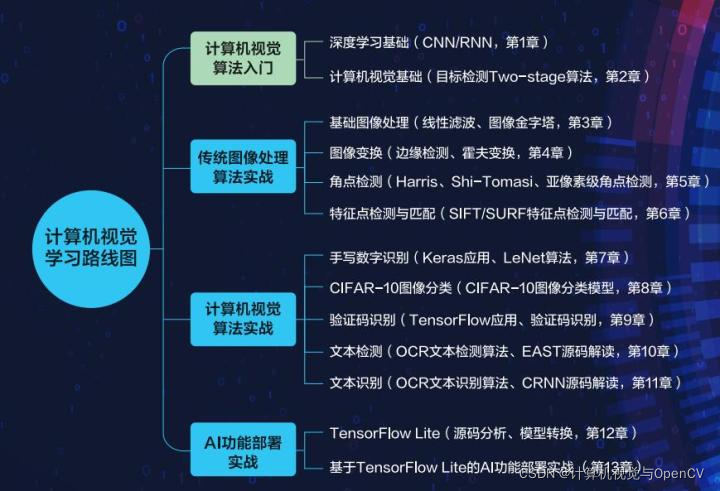
本文内容参考《深度学习计算机视觉实战》,该书内容包括深度学习与计算机视觉基础介绍、常用的OpenCV进行模型训练前处理与后处理算法、计算机视觉案例实战、Windows/Linux/Android/国产化平台的模型部署,学习路线如下:
Keras是最常见的深度学习库之一,能够帮助用户快速构建深度学习网络。Keras的张量计算依赖于处理后端,Keras中提供了Theano/Tensorflow/CNTK三种后端引擎,三种引擎的函数使用统一封装,在用户层面可以切换后端引擎,但是调用的API相同。
Keras提供了丰富的API用于模型的搭建与训练,本节介绍常用API,用户若想深入了解可以参考官方文档。

1 Keras模型
Keras中提供两种模型构建方法:构建顺序模型和使用函数式API构建的Model类模型。
顺序模型是网络层的线性叠加,使用Sequential()函数创建,可以将网络的层当做参数传入,如下所示传入了四个层,Conv2D(卷积层),Activation(激活层),Dense(全连接层),Activation(激活层)。
from keras.models import Sequential
from keras.layers import Conv2D, Dense, Activation
model = Sequential([
Conv2D(3, (3, 3), padding='same')(inputs),
Activation('Relu'),
Dense(10),
Activation('softmax'),
])
也可以创建一个空的模型,向里面添加层。
model = Sequential()
model.add(Conv2D(3, (3, 3), padding='same')(inputs))
model.add(Activation('Relu'))
model.add(Dense(10))
model.add(Activation('softmax'))
上面两种创建顺序模型的方式是等价的,使用顺序模型可以一层层的叠加模型的层。
函数式API的Model类模型由keras.Model()创建。
inputs = keras.Input(shape=(3,))
x = keras.layers.Dense(784, activation='Relu')(inputs)
outputs = keras.layers.Dense(10, activation='softmax')(x)
model = keras.Model(inputs=inputs, outputs=outputs)
除了这两种模型之外,还可以继承Keras.Model定制化创建自己的模型,这种方式具有更大的灵活性。
2 Keras层
Keras的层由keras.layers引入,常用的层有Conv2D,Dense,Activation,Input、MaxPooling2D、BatchNormalization、AveragePooling2D、Dropout、AveragePooling2D。
Conv2D:提供二维的卷积功能。
Dense:提供w*x+b的功能,和全连接类似。
Activation:提供激活函数功能。
Input:提供输入函数。
MaxPooling2D:提供最大池化功能。
AveragePooling2D:提供平均池化功能。
BatchNormalization:提供归一化功能。
Dropout:对输入应用Dropout功能。
这些函数层都是类的形式定义,传入的参数会初始化类成员,然后调用后端对应的功能函数,以MaxPooling2D为例,调用如下。
class MaxPooling2D(_Pooling2D):
@interfaces.legacy_pooling2d_support
def __init__(self, pool_size=(2, 2), strides=None, padding='valid',
data_format=None, **kwargs):
super(MaxPooling2D, self).__init__(pool_size, strides, padding,
data_format, **kwargs)
def _pooling_function(self, inputs, pool_size, strides,
padding, data_format):
output = K.pool2d(inputs, pool_size, strides,
padding, data_format,
pool_mode='max')
return output
MaxPooling2D传入的参数就是池化核大小pool_size,步长strides,padding的类型padding,数据类型data_format。在_pooling_function中调用某一个后端的pool2d函数。
Linux系统中可以在$HOME/.keras/keras.json中找到Keras配置文件,如果是Windows则是在%USERPROFILE%/.keras/keras.json中保存配置文件,内容如下所示:
{
"floatx": "float32",
"epsilon": 1e-07,
"backend": "tensorflow",
"image_data_format": "channels_last"
}
可以在这里修改后端为"tensorflow",“theano” 和 "cntk"中的一个,也可以使用用户自定义的后端,自定义后端需要定义了placeholder、variable以及function三个函数,否则会报后端无效的错误。
用户也可以通过设置环境变量KERAS_BACKEND来改变后端,设置之后会修改配置文件中的后端设置值。
3 模型编译
Keras中模型编译是通过compile方法完成的,如下所示,常用的三个参数为优化器optimizer,损失函数loss以及评价函数metrics。
model.compile(optimizer='rmsprop',
loss='mse',
metrics=['accuracy'])
开发者还可以根据需要设置其他的参数,compile的函数定义如下:
def compile(self,
optimizer, #优化器
loss=None, #损失函数
metrics=None, #评价函数
loss_weights=None, #指定不同损失函数的权重
sample_weight_mode=None, #采样权重模式
weighted_metrics=None, #加权评估标准
target_tensors=None, #指定自己的目标张量
**kwargs)
optimizer中提供了八种可选的优化器的类型:SGD、RMSprop、Adam、Adadelta、Adagrad、Adamax、Nadam、Ftrl。
loss为模型训练定义的损失函数,用户可以选择已有的损失函数,也可以自定义损失函数。使用时根据分类或者回归任务的不同选择不同的损失函数,如分类任务中常用的交叉熵损失函数keras.losses.categorical_crossentropy。如果模型具有多个输出,对应的多个损失函数可以通过字典或列表进行参数传递,这样在每个输出上使用不同的损失,最终的最小化损失是最小化所有输出损失的总和。
metrics为评价函数,用于评估当前训练模型的性能,是模型训练和测试期间的评估标准,如使用准确率作为标准可以传入metrics = [‘accuracy’],对于多输出模型可以用字典传递不同的评价函数。
4 模型训练
Keras模型训练使用fit函数。
model.fit(inputs, labels, epochs=10, batch_size=32)
如上面的调用传入了输入数据inputs,标签labels,训练轮次10轮,每一次梯度更新使用的样本数量大小为32(即batch的大小)。
fit函数还可以设置其他的参数,函数的定义如下:
def fit(self,
x=None, #输入数据
y=None, #标签label
batch_size=None, #训练batch大小
epochs=1, #训练轮次
verbose=1, #日志输出的方式
callbacks=None, #回调函数
validation_split=0., #验证集的比例
validation_data=None, #验证集
shuffle=True, #是否打乱样本顺序
class_weight=None, #为不同类别设置不同的权重
sample_weight=None, #样本加权
initial_epoch=0, #从指定epoch开始训练
steps_per_epoch=None, #每个epoch的步数
validation_steps=None, #若steps_per_epoch被指定,表示验证集上step总数
validation_freq=1, #验证集验证频次
max_queue_size=10, #生成器序列的最大值
workers=1, #最大线程数
use_multiprocessing=False, #是否多线程
**kwargs)
在训练的过程中可以根据需要选择合适的参数,例如是否需要使用验证集做验证,是否打乱输入数据,以及根据训练机器的性能选择是否使用多线程和设置最大的线程数。