文章:Cam4DOcc: Benchmark for Camera-Only 4D Occupancy Forecasting in Autonomous Driving Applications
作者:Junyi Ma, Xieyuanli Chen , Jiawei Huang, Jingyi Xu, Zhen Luo, Jintao Xu, Weihao Gu, Rui Ai, Hesheng Wang
编辑:点云PCL
欢迎各位加入知识星球,获取PDF论文,欢迎转发朋友圈。文章仅做学术分享,如有侵权联系删文。
公众号致力于点云处理,SLAM,三维视觉,高精地图等领域相关内容的干货分享,欢迎各位加入,有兴趣的可联系[email protected]。侵权或转载联系微信cloudpoint9527。
摘要
感知周围环境的变化对于在自动驾驶应用中安全可靠地执行下游任务是至关重要。最近仅使用摄像头图像进行的占据网格估计技术可以基于当前观测提供大规模场景的稠密占据表示。然而它们主要局限于表示当前的3D空间,不考虑沿时间轴的周围物体的未来状态。为了将仅使用摄像头的占据网格估计扩展到时空预测,本文提出了Cam4DOcc,这是一个新的基准用于摄像头仅进行4D占据网格预测,评估近期内周围场景的变化。基于多个公开可用的数据集构建了我们的基准,包括nuScenes、nuScenes-Occupancy和Lyft-Level5,这些数据集提供了一般可移动和静态对象的序列占据状态。为了为未来的研究建立这个基准,并进行全面的比较,这里引入了四种基线类型,涵盖了各种基于摄像头的感知和预测实现,包括静态世界占据模型、点云预测的体素化、基于2D-3D实例的预测,以及提出的新型端到端的4D占据网格预测网络。此外还提供了针对预设多任务的标准化评估方法,以比较所有提出的基线在自动驾驶场景中对感兴趣对象的当前和未来占据网格估计性能。Cam4DOcc基准的数据集和所有四个基线的实现将在这里发布:https://github.com/haomo-ai/Cam4DOcc。
主要贡献
尽管摄像头占据估计受到越来越多的关注,但现有方法仅估计当前和过去的占据网格状态。然而自动驾驶车辆采用的先进碰撞回避和轨迹优化方法需要能够预测未来的环境条件,以确保驾驶的安全性和可靠性。已经提出了一些语义/实例预测算法,用于预测感兴趣对象的运动,但它们主要局限于2D鸟瞰图(BEV)格式,只能识别特定对象,主要是车辆类别。至于现有的不考虑语义的占据预测算法,它们需要LiDAR点云作为必要的先验信息来感知周围的空间结构,而基于LiDAR的解决方案比摄像头解决方案更具环境感知的稠密性和昂贵性。可以预测自动驾驶领域中下一个重要的挑战将是仅使用摄像头进行4D占据预测。这项任务旨在不仅通过摄像头图像扩展时间上的占据预测,还要在BEV格式和预定义类别之外拓展语义/实例预测。为此提出了Cam4DOcc,如图1所示,这是第一个旨在促进基于摄像头的4D占据预测未来工作的基准,包括新格式的数据集、各种类型的基线和标准化的评估方法。在这个基准中,我们通过从原始nuScenes、nuScenes-Occupancy和Lyft-Level5中提取沿时间轴的连续占据变化来构建数据集,该数据集包括顺序语义和实例注释以及指示占据网格运动。此外为了实现基于摄像头的4D占据预测,我们介绍了四种基线方法,包括静态世界占据模型、点云预测的体素化、基于2D-3D实例的预测,以及一种端到端的4D占据预测网络。最后,我们使用提出的标准化方法评估了这些基线方法在当前和未来占据估计方面的性能。
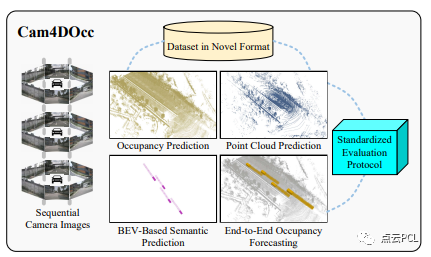
图1:Cam4Occ专注于提供一种新的数据集格式,创建根据现成的基于相机的感知和预测方法修改的基线,并提出4D占用网格预测任务的标准化评估方法
本文的主要贡献有四点:
(1)提出了Cam4DOcc,这是第一个旨在促进基于摄像头的4D占据网格预测未来工作的基准。
(2)通过利用该领域中现有数据集,为自动驾驶场景中的预测任务提出了一种新的数据集格式。
(3)为基于摄像头的4D占据预测提供了四种新颖的基线方法。其中三种是现成方法的扩展,此外介绍了一种新颖的端到端的4D占据预测网络,表现出色,可作为未来研究的有价值的参考。
(4)引入了一种新颖的标准化评估方法,并根据这一方法在我们的Cam4DOcc上进行了详细的分析的全面实验。
内容概述
Cam4DOcc关注两种运动特性的占据,即一般可移动对象(GMO)和一般静态对象(GSO),作为占据体素网格的语义标签。相对于GSO,GMO在交通活动中通常具有更高的动态运动特性,因此需要更多关注,考虑到安全原因。准确估计GMO的行为并预测它们潜在的运动变化对自动驾驶汽车的决策制定和运动规划有显著影响。Cam4DOcc与先前的任务不同,更专注于可移动对象的体素状态的持续变化,强调在自动驾驶应用中更多地关注交通参与者的运动特性。同时,与现有的语义/实例预测任务不同,Cam4DOcc不仅关注对邻近前景对象的预测,还注重对自动车辆更可靠导航需求的周围环境背景的占据估计。
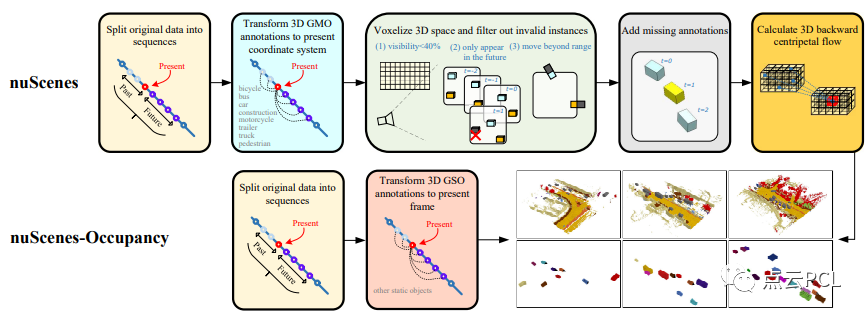
图2:在我们的Cam4Occ中基于原始nuScenes和nuScenes占用网格构建数据集的总体流程。数据集被重组为一种新的格式,该格式考虑了统一4D占用网格预测任务的一般可移动和静态类别。
Cam4DOcc基准提出了四种方法作为基线,用于辅助未来对仅基于摄像头的4D占据预测任务的比较,如图3所示。
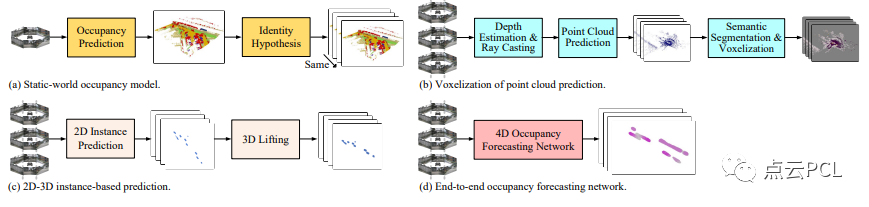
图3:从占用预测、点云预测和2D实例预测的扩展,以及我们的端到端4D占用预测网络,在Cam4Occ基准中提出了四种类型的基线。
静态世界占据网格模型:现有的基于摄像头的占据预测方法只能基于当前观察估计当前占据网格。因此,最直接的基线之一是假设环境在短时间间隔内保持静态。因此,我们可以使用当前估计的占据网格作为基于静态世界假设的所有未来时间步的预测,如图3a所示。
点云体素化预测:另一种基线可以是基于现有点云预测方法的点云体素化占据网格。在这里,我们使用全景深度估计生成跨多个摄像头的深度图,然后通过射线投射生成3D点云,该点云结合点云预测用于获取预测的未来伪点。基于此,我们然后应用基于点的语义分割来获取每个体素的可移动和静态标签,得出最终的占据预测,如图3b所示。
2D-3D基于实例的预测:许多现成的2D BEV实例预测方法可以使用全景摄像头图像预测未来的语义。第三种基线是通过沿着z轴复制BEV占据网格到车辆高度来获取3D空间中预测的GMO,如图3c所示。可以看出,该基线假设行驶表面是平坦的,并且所有移动对象具有相同的高度。我们不评估此基线对GSO的预测,因为通过复制来提升2D结果对于模拟比GMO更复杂结构的大型背景是不适当的。
端到端占据网格预测网络:以上基线都无法直接预测3D空间的未来占据状态。它们都需要基于某些假设进行额外的后处理,以扩展和转换现有结果为4D占据预测,不可避免地引入固有的伪影。为填补这一空白,我们提出了一种新方法,如图3d所示,以端到端的方式实现仅基于摄像头的4D占据预测。
端到端4D占据预测
据我们所知,目前不存在能够同时预测未来占据网格并以端到端方式提取3D通用对象的摄像头4D占据预测基线。本文介绍了一种新颖的端到端时空网络,命名为OCFNet,如图4所示。OCFNet接收顺序的过去全景摄像头图像以预测当前和未来的占据状态。它利用多帧特征聚合模块来提取扭曲的3D体素特征和未来状态预测模块,以预测未来的占据网格。
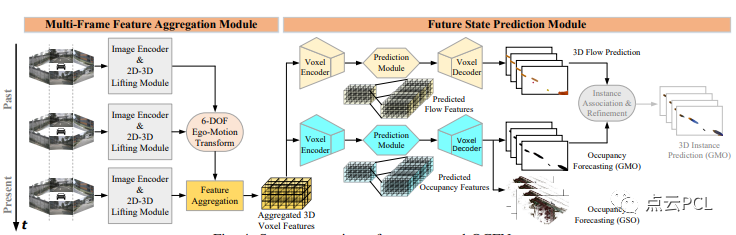
图4:我们提出的OCFNet的系统概述
实验
研究使用了Cam4DOcc基准,对提出的基线(包括我们的OCFNet)在自动驾驶场景中进行4项任务的占据估计和预测性能进行了评估。数据集使用nuScenes、nuScenes-Occupancy和Lyft-Level5的地面实况注释的场景,总共23930个训练序列和5119个测试序列。每个序列长度为7,以3个观察预测未来四个时间步的占据情况。序列的预定义范围为[-51.2 m,51.2 m]和[-5 m,3 m],体素分辨率为0.2 m。基线包括OpenOccupancy、SurroundDepth、PowerBEV-3D和提出的OCFNet。它们经过15轮AdamW优化器训练,使用8个A100 GPU,批量大小为8。这些基线模型使用了先进的基于摄像头的方法,涵盖了静态占据模型、点云预测、2D-3D实例预测和OCFNet。实验通过使用Cam4DOcc流标注,表明OCFNet在有限训练数据上也能生成良好的预测结果。
4D占据预测评估
对GMO的膨胀预测进行评估:第一个任务是对nuScenes和LyftLevel5上的膨胀GMO进行预测的结果如表I所示。在这里,OpenOccupancy-C、PowerBEV和OCFNet仅使用膨胀GMO标签进行训练,而PCPNet则通过全面的点云进行训练。
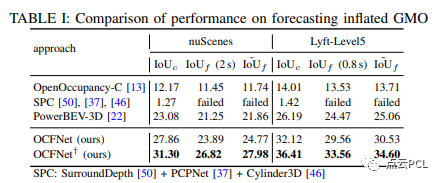
图5显示了由我们的OCFNet和CFNet†预测的nuScenes GMO占据情况的结果,表明仅使用有限数据训练的OCFNet仍然可以合理地捕捉GMO占据网格的运动。基线SPC在当前帧上效果不佳,甚至在预测未来占据状态时倾向于失败。这是因为在此任务中,可移动对象被标记为膨胀的密集体素网格,而PCPNet输出的体素化是从稀疏点级预测中得出的。此外,预测对象的形状在未来时间步骤中失去了一致性。OpenOccupancy-C的性能比点云预测基线好得多,但与PowerEBV-3D和OCFNet相比,仍然在估计当前占据和预测未来占据方面表现较弱。

图5:我们提出的OCFNet预测膨胀GMO的可视化
对细粒度GMO的预测评估:对具有nuScenes-Occupancy(第二级任务)的细粒度一般可移动对象进行占据估计和预测的性能。在表II中,我们展示了一旦GMO注释具有细粒度体素格式而不是在第一级任务中进行训练和评估时的膨胀格式时,预测对象的IoU如何变化。可以看到,由于使用过去的连续摄像机图像预测复杂的移动3D结构相当困难,除了点云预测基线之外,所有方法预测的GMO的IoU显著下降。
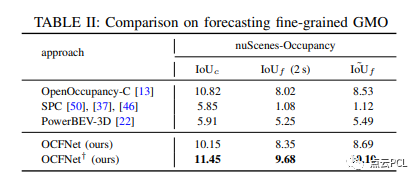
从表II中还可以看出,OCFNet和OCFNet†仍然具有最佳性能。这个实验揭示了Cam4DOcc为什么在占据预测任务中建议使用膨胀的GMO注释的原因:仅使用摄像机图像预测可移动对象的复杂未来3D结构非常困难,而预测膨胀的GMO可能促进更可靠和更安全的自动驾驶导航。
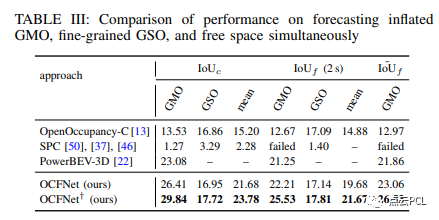
对膨胀GMO、细粒度GSO和自由空间的预测评估:比较了不同方法在预测膨胀的一般可移动对象、细粒度的一般静态对象和自由空间(第三级任务)上的性能。这里不报告基于2D-3D实例的预测的GSO结果,因为无法通过将2D体素格提升到3D空间来近似估计静态前景和背景对象的细粒度3D结构。实验结果显示在表III中。
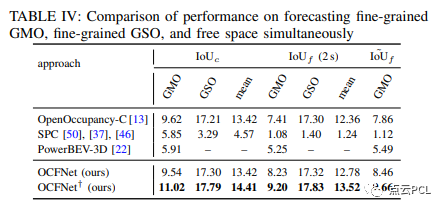
对细粒度GMO、细粒度GSO和自由空间的预测评估:在第四级任务中,只有OpenOccupancy-C和我们的OCFNet需要重新训练。如表IV所示,OCFNet†在预测细粒度关注对象方面仍然具有最佳性能,优于所有其他方法。
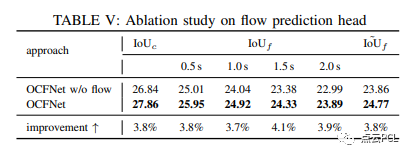
多任务学习的消融研究:在这个实验中,我们对流预测头进行了消融研究,以展示多任务学习方案的增强效果。如表V所示,完整的OCFNet相对于没有流预测头的模型,在当前和未来的占据网格估计中提高了约4%。
总结
本文提出了一种新的基准,即Cam4DOcc,用于自动驾驶应用中的新任务—仅利用摄像头进行4D占据预测。具体而言,首先基于几个公开可用的数据集创建了新格式的数据集。然后进一步提出了标准化的评估协议以及四种基线类型,为Cam4DOcc基准提供基本参考。此外提出了第一个基于摄像头的4D占据预测网络OCFNet,以端到端的方式估计未来的占据状态。基于我们的Cam4DOcc基准,进行了多个实验,涉及四种不同的任务,以全面评估所提出的基线以及我们的OCFNet。实验结果表明,OCFNet优于所有基线,并且即使在看到有限的训练数据时仍能产生合理的未来占据。
看法:通过比较四种不同类型的基线,我们证明了端到端时空网络可能是仅利用摄像头进行占据预测的最有前途的研究方向。此外,使用膨胀的GMO标注和额外的3D反向径向流也被验证对于4D占据预测是有益的。
局限性和未来工作:尽管OCFNet取得了显著的结果,但仅利用摄像头进行4D占据预测仍然具有挑战性,特别是对于在有许多移动对象的较长时间间隔内进行预测。我们的Cam4DOcc基准和全面的分析旨在加强对当前占据感知模型的优势和局限性的理解。我们将这个基准视为一个有价值的评估工具,而OCFNet可以作为未来研究4D占据预测任务的基础代码库。
资源
自动驾驶及定位相关分享
【点云论文速读】基于激光雷达的里程计及3D点云地图中的定位方法
自动驾驶中基于激光雷达的车辆道路和人行道实时检测(代码开源)
更多文章可查看:点云学习历史文章大汇总
SLAM及AR相关分享
结构化PLP-SLAM:单目、RGB-D和双目相机使用点线面的高效稀疏建图与定位方案
以上内容如有错误请留言评论,欢迎指正交流。如有侵权,请联系删除
让我们一起分享一起学习吧!期待有想法,乐于分享的小伙伴加入知识星球注入爱分享的新鲜活力。分享的主题包含但不限于三维视觉,点云,高精地图,自动驾驶,以及机器人等相关的领域。
分享与合作:微信“cloudpoint9527”(备注:姓名+学校/公司+研究方向) 联系邮箱:[email protected]。