一、3DAL
1.论文概述
由于论文的出发点是做一个离线的自动标注算法。所以没有太多的实时性和算力限制,模型可以做的大一点,融合的信息多一点(时序信息,离线没有因果关系,所以前后帧数据都可以用)。个人感觉整体思路和二阶段目标检测算法差不多,都是Coarse-to-Fine(由粗到细)的思想。
2.算法框架

第一步:输入点云序列,经过一个离线的目标检测算法(MVF++)得到每一帧的检测结果,同时通过目标跟踪(卡尔曼滤波)得到每个目标的整个轨迹序列。这一步得到的检测框较为粗糙。
第二步:已知目标检测框的轨迹序列和原始点云序列,将他们全部转换到世界坐标系下,同时我们把每个物体的点序列(检测框内的点)和框序列提取出来。这里点序列提取时,会把点提取范围扩大一点(也就是把框放大一点,防止由于粗糙检测框导致附近点云丢失)。这样我们得到一个物体的序列点和序列框,用于后续的box细化。
第三步:一个物体多帧点云和框都转到世界坐标系下之后,静态的物体点云会更加稠密完整,而动态的物体则会由于运行,点云会形成拖影。同时静止的物体我们希望在序列中只生成一个框,这样可以防止其抖动。所以论文中采用动静分离的方式来做refine。如果一个物体的连续轨迹大于7帧,我们才进行下面的操作,如果小于7帧,直接把检测结果当作最终标注结果。我们根据两个启发式特征(box中心的方差和box序列中开始结束位置偏差)送入一个线性分类器,来判断是静止物体还是运动物体。
第四步:动静态分别细化,根据物体序列点和box特征,对box的大小位置进行细化。下面细说。
3.一二阶段网络模型
MVF++模型改进

a.添加了一个语义分割的分支,用于判断每个点是否在框内。增强了点特征的区分能力。
b.使用anchor-free的方式
c.加大原始MVF++模型的大小,把普通的卷积块换为ResNet残差块。
整个模型提取完点特征之后,加上类似于pointpillar的结构来检测物体。
这里的反体素化操作就是直接把体素的特征赋值给在它里面的点。
静态物体自动标注
模型从不同帧中合并对象的点云,这时合并完是在世界坐标系下,选取一个score最大的框参数作为初始化box参数,然后把点云都转到box坐标系下(box中心为原点,车头为x正方向),这样有助于refine参数的学习。然后通过pointnet进行点的语义分割,判断哪些是前景点,对背景点进行过滤,然后再预测一个box refine参数,这个细化后的box,可以根据车辆的ego参数,转换到其他不同帧中去。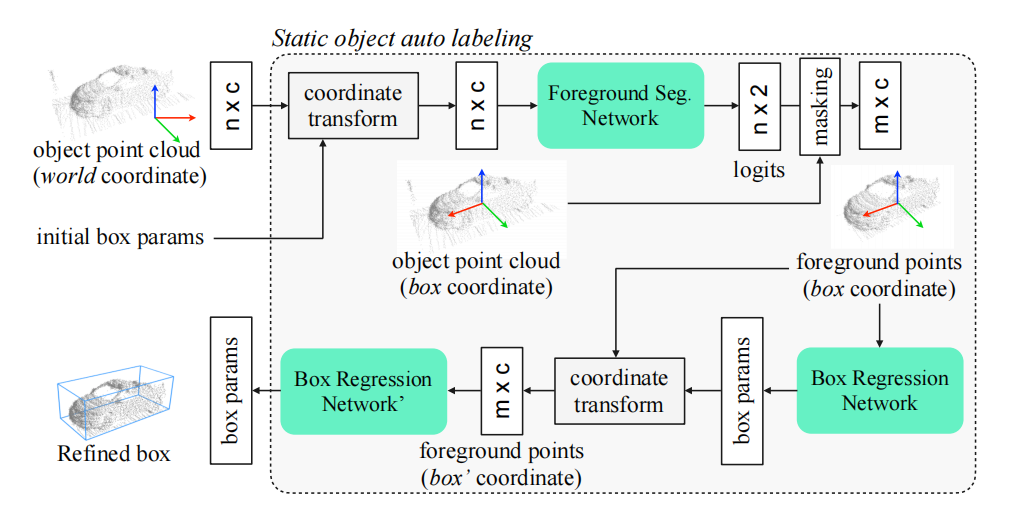
动态物体自动标注
对于一些列的box和box内的点,模型以滑动窗口的形式运行,并为当前框输出一个refine参数。
对于点云分支,提取当前帧物体的点以及前后各N(超参,论文为2)帧的点,每帧采样1024个点,并对他们添加一个时间维度的编码,所以传进去的是n * (c + 1),这些都需要转换到当前box的坐标系下,送入pointnet进行前景点分类,然后再编码得到一个C维的点编码特征。
对于box分支,提取前后多帧的box信息,这个帧数要比点云的多,是为了形成更长的轨迹序列。然后把他们转到当前box坐标系下,用pointnet编码得到C维的box编码特征。
把点编码特征和box编码特征concate,然后进行当前box的一个refine。
二、Auto4D
1.论文概述
本论文也是一种Coarse-to-Fine(由粗到细)的思想。但是和上一篇不同,其在第二阶段不是进行动静态物体分离细化。这篇文章是在二阶段预测运动不变的部分(框的大小)和运动变化的部分(框的位置和朝向角)。
2.算法框架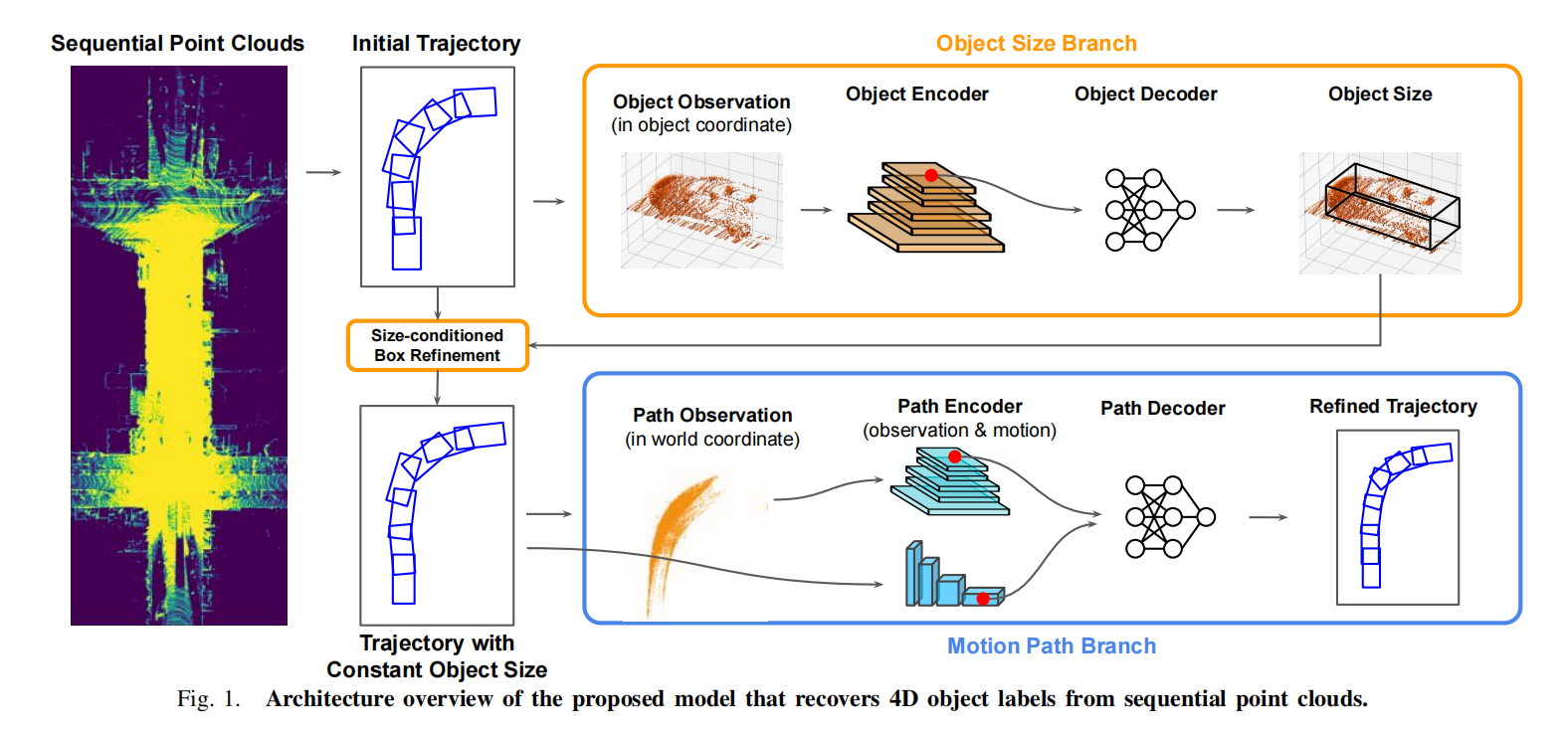
第一步:使用现成的检测器和跟踪器得到各个物体的轨迹序列。分别处理每个物体的序列。
第二步:物体大小细化分支,将box放大1.1倍,提取里面的点,然后所有帧的物体点都转到box坐标系下,对齐他们的中心位置和方向。将点云投到BEV上,进行2D特征提取生成C * H * W的特征。因为感受野足够大,我们直接提取框中心点对应的特征即可,双线性插值实现。这个特征经过一个MLP得到尺寸细化。利用整个轨迹的密集预测,物体大小分支可以产生更精确的表示。
第三步:物体大小分支预测的新的细化大小,用来更新轨迹上所有的检测框大小,这个检测框大小的更新分为两种,一种是中心点不变,更新长宽。另一种是角点对准,更新长宽。论文选用的后者。
第四步:运动路径分支细化,在世界坐标系下提取序列点云,并加入了时间编码。将点云高度和时间维度与特征通道合并,生成一个三维体素网格,然后CNN编码得到C * H * W的特征。同时提取运动特征,当前帧的xy以及角度减去前一帧的,得到运动偏移量。
然后将其送入一个UNetconv1d网络进行处理。将每帧的中心点的体素特征(双线性插值) + 运动特征送入MLP得到中心点的xy变化倍率和角度偏移。

3.消融实验
得到box修正大小后,基于中心点还是角点偏移,论文中这样说。因为一开始点云看到的往往都是离自车最近的那个角点附近的点云,所以模型初始预测的框框里,离自车最近的角点是最准的,所以我们以这个角点为基准,来对box的长宽进行修正。量化数据显示角点的指标比中心点高6%。
加上尺度修正分支,对于静态物体指标提升更高。
加上运动路径修正分支,对于动态物体指标提升更高。
三、Once Detected Never Lost
1.论文概述
经典三段式,检测+跟踪+细化。前面两篇工作的重心都在第三阶段。而本篇论文也着重强调了一下跟踪阶段。基于双向跟踪的模块和以跟踪为中心的学习模块达到了很好的效果。
2.算法框架
第一步:使用FSD提取特征,论文中这里进行了一些改进,除了传统的多帧连接,他还融入了未来帧的信息。同时为了利用更长的时间信息,而不增加算力开销,采取跳帧的策略。为了防止过拟合,对选取的帧数中的一半我们以20%的几率删除。
第二步:双向多目标跟踪。先使用immotal(不朽)跟踪器进行前向跟踪,他的思想是:因为物体在真实空间中不可能凭空消失,所以当一个轨迹在时间步中不匹配任何结果时,我们通过一个运动模型(基于卡尔曼滤波器的模型)来生成一个伪box,除非对象超出范围或者序列结束,否则物体轨迹永远都在。这样可以有效解决遮挡问题,但是也会导致许多假阳性,下面轨迹中心学习会进行优化。如果物体时间序列超过100帧,则直接扩展到序列结束,如果时间序列小于100帧,则只向后扩展20帧。反向跟踪,从最后一帧回溯到第一帧,以估计运动状态,然后根据运动状态接着往前扩展。
第三步:轨迹中心学习。
MIMO,多帧输入多帧输出。相对于MISO这样可以防止大小跳变。同时动静态不分类,论文认为这样会减少训练数据的多样性,从而阻碍了泛化。首先将所有轨道上的所有的box在三个维度扩大2m,然后在每一个时间步中裁剪点云(每个扩展的box只选1024个点),将他们转换到轨道第一帧的姿态,并连接在一起作为网络输入。为了区分不同的点和时间步长,我们给每个点添加了一个时间戳编码。
由于使用全长的序列作为输入,所以我们的范围是正负256m,然后体素化,使用一个稀疏的unet网络来提取体素特征。并通过插值将体素特征映射回他们包含的点的特征。用于后续的目标特征提取。
我们使用box(0.5m)来裁剪点特征,扩展一下,确保对象的完整性。然后使用pointnet提取box内点的特征。裁剪时也有其他时间戳的点在里面,这样可以获得更多的信息。而且有时间戳编码,网络也可以有效区分当前对象的形状。
3.其余创新
两阶段标签分配问题,首先先根据轨迹track iou来对轨迹进行匹配。然后轨迹匹配完,再对轨迹内部的box和GT进行关联。这样可以减少误匹配,让模型往整体轨迹最优的方向去优化。
四、DetZero
1.论文概述
整篇文章主要强调上游的高召回检测和跟踪,以及下游的高精度细化。以对象为中心基于滑窗来细化的方法不太好,因为它忽略了对对象特征共性的利用。所以我们更关注对象轨迹的完整性,使用注意力机制提取长时序信息对对象属性进行优化。
2.算法框架
第一步:采用centorpoint来进行检测,将5帧点云组合输入,同时添加时间编码。二阶段使用原始点特征+体素特征进行精确预测(这里的结构要再看一下相关论文),使用了TTA和模型增强预测。TTA是指对输入数据进行增强,然后再把检测结果和增强前的融合,模型增强论文里说的是融合三帧的结果和五帧的结果进行结合。
第二步:根据不朽跟踪器的方法,进行前向跟踪和反向跟踪,然后采用WBF来融合两次跟踪的框。同时采用两阶段的数据关联策略来减少错误匹配,根据box置信度,将其分为高分组和低分组,新检测的高分组先与现存的轨迹进行关联,成功关联的框用来更新现有轨迹,如果存在不关联的高分组box,将其生成新的轨迹,并加入低分组,而未更新的轨迹则与低分组进一步关联,剩下的没关联的低分组box被抛弃。
第三步:提取物体序列的box,以及里面的点,以及置信度。用于第三阶段的细化,下面是三个方向的细化,一个几何大小细化,一个位置细化模块,一个置信度细化模块。
3.细化模块详解
几何细化模块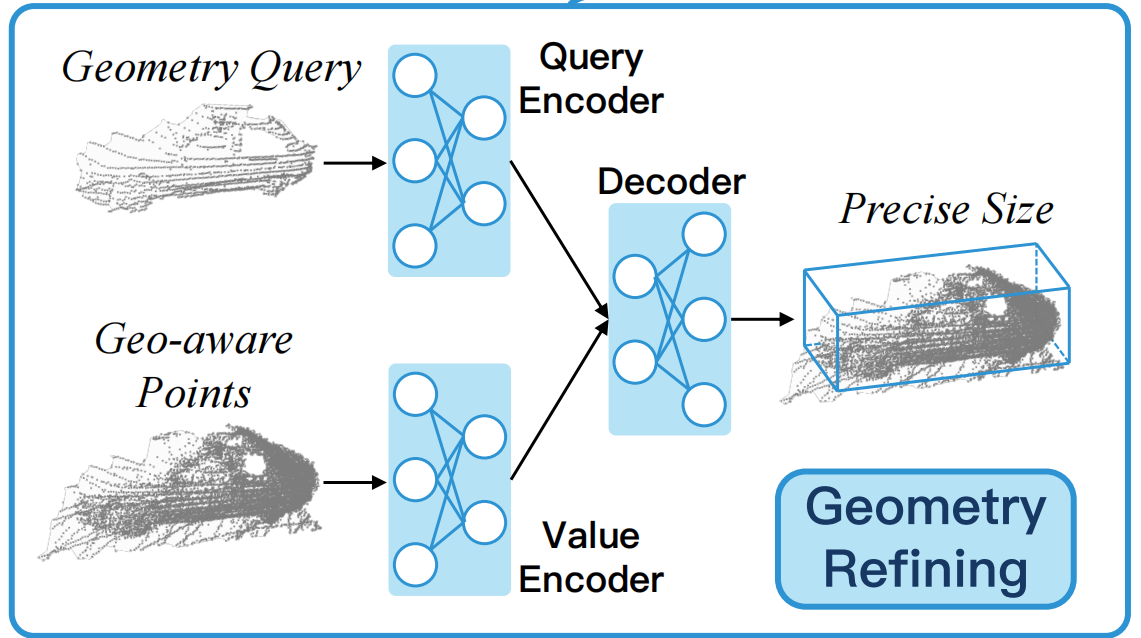
1.将不同帧的同一个对象在局部框坐标系下对齐,并将他们的点合并,随机抽取一组点n = 4096.
2.对于每个点计算他到box六个面的距离,同时加上box的置信度,丰富点的特征维度。 3.良好的Q初始化有利于transformer收敛,所以我们先从轨迹中选择T帧,每帧随机选择256个点,使用pointnet编码成T*D的维度。然后对4096个点使用一个pointnet提取密集点特征,得到K,V维度为n*D,Q先送进多头自注意力机制来编码选取样本之间丰富的上下文信息,然后QKV进行交叉注意力机制,再FFN,将T个查询特征解码为T个几何大小,求平均即可。
上面T的选取,训练时随机选3帧,推理时选取评分最高的三个。
位置细化模块
1.对于第i个物体,从轨迹中随机选择一个框作为新的局部坐标系,其他框和点都转移到该坐标系,每一帧选取固定的点。每一个点计算其到box中心和八个角点的距离,27维的特征。同时为了方便训练,我们用0把轨迹都填充到相同长度(200).
2.使用pointnet编码生成L*D的特征,L为轨迹的长度,D包含位置编码特征+置信度分数。另一个以所有采样点为输入,提取整个对象轨迹的点特征,npos*D,npos表示所有轨迹点。Q先送到自注意力模块里,捕获自己和其他box之间的距离。然后QKV交叉注意力机制,对局部到全局的位置进行编码,最终预测在局部坐标系下每个box中心点的偏移和角度的偏移。
置信度细化模块
因为上游生成足够长的轨迹,所以有很多假阳例,为此我们进行置信度细化。其有两个分支,第一个分类分支类似于二阶段的socre细化,第二个iou分支预测了一个对象细化后和GT的iou,最终把两个分数求平方根得到最终的置信度。训练时我们把跟踪的box和GT根据iou来分配正负样本,其余无贡献。选取1:1来计算损失,可以更好的收敛。使用pointnet编码特征对象的点,然后MLP送入两个head预测。
五、Reference
数据闭环的核心 - Auto-labeling 方案分享 V2.0 - 知乎 (zhihu.com)
数据闭环的核心 - Auto-labeling 方案分享 - 知乎 (zhihu.com)
这两篇文章是宏景智驾的3D感知负责人整理的,非常言简意赅,大家也可以看看。