调用百度云api,实现截图图片文字识别
相信大家在网上查找资料时都会遇到一些类似于pdf格式的文档,无法直接复制,手打太过于浪费时间。那么在这里我分享一个调用百度云api文字识别接口识别此类文字的python小程序。本人刚学习python时间不长,如果内容有错误还望斧正。
首先我们需要去 百度云官网申请一个接口
点击立即使用
创建应用
填写需要填写的数据后点击立即创建,即可创建成功
此时我们可以看到已建应用有一个,点击管理应用
这三个数据我们写代码的时候会使用到
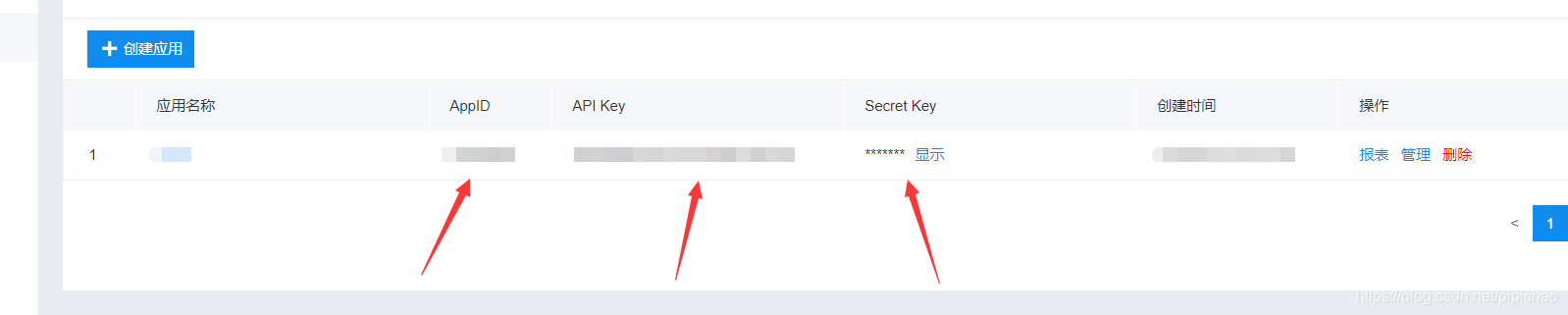
关于这个接口的费用问题,大家不需要担心,百度云给我们提供了 50000次/天免费完全可以满足大家的学习生活使用
做完了准备工作接下来就要开始代码部分了(本人使用 pycharm,python3)
首先我们需要安装几个包
pip install keyboard
#用于监控键盘事件
pip install Pillow
#用于截图后获取剪切板中的内容
pip install baidu_aip
#用于调用百度的文字识别接口
安装完成后我们正式开始写代码了
第一步导包
import keyboard
import time
from PIL import ImageGrab
from aip import AipOcr
定义截图方法,在这里我使用的是qq的截图工具
Ctrl + Alt+A
def jietu():
if keyboard.wait(hotkey="A+ctrl+alt")==None:#等待键盘输入截图命令,如果你喜欢使用其他的截图工具可以在这里更改
if keyboard.wait(hotkey="enter")==None: #截图结束后,按回车键继续向下运行程序
time.sleep(0.1) #这里必须进行等待,由于程序的运行速度快于截图的速度,如果不等待可能会出现获取不到图片或者识别上一张图片
im=ImageGrab.grabclipboard() #获取剪切板中的图片
im.save('b.jpg') #保存图片,这里我们使用一个固定的文件名,可以覆盖掉前一张图片,避免大量的图片占用电脑空间
截图完成后我们就要对被截取图片上的文字进行识别
class Baiduaip(object):
def __init__(self):
APPID = '********'
APIKey = '**********'
SecretKey = '************'
#以上三个数据就是我们在百度云申请到的,大家将自己申请到的填入其中即可
self.client = AipOcr(APPID,APIKey,SecretKey)
def getPicture(self):
with open('b.jpg','rb') as f:
return f.read()
#读取我们截取到的图片,并返回
def getText(self):
#这里进行请求并获取识别后的文字
image=self.getPicture()
#调用getPicture()方法,获取图片数据
text= self.client.basicGeneral(image)
words_list=text["words_result"]
#获取到的内容是字典格式,进行解析,words_result里面的内容是列表形式
for i in words_list:
word=i["words"]
return word
#获取到识别后的文字后,返回结果
在这里我们定义一个方法来执行我们定义好的方法,目的为了代码简洁明了,便于其他模块调用
def run():
jietu()
#先调用截图方法,进行截图
baiduaip=Baiduaip()
#将Baiduaip类实例化
word=baiduaip.getText()
#调用Baiduaip类的getText的方法进行文字识别
print(word)
#在屏幕上打印
return word
最后我们来执行一下
if __name__ == '__main__':
while 1:
run()
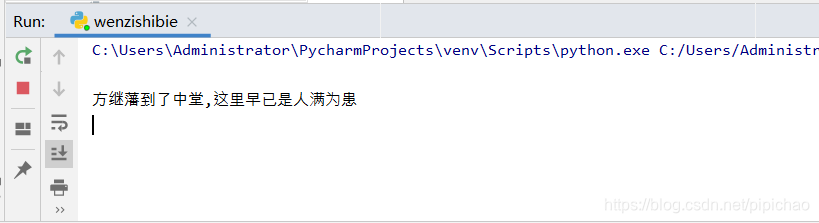
至此程序就写完了,我们找个网页截图实验一下
这是我截的图片

这是识别结果
这里给大家一个完整的程序,便于大家查看
import keyboard
import time
from PIL import ImageGrab
from aip import AipOcr
import re
class Baiduaip(object):
def __init__(self):
APPID = '**********'
APIKey = '************'
SecretKey = '***********'
self.client = AipOcr(APPID,APIKey,SecretKey)
def getPicture(self):
with open('b.jpg','rb') as f:
return f.read()
def getText(self):
image=self.getPicture()
text= self.client.basicGeneral(image)
words_list=text["words_result"]
for i in words_list:
word=i["words"]
return word
def jietu():
if keyboard.wait(hotkey="A+ctrl+alt")==None:
if keyboard.wait(hotkey="enter")==None:
time.sleep(0.1)
im=ImageGrab.grabclipboard()
im.save('b.jpg')
def run():
jietu()
baiduaip=Baiduaip()
word=baiduaip.getText()
print(word)
return word
if __name__ == '__main__':
while 1:
run()
如果我有什么错误或者大家有什么看不到的地方可以直接私聊我,我会进行改正。。。。。
