简历原文

抽查部分
- 基本了解RabbitMQ、Elasticsearch等微服务技术,对分布式事务、分布式缓存等有所学习;
- 熟悉数据库的基本操作,写过C#与数据库交互的项目;
模拟问答
1.你是如何保障消息可靠性的
从消息生产者到交换机,用return回调保证消息可靠性,这是消息级可靠,放在消息中定义;
从交换机到队列,用confirm回调保障消息可靠性,这是对象级可靠,放在template中定义;
从交换机到队列,做消息的持久化;
以上是发送的可靠性保障。
然后消费的可靠保障,就设置消息重试,包括发送消息重试、消费者重试,还有重试失败后的入库。
2.es有哪些数据类型?
常见类型:
- 数字类型:long integer short byte double float half_float scaled_float unsigned_long
- 关键字:
keyword 用于索引的关键字
constant_keyword 始终包含相同值的关键字字段
wildcard 可用于通配符模糊查询的关键字 - 时间类型dates:包括date和date_nanos。
- 别名alias
- 文本text:分词查询的文本。
对象关系类型:
- object:单个JSON对象
- nested:JSON对象数组
- join:定义同一索引中的文档的父子关系
结构化类型:
- geo-point:维度、经度
- geo-shape:描述多边形等形状的
- point:笛卡尔坐标点
- shape:笛卡尔任意集合图形
3.你是用什么做分布式事务的,能介绍一下吗
我用的是Seata做分布式事务管理的。
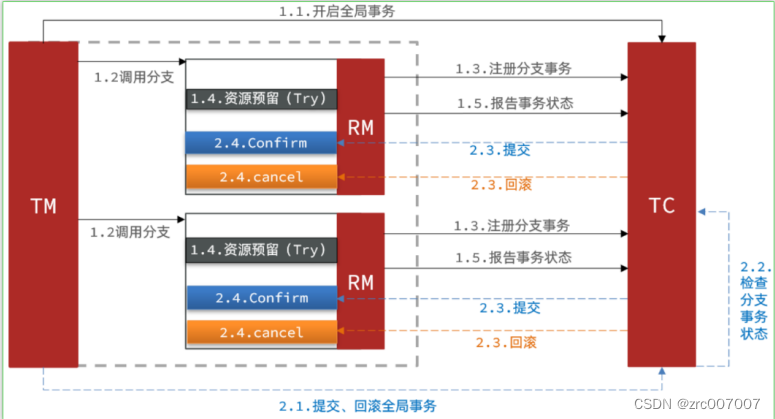
Seata事务管理中有3个角色,分别是事务协调者TC(Transaction Coordinator)、事务管理器TM(Transaction Manager)还有资源管理器RM(Resource Manager)。可以简单理解为公司里的Boss、领导和员工。而公司一般有3中运营模式:
①XA模式

第一阶段
首先Boss定方向,要开始做项目了,叫领导们开始管员工,员工上班打卡(1.1开启全局事务 1.2调用分支 1.3注册分支事务)
然后员工开始做事(1.4执行业务sql,但不提交)
然后员工报告给boss(1.5报告事务状态)
第二阶段
然后领导说boss你看看着项目咱还要不要接着干,要不要重新干,要不要finish(2.1提交、回滚全局事务)
boss看项目的报表,看事情办的怎么样(2.2检查分支事务状态)
boss一看,哎呀这A组没办好啊,给我重新做!(①如果有失败,通知所有RM回滚事务)
或者boss一看,哎呀办的不错啊,好,项目做完了,放假放假,发奖金发奖金(②如果都成功,通知所有RM提交事务)
XA模式牺牲了可用性,保证了强一致性
这是什么意思呢?就是3个组程序组客户组扫地组在干活,程序组写完项目了,扫地组地也拖好了(RM执行分支业务sql),兴致勃勃的跑到办公室准备把结果告诉给boss,让他完结项目,领奖金假期了(TC提交事务),结果看到boss黑着脸在拉着A组员工一顿训,原来是客户组办事不力,全员摸鱼(RM中有的事务失败),好了,这下项目失败了,啥也别想了,假期泡汤了,奖金飞走了,啥也不说了,项目只能推倒重来了。
你说程序组扫地组气不气?气死了,把客户组成员祖宗十八代给*¥%^&,但你说他们咋想的?看到客户组成员后来陪着笑脸发了3天零食,看到客户小姐姐快要哭出来的眼睛,还是想,哎,咱还是一个team,对内对外都要一致,不一起搞出来项目还是不去找客户了
②AT模式
AT模式也大差不差。

第一阶段
boss投钱开始搞项目(1.1开启全局事务),叫领导开管(1.2调用分支),员工开始上班打卡(1.3注册分支事务),开始做事(1.4执行业务sql并提交),做完之后报告(1.5报告事务状态)
不同的地方在于,这次程序组客户组扫地组都留了个心眼,程序做完一部分代码就买一部分服务,客户组小姐姐陪完一个客户就拉到公司搞定一个,扫地组每天都勤勤恳恳扫地让老板看见……(1.4执行业务sql并提交)
第二阶段
第二阶段也大差不差,领导提议要不要继续下去(2.1提交、回滚全局事务),boss检查项目做的怎么样(2.2检查分支事务状态),boss觉得做的好项目就finish了(2.3提交)客户资料就放那垫桌角生灰去了(2.4删除log),做的不好就不干了/重新做(2.3回滚),顺便把客户绑回来叫他把程序吐出来(2.5恢复log数据)。
正按这个流程走呢,结果第二天扫地组出去度假了,地没拖好,boss进门滑了一跤,摔进了icu,好,项目又泡汤了。
AT模式牺牲了一致性,保证了可用性
接下来该咋办?程序组呆在家里突突突、博德之门3去了,客户组出去陪小姐姐了,扫地组哭天喊地去了,项目搞完了把我晾在一边,拿着我的工资享受,还把我给摔了,躺在病床上的boss越想越气,越想越气,于是把呼吸机的管拔了,拄着拐杖一瘸一拐的来到公司,直接把客户资料和服务器都烧了。
AT模式在事务失败的情况下,保证了微服务对外提供服务,但最终的状态一致性无法保证。一旦出问题,还是要把之前处理好的业务推倒重来。
③TCC模式
就点拨一句,TCC就相当于员工影分身,一个分身3个,一个人干活,一个人准备成功情况给boss报喜,一个准备失败了赶紧删资料跑路。
优点是一致性、可用性都很高,缺点是代码量很大
4.你说你学习了分布式缓存,你们处理了缓存穿透问题吗
我们碰到了缓存穿透问题,并作了相应处理。
缓存穿透说的是这样一个问题:如果一个数据在各个多级缓存包括数据库中,比如Redis和MySQL中都没有,那么我在查询的时候每次都会进入数据库查询,这就会造成资源被占用,恶意利用可能会导致服务器崩溃。
一种解决方法是将这个key值置null放入缓存。但这样空占空间,最后可能导致业务数据都没地方放。
还有一种比较合理成熟的方案,就是采用布隆过滤器。
布隆过滤器将传输进来的数据根据算法,映射到一个二进制向量/位图上。
我们将所有已有的数据传入,根据哈希算法,映射到位图上。接下来传入其他数据,再用哈希算法检验,如果得出结果为1,则说明有数据,则放行访问;如果结果为0,说明没有,则直接返回。
值得注意的是,只有一个哈希算法时,检验结果可能很不准确,大量不存在的数据可能还是能访问到穿透的地方。这时候我们可以引入更多的不同的哈希算法,来进行检验,增加数据的准确性。
但过多的哈希算法,又会带来性能的下降。所以我们一般用适当数量的哈希算法。
5.有没有做过数据库优化,怎么做呢
就拿MySQL来说吧。对于需要优化的,查询慢的数据库,分三种情况讨论:
- 单条SQL运行慢
- 部分SQL运行慢
- 整个SQL运行慢
单条SQL运行慢
对于第一种情况,单条SQL运行慢,一般有两种常见原因:
- 未正常创建或使用索引
- 表中数据量太多了
首先,我们检查是否正常创建了索引;
然后,检查是否正常触发了索引查询。
以下情况不能触发索引,应该避免:
-
在 where 子句中使用 != 或者 <> 操作符,查询引用进行的是全表扫描;
-
前导模糊查询时触发的时全索引扫描或全表扫描,因为它不能利用索引的顺序、得一个个去找。也就是查询时不能用这样的字段: '%XX' 或 '%XX%';
-
带有条件or,or条件中不是每个列都有索引时。这时候必须在每个列上面都加上索引才能触发索引查询;
-
在 where 子句中对字段进行表达式操作。
以下技巧可以优化索引查询的速度:
-
尽量使用主键查询,而非其他索引,因为主键查询不会触发回表查询;
-
查询语句尽可能简单,大语句拆小语句,减少锁时间;
-
尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型;
-
用 exists 替代 in 查询;
-
避免在索引列上使用 is null 和 is not null。
其次,对于数据量过大的数据库,我们可以作数据拆分。
数据拆分分为垂直拆分和水平拆分。
垂直拆分一般这样来拆分:
-
把不常用的字段单独放在一张表;
-
把 text,blog 等大字段拆分出来放在附表中;
-
经常组合查询的列放在一张表中。
表的行数一般超过200万行时,查询就会变慢。这时候就可以拆分成多个表来存放数据。 这就是水平拆分。
部分SQL运行慢
为了定位这些慢查询的SQL,我们可以开启慢查询分析。
整个SQL运行慢
我们可以进行读写分离。
6.简单介绍一下你这个C#数据库项目
我这是一个自动拨叉脚整形机项目,从前端WPF界面输入数据,然后传入后端,存入数据库;还可以从前端输入拨叉数据,然后调用机器学习模型,得到预测结果显示到WPF界面上。