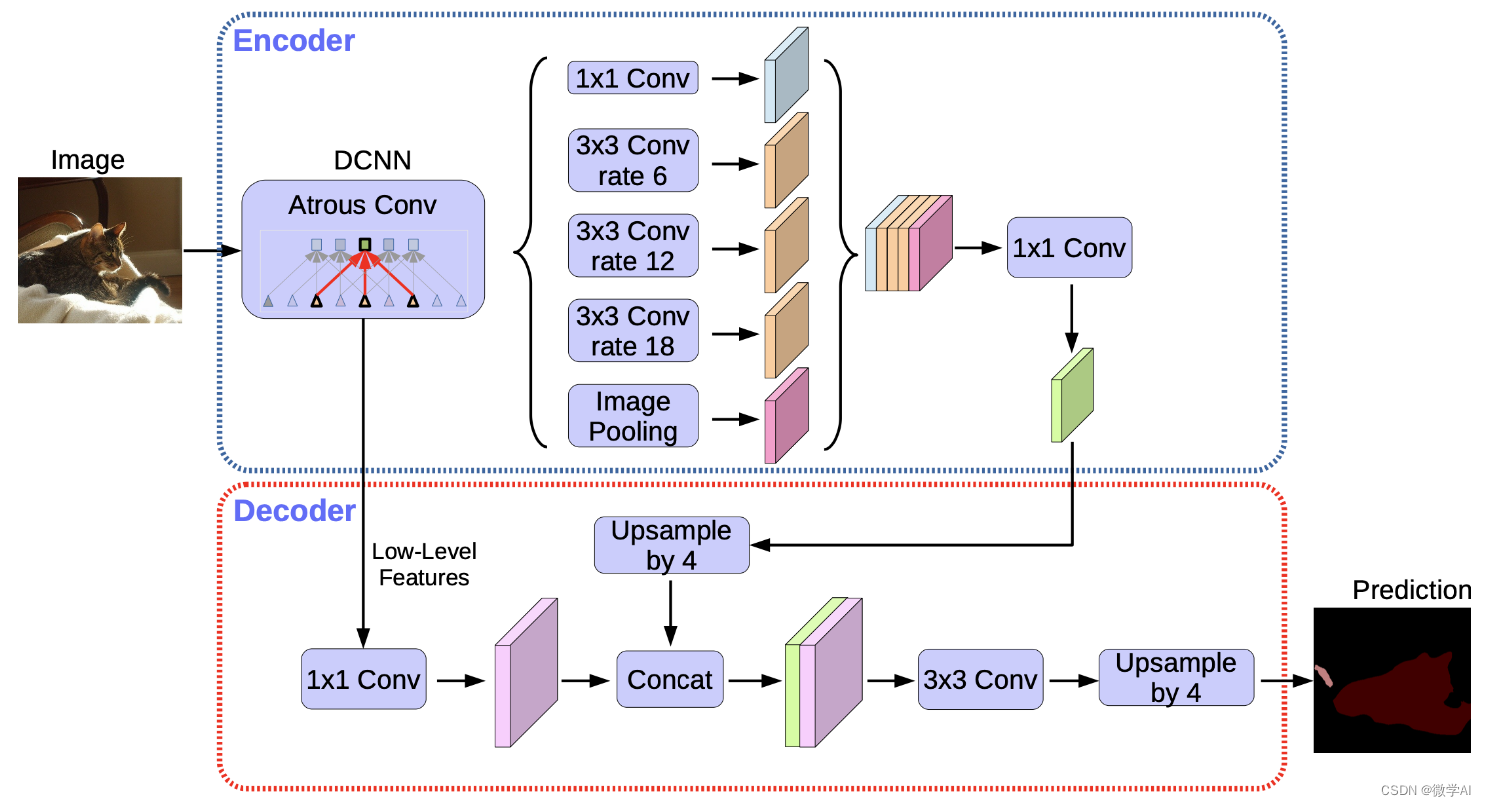
DeepLabV3模型训练过程:
1. 数据准备:准备带有像素级注释的图像数据集。例如,PASCAL VOC, Cityscapes或COCO等数据集。每个像素都需要有一个对应的标签,表示该像素属于哪个类别。
2. 数据增强:通过图像旋转、缩放、翻转等方式对训练数据进行增强,以增加训练数据的多样性并提高模型的泛化能力。
3. 网络构建:DeepLabV3包括一个用于特征提取的卷积神经网络(例如ResNet、Xception等)以及一个叫作ASPP(Atrous Spatial Pyramid Pooling,空洞空间金字塔池化)的模块。ASPP模块包含了多个不同采样率的空洞卷积层,用于捕捉不同尺度的信息。这些并行的分支在最后通过一个全局平均池化和一个1x1卷积层进行融合。
4. 损失函数:通常使用交叉熵损失来衡量模型预测结果和真实结果之间的差异。通过计算每个像素预测类别的概率分布与真实标签的概率分布之间的交叉熵损失,来更新模型的权重。
5. 优化算法:选择优化器(如SGD、Adam等)来最小化损失函数。通过不断地输入图像,模型进行前向传播并计算损失,然后通过反向传播来更新权重。
6. 模型训练:重复迭代优化步骤,直到达到一定的收敛条件,例如固定周期、损失平稳等。
7. 模型评估和验证:在验证集和测试集上评估模型的性能,根据需要调整超参数、网络结构等。
四、代码实现
import torch
import torchvision
import numpy as np
from PIL import Image
from torchvision import transforms
def segment_person(image_path, output_path):
# 加载预训练的DeepLabV3模型
model = torchvision.models.segmentation.deeplabv3_resnet101(pretrained=True)
model.eval()
# 读取图片并转换
input_image = Image.open(image_path).convert("RGB")
preprocess = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0)
#if torch.cuda.is_available():
input_batch = input_batch.to('cpu')
model.to('cpu')
with torch.no_grad():
output = model(input_batch)['out'][0]
output = torch.argmax(output, dim=0).byte().cpu().numpy()
# 人物语义分割标签 (在PASCAL VOC数据集中,人物用标签15表示)
output_person = (output == 15)
# 应用掩码
mask = output_person.astype(np.uint8) * 255
mask = Image.fromarray(mask)
masked_image = Image.composite(input_image.resize((256, 256)), Image.new('RGB', mask.size), mask)
masked_image.save(output_path)
# 使用方法
input_image_path = "111.png"
output_image_path = "222.png"
segment_person(input_image_path, output_image_path)运行结果:我们输入111.png图片, 输出222.png图片
图中的女生是通过AI生成的。有感兴趣AI生成图片的也可以关注:
深度学习实战9-文本生成图像-本地电脑实现text2img。
往期作品:
深度学习实战项目
3.深度学习实战3-文本卷积神经网络(TextCNN)新闻文本分类
4.深度学习实战4-卷积神经网络(DenseNet)数学图形识别+题目模式识别
5.深度学习实战5-卷积神经网络(CNN)中文OCR识别项目
6.深度学习实战6-卷积神经网络(Pytorch)+聚类分析实现空气质量与天气预测
9.深度学习实战9-文本生成图像-本地电脑实现text2img
10.深度学习实战10-数学公式识别-将图片转换为Latex(img2Latex)
11.深度学习实战11(进阶版)-BERT模型的微调应用-文本分类案例
12.深度学习实战12(进阶版)-利用Dewarp实现文本扭曲矫正
13.深度学习实战13(进阶版)-文本纠错功能,经常写错别字的小伙伴的福星
14.深度学习实战14(进阶版)-手写文字OCR识别,手写笔记也可以识别了
15.深度学习实战15(进阶版)-让机器进行阅读理解+你可以变成出题者提问
16.深度学习实战16(进阶版)-虚拟截图识别文字-可以做纸质合同和表格识别
17.深度学习实战17(进阶版)-智能辅助编辑平台系统的搭建与开发案例
18.深度学习实战18(进阶版)-NLP的15项任务大融合系统,可实现市面上你能想到的NLP任务
19.深度学习实战19(进阶版)-SpeakGPT的本地实现部署测试,基于ChatGPT在自己的平台实现SpeakGPT功能
20.深度学习实战20(进阶版)-文件智能搜索系统,可以根据文件内容进行关键词搜索,快速找到文件
21.深度学习实战21(进阶版)-AI实体百科搜索,任何名词都可搜索到的百科全书
22.深度学习实战22(进阶版)-AI漫画视频生成模型,做自己的漫画视频
...(待更新)