本文是对YOLO的全面解释,觉得有用请关注我的博客,YOLO的后续版本将会跟进哦!
物体检测object detection是计算机视觉中一个很热门的方向,前前后后也提出了很多很多不同的方法,但是在YOLO之前,大多是将其视为分类问题,而YOLO的出现,打破了这一局限,采用回归的方式来解决问题,并且取得了重大成果。
所谓“天下武功,唯快不破”说的正是速度的重要性,虽然之前的模型R-CNN系列等能达到较高的准确率,但是其速度实在是不可恭维,无法应用在实际场景中。而YOLO的一大优点就是检测速度非常快,在一块 Titan X GPU上能达到45FPS,也就是说已经real-time了。下面我们来看一下YOLO的version 1
一、概述
下图是YOLO的整体描述,就三个步骤:
- 将image大小缩放到448*448
- 以image为输入,经CNN处理,得到预测分类和位置的中间值
- 采用非极大值的方式,筛选结果

二、unified detection
作者提出的YOLO将预测分类和bounding box结合在一起,是一个end-to-end的模型,和之前提出的分阶段模型有极大区别,因此称之为统一检测(unified detection)
-
首先,作者提出的模型将输入图像划分成S x S 个网格(7个),如果存在某个物体a,其中心落入网格 i 中,那么预测物体 a 的任务就交给网格 i 去完成。
-
其次,每个网格预测 B 个bounding box和置信分数confidence score,confidence score意味着是否存在物体的概率以及对预测的bounding box准确性的判断,常用下式表达。从式子中不难看出,如果没有物体存在的话,那么confidence score应该是0,否则我们应该等于预测的bounding box与真实的bounding box之间的IOU(因为P=1)
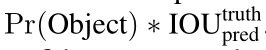
-
每个bounding box包含以下五个值:x, y, w, h, confidence.
(x,y)表示predicted bounding box的center坐标
w, h 分别表示预测的宽度和高度(这个宽度和高度是相对于整张图片的,这也和实际相符,因为一个物体可能占据整张图片)
confidence代表了预测的bounding box和任何ground truth box的IOU -
每个网格同时也预测C个条件概率,表示存在物体的条件下,这个物体是类别Ci 的概率,用下式表示。并且每个网格只预测一次,无论有多少个bounding box。
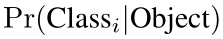
在测试的时候,我们将4中的概率和2中的概率相乘,就得到了某物体属于某类别Ci的概率和IOU的乘积。这一数字衡量了某物体属于某类别以及预测的bounding box的准确度
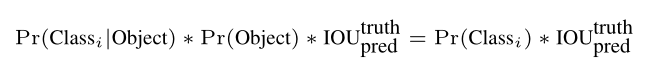
由以上分析可知,我们所预测的向量的size是:
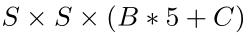
并且,对于PASCAL VOC数据集来说,我们取 S = 7,B=2,C = 20
因此,我们最后预测的tensor大小为7 x 7 x 30
三、CNN architecture
上面详尽的阐述了YOLO的基本思路,接下来就应该要设计CNN的网络结构了。
大致的思路是:卷积层提取图像特征,全连接层输出概率和坐标等信息。
作者给出的网络架构受到了GoogLenet的启发,一共有24层卷积层和2层全连接层,使用1 x 1和 3 x 3 的卷积核。下图是网络结构

- Training
选取了网络结构,接下来就是训练的过程。
现在的训练过程都不会从随机赋值开始了,几乎都是采用迁移学习的方式,所以先要有预训练pretraining
pretraining过程:
使用上述网络结构中的一部分——前20层卷积层+1层平均池化+1层全连接层
输入数据:ImageNet 2012
效果:top-5准确率在88%,可以和GoogLenet相媲美
training过程
加入4层卷积层和2层全连接层,新加入的层的所有参数都随机初始化,其余的参数用上述已经pretraining的数。检测和分类有很大区别,检测可能会牵涉到细粒度的问题,因此将输入从224 x 224 转换成448 x 448。
最后一层输出概率的同时也输出了coordinate,我们将bounding box的w, h都除以图像的weight和height,这样可以让w, h 范围缩放到0-1。同时,x,y也转换成相对于特定网格的偏移offset,这样x,y也在0-1范围。
关于激活函数:最后一层使用线性函数,其余都使用leaky rectified activation:
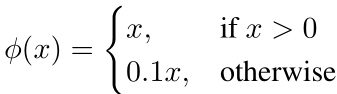
关于损失函数:使用均方误差(因为易于优化)。考虑到classification和localization应该占据不同的比例,所以设置了比例系数lambda。权衡利弊后,设置如下权重:
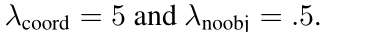
损失函数如下:
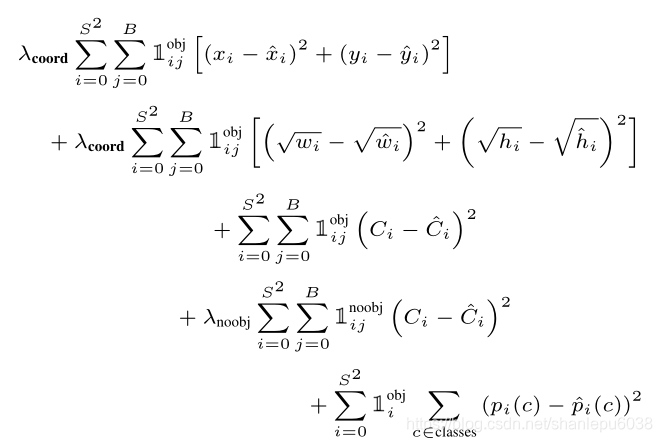
观察上述Loss Function,请注意:
i)使用了指示函数,因为只需要惩罚存在object的条件下误分类以及预测bounding box不准的情况。因为如果不存在object,直接为0.
ii)上面对于w,h的损失使用了根号进行处理,原因是如果不使用根号,那么对于100和10大小的bounding box,如果预测的是110,20,那么结果是一样的,但是从实际角度出发,很显然是不同的,而且差距非常大,使用根号进行处理就能很好的避免这种情况。
接下来是训练的相关说明:
在PASCAL VOC 2007 和2012数据集上训练135 epoch。训练过程中的一些参数选取:
batch_size = 64
momentum = 0.9
decay = 0.0005
learning_rate:第一个epoch,从10−3 缓慢增长到10−2,后面75个epoch采用10−2,再后面30个epoch采用10−3,最后30个epoch采用10−4
dropout = 0.5
另外,使用随机变换的方式进行data augmentation

训练过程中还牵涉到前向传播:
在前向传播过程中,除了和平常的CNN一样进行卷积、激活、池化、全连接之外,还有一个非常重要的点就是非极大值抑制。
由于一些比较大的物体可能会造成多个网格来预测的情况,因此需要采取非极大值抑制的方式来防止重合,也能获得更加精确的解。实验证明,采取非极大值抑制后,mAP能提高2到3个百分点
四、缺点
YOLO-v1不是完美无缺的,它也有一些缺点,或者说是局限性(比起之前的model来说):
- 由于每个网格只预测2个bounding box,因此如果一个网格中出现多于两个物体的情况,肯定是无能为力的,比如一群鸟。
- 由于网络模型对input image进行了多次降采样,因此对于细粒度的物体不能很好的分辨
- 定位很不精确
五、实验结果
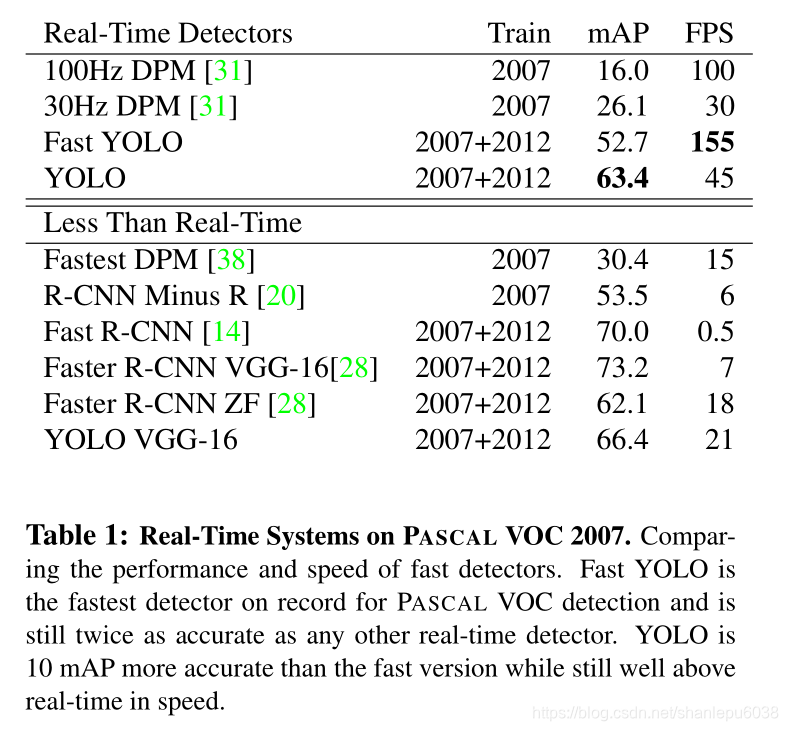
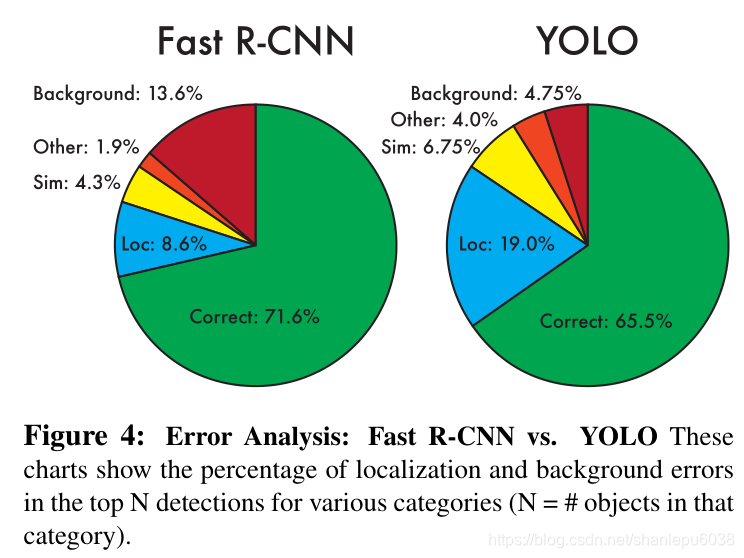
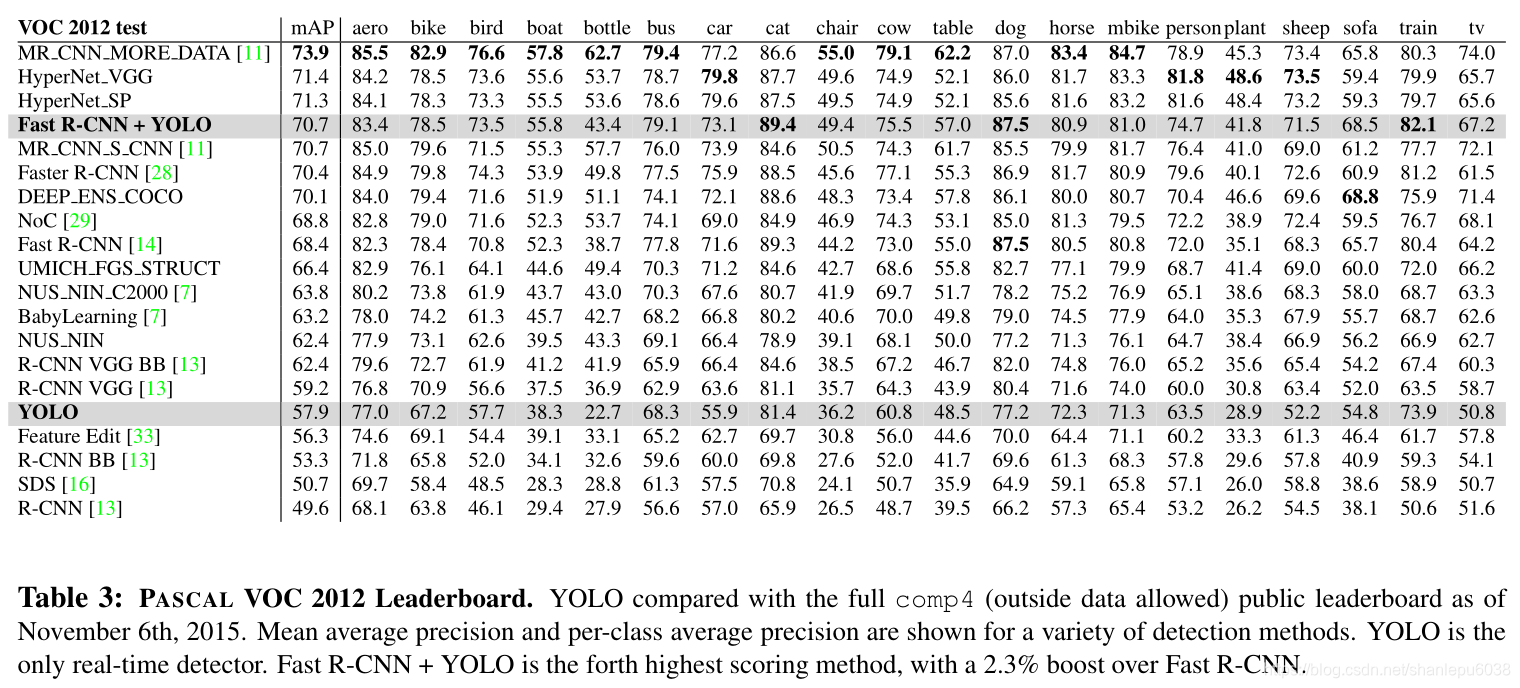
最后,YOLO在当时真的是非常不错的模型,之后又出现了YOLO-v2/3等模型,是对YOLO的改进,更加有效。