梳理最近一篇来自浙大和阿里等单位的自监督学习用于时间序列的综述文章,对理解自监督学习和时间序列的应用有一定帮助~
自监督学习简介
自监督学习(Self-Supervised Learning,简称SSL)是一种机器学习方法,它从未标记的数据中提取监督信号,属于无监督学习的一个子集。该方法通过创建”预设任务“让模型从数据中学习,从而生成有用的表示,可以用于后续任务。它不需要额外的人工标签数据,因为监督信号直接从数据本身派生。通过设计精良的预设任务,自监督学习在计算机视觉(CV)和自然语言处理(NLP)等领域取得了很大的成功。
这些预设任务通常需要模型通过数据的某种形式预测其它部分。例如,在自然语言处理任务中,预设任务可能包括:屏蔽某些单词,然后预测它们(称为“掩码语言模型”),或者重新排列句子的顺序,然后让模型找出正确的顺序。在计算机视觉中,预设任务可能包括:预测图像的某部分的颜色,或者确定图像的某些部分是否被扭曲或旋转等。
自监督学习的一个重要优点是,它能从大量未标记的数据中学习,而这些数据通常比标记数据更容易获得。此外,由于这种方法不依赖于人工标签,因此可以减少标签错误的影响。自我监督学习在多种任务中都显示出了与监督学习相媲美的性能,这使得它在处理各种实际问题时具有巨大的潜力。
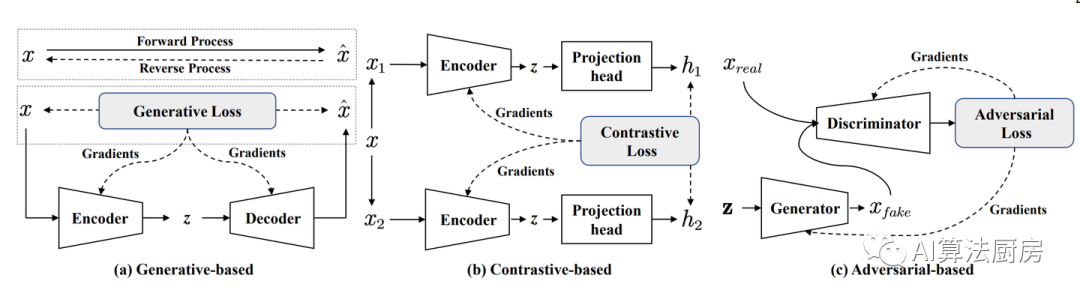
自我监督学习(SSL)的方法通常可以分为三类:
基于生成的方法:这种方法首先使用编码器将输入x映射到表示z,然后使用解码器从z重构x。训练目标是最小化输入和重构输入之间的重构误差。一个常见的基于生成的SSL的例子是自编码器(autoencoders),它们通过最小化原始输入和重构输入之间的误差来学习输入数据的有效表示。
基于对比的方法:这是最广泛使用的SSL策略之一,它通过数据增强或上下文采样构建正样本和负样本。然后通过最大化两个正样本之间的互信息(Mutual Information)来训练模型。对比方法通常使用对比相似度度量,例如InfoNCE loss。一个著名的基于对比的方法的例子是SimCLR,它通过对比原始图像和增强图像的表示来学习有效的图像表示。
基于对抗的方法:这种方法通常由一个生成器和一个判别器组成。生成器生成假样本,而判别器用来区分它们和真实样本。这种方法的一种典型应用是生成对抗网络(GANs),它们通过对抗过程在生成器和判别器之间找到平衡,以生成逼真的假样本并改进生成器的性能。
基于生成的方法
在时间序列建模的背景下,常用的预设任务包括使用过去的序列来预测未来的窗口或特定的时间戳,使用编码器和解码器来重构输入,以及预测被遮盖时间序列的不可见部分。
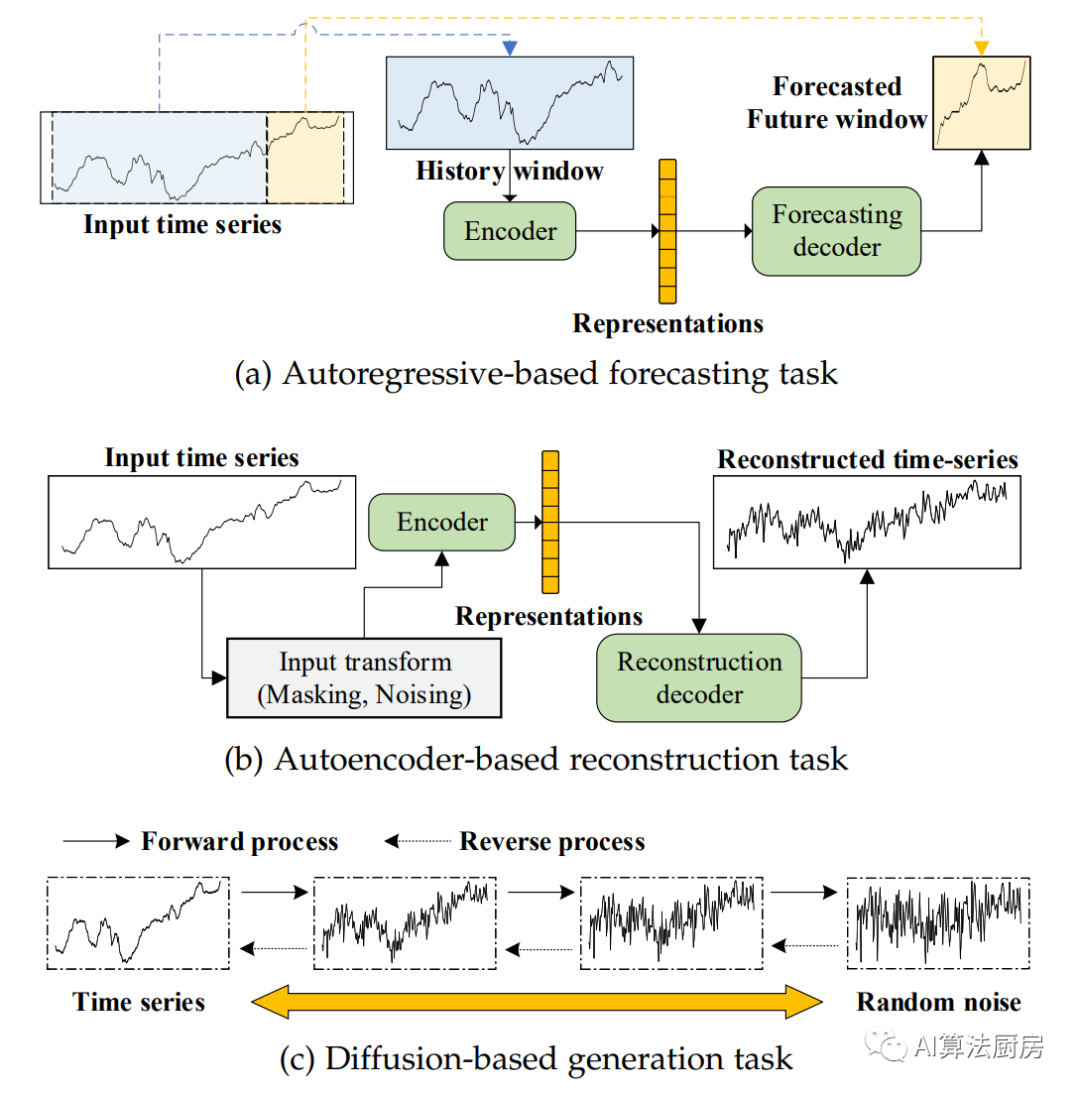
基于自回归的预测
这种方法试图使用过去的序列(例如,时间序列的先前值)来预测未来的值。
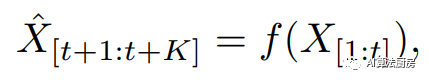
其中就是单步预测,大于1就是多步预测,为预测函数;学习的损失函数则是希望预测的未来值和真实值尽可能相近
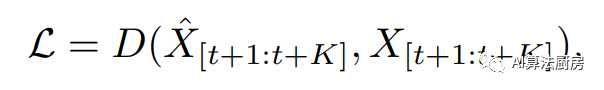
其中是一种距离的描述,比如可以是MSE。
相关工作:THOC构建了一个用于多分辨率单步预测的自我监督预设任务,称为时间自监督(TSS)。TSS采用带有跳跃连接结构的L层膨胀RNN作为模型。通过设置跳跃长度,可以确保预测任务可以在不同的分辨率上同时进行。STraTS首先将时间序列数据编码为三元表示,以避免在建模不规则和稀疏的时间序列数据时使用基础RNN和CNN的限制,然后构建基于Transformer的预测模型,用于建模多元医疗临床时间序列。基于图的时间序列预测方法也可以被用作自我监督的预设任务。与RNN和CNN相比,图神经网络(GNNs)可以更好地捕捉多元时间序列数据中变量之间的相关性,例如GDN。与上述方法不同,SSTSC提出了一个基于“过去-锚点-未来”策略的时间关系学习预测任务作为自我监督预设任务。SSTSC并不直接预测未来时间窗口的值,而是预测时间窗口的关系,这可以充分挖掘数据中的时间关系结构。
基于自编码器的重构
自编码器是由编码器和解码器组成的无监督人工神经网络。编码器将输入映射到表示,然后解码器将表示重新映射回输入。解码器的输出被定义为重构的输入。
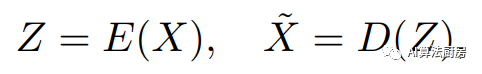
其中和分别表示编码器和解码器,可以是任意形式的神经网络,学习的损失函数则是希望重构的误差尽可能小
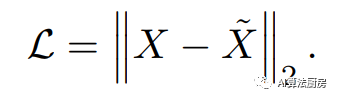
相关工作:TimeNet、PT-LSTM-SAE和Autowarp都使用RNN来构建包括编码器和解码器的序列自编码器模型,模型试图重构输入序列。一旦模型被学习,编码器就被用作特征提取器,获取时间序列样本的嵌入表示,这可以帮助下游任务,如分类和预测,达到更好的性能。
然而,通过重构误差获得的表示是任务无关的。因此,可以考虑引入额外的训练约束。Abdulaal等人关注复杂的异步多元时间序列数据,并在自编码器模型中引入谱分析。通过学习数据中的相位信息,提取时间序列的同步表示,最终用于异常检测任务。DTCR是一个对时间聚类友好的表示学习模型。它在重构任务中引入了K-means约束,使得学习到的表示对聚类任务更友好。USAD使用一个编码器和两个解码器来构建一个自编码器模型,并引入对抗训练,以增强模型的表示能力。FuSAGNet在稀疏自编码器上引入图学习,以明确地建模多元时间序列中的关系。
基于扩散模型的生成
作为一种新型的深度生成模型,扩散模型最近在许多领域,包括图像合成、视频生成、语音生成、生物信息学和自然语言处理等,都取得了巨大的成功,这归功于它们强大的生成能力。
扩散模型的关键设计包含两个相反的过程:注入随机噪声破坏数据的前向过程,以及从噪声分布(通常是正态分布)生成样本的反向过程。目前主要有三种基本的扩散模型形式:去噪扩散概率模型(DDPMs)、分数匹配扩散模型和分数SDEs。
相关工作:条件分数扩散模型用于插补(CSDI)提出了一种新的时间序列插补方法,该方法利用基于观测数据的分数扩散模型。它被训练用于插补,可以很容易地通过在时间序列序列的末端插入数据进行预测。为了处理实际中无法访问真实缺失值的问题,还提出了一种自我监督的训练过程,其中的值被标记为缺失值以训练整个架构。此外,也有几项工作利用扩散模型来预测时间序列。TimeGrad使用某一时间步的条件扩散概率模型来描述固定的前向过程和学习到的反向过程。在处理阶段,时间序列的交叉相关性也被描绘出来。它是一种用于多元时间序列预测的自回归模型,通过优化最小化模型的负对数似然的参数来学习梯度。
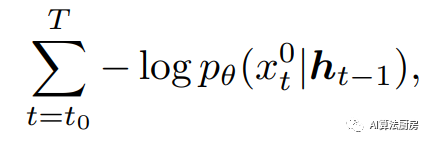
基于对比的方法
对比学习是一种广泛使用的自监督学习策略,在计算机视觉和自然语言处理中表现出强大的学习能力。与学习映射规则至真实标签的判别模型和尝试重构输入的生成模型不同,基于对比的方法旨在通过正样本和负样本的对比来学习数据表示。具体而言,正样本应具有类似的表示,而负样本应具有不同的表示。因此,正样本和负样本的选择对于基于对比的方法非常重要。

采样对比法
采样对比法遵循时间序列分析中广泛使用的假设,即两个相邻的时间窗口或时间戳具有高度的相似性,因此,正样本和负样本直接从原始时间序列中采样。具体来说,给定一个时间窗口(或时间戳)作为锚,其附近的窗口(或时间戳)更有可能相似(距离小),而远离的窗口(或时间戳)应该较不相似(距离大)。"相似"意味着两个窗口(或两个时间戳)具有更多的公共模式,如同样的幅度、同样的周期性和同样的趋势。
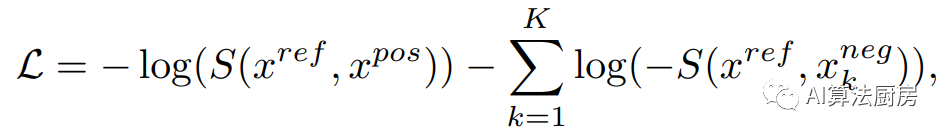
预测对比法
在这一类别中,使用上下文(现在的信息)来预测目标(未来的信息)的预测任务被视为自监督预文任务,目标是最大限度地保留上下文和目标的互信息。对比预测编码(CPC)提供了一个对比学习框架,使用InfoNCE损失执行预测任务。具体来说,上下文和样本构成正对,而“提议”分布中的样本是负样本。学习的损失函数为
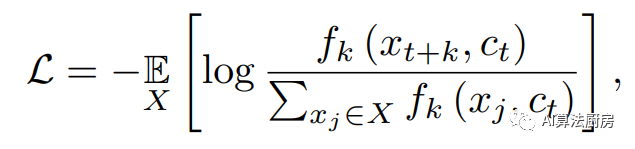
CPC并没有直接预测未来的观测值,而是试图保留和的互信息。这使得模型能够捕获跨越多个时间步的“慢特征”。基于CPC的结构,提出了LNT、TRL-CPC、TS-CP2和Skip-Step CPC。LNT和TRL-CPC使用与原始CPC相同的结构来构建表示学习模型,目的是通过捕获时间的局部语义来检测异常点。TS-CP2和Skip-Step CPC将原始CPC结构中的自回归模型替换为TCN,这提高了特征学习能力和计算效率。此外,Skip-Step CPC指出,调整上下文表示和之间的距离可以构建不同的正样本对,这会导致时间序列异常检测的不同结果。CMLF将时间序列转换为粗粒度和细粒度的表示,并提出了一种多粒度预测任务。这使得模型能够在不同的尺度上表示时间序列。
增强对比法
增强对比法是最广泛使用的对比框架之一。大多数方法利用数据增强技术生成输入样本的不同视图,然后通过最大化来自同一样本的视图的相似性,并最小化来自不同样本的视图的相似性来学习表示。SimCLR是一个非常典型的基于多视图不变性的表示学习框架,已被许多后续方法所采用。这一框架下的损失函数通常为
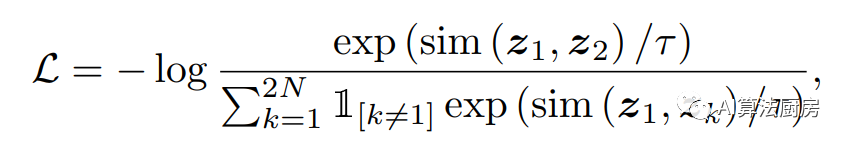
时间序列的增强方法需要同时考虑时间和变量依赖性,这与图像的增强方法有所不同。
由于时间序列数据可以通过傅立叶变换转化为频率域的表示形式,因此可以在时间域和频率域中开发增强方法。在时间域中,TS-TCC及其扩展版本CA-TCC设计了两种时间序列数据增强技术——强增强(Permutation-and-Jitter)和弱增强(Jitter-and-Scale)。另一项方法,TS2Vec,通过随机遮蔽某些时间步来生成不同的视图。总的来说,选择何种数据增强方法并没有统一的标准答案。
在频率域的数据增强对于时间序列数据也是可行的。有一种季节趋势表示学习方法,名为 CoST,它使用快速傅立叶变换将不同的增强视图转换为幅度和相位表示,然后通过特定的训练模型来训练这些视图。另一种方法,BTSF,是一种基于时间-频率融合策略的对比方法。BTSF首先通过dropout操作在时间域生成一个增强视图,然后通过傅立叶变换在频率域生成另一个增强视图。最后,利用双线性时频融合机制实现时频信息的融合。然而,CoST 和 BTSF 并未直接修改频率表示。相比之下,TF-C 则是第一项通过频率扰动来增强时间序列数据的工作,其表现超过了TS2Vec和TS-TCC。TF-C实现了三种增强策略:低频对高频的扰动,单组件对多组件的扰动,以及随机对分布的扰动。
原型对比法
原型对比学习框架本质上是一种实例区分任务,它鼓励样本在特征空间中形成均匀分布。然而,真实的数据分布应满足同类样本更集中在一个聚类中,而不同聚类间的距离应更远。在真实标签可用时,SCL是一个理想的解决方案,但在实践中,特别是对于时间序列数据,这很难实现。因此,将聚类约束引入到现有的对比学习框架中是一种替代方案,如CC,PCL,和SwAV。PCL和SwAV将样本与构建的原型,即聚类中心,进行对比,这降低了计算量,并鼓励样本在特征空间中呈现出对聚类友好的分布。
在基于原型对比的时间序列建模中,ShapeNet以Shaplets为输入,并构造了一种聚类级别的三元组损失,考虑了锚点与多个正(负)样本之间的距离,以及正(负)样本之间的距离。ShapeNet是一种隐式的原型对比,因为它在训练阶段没有引入显式的原型(聚类中心)。而TapNet和VSML是显式的原型对比,因为它们引入了显式的原型。TapNet为每个预定义的类别引入了一个可学习的原型,并根据输入的时间序列样本与每个类别原型之间的距离来进行分类。VSML定义了虚拟序列,这些序列与原型具有相同的功能,即最小化样本与虚拟序列之间的距离,但最大化虚拟序列之间的距离。
MHCCL提出了一种基于向上遮罩策略的分层聚类以及基于向下遮罩策略的对比对选择策略。在向上遮罩策略中,MHCCL认为离群值对原型影响很大,因此在更新原型时应移除这些离群值。反过来,向下遮罩策略使用聚类结果来选择正样本和负样本,即,属于同一原型的样本被视为真正的正样本,而属于不同原型的样本被视为真正的负样本。
专家知识对比法
专家知识对比是一种相对较新的表示学习框架。一般来说,这种建模框架将专家的先验知识或信息融入到深度神经网络中,以指导模型的训练。在对比学习框架中,先验知识可以帮助模型在训练过程中选择正确的正样本和负样本。
比如Shi等人使用了时间序列样本的DTW距离作为先验信息,并认为两个距离小的样本具有更高的相似性。具体来说,给定锚点和另外两个样本,首先计算锚点与另外两个样本之间的DTW距离,然后将与锚点距离小的样本视为锚点的正样本。
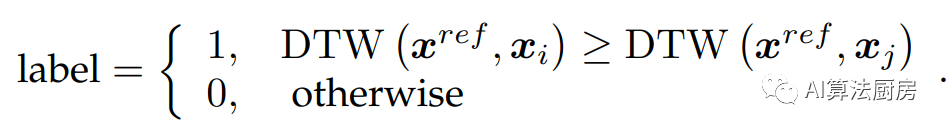
基于对抗的方法
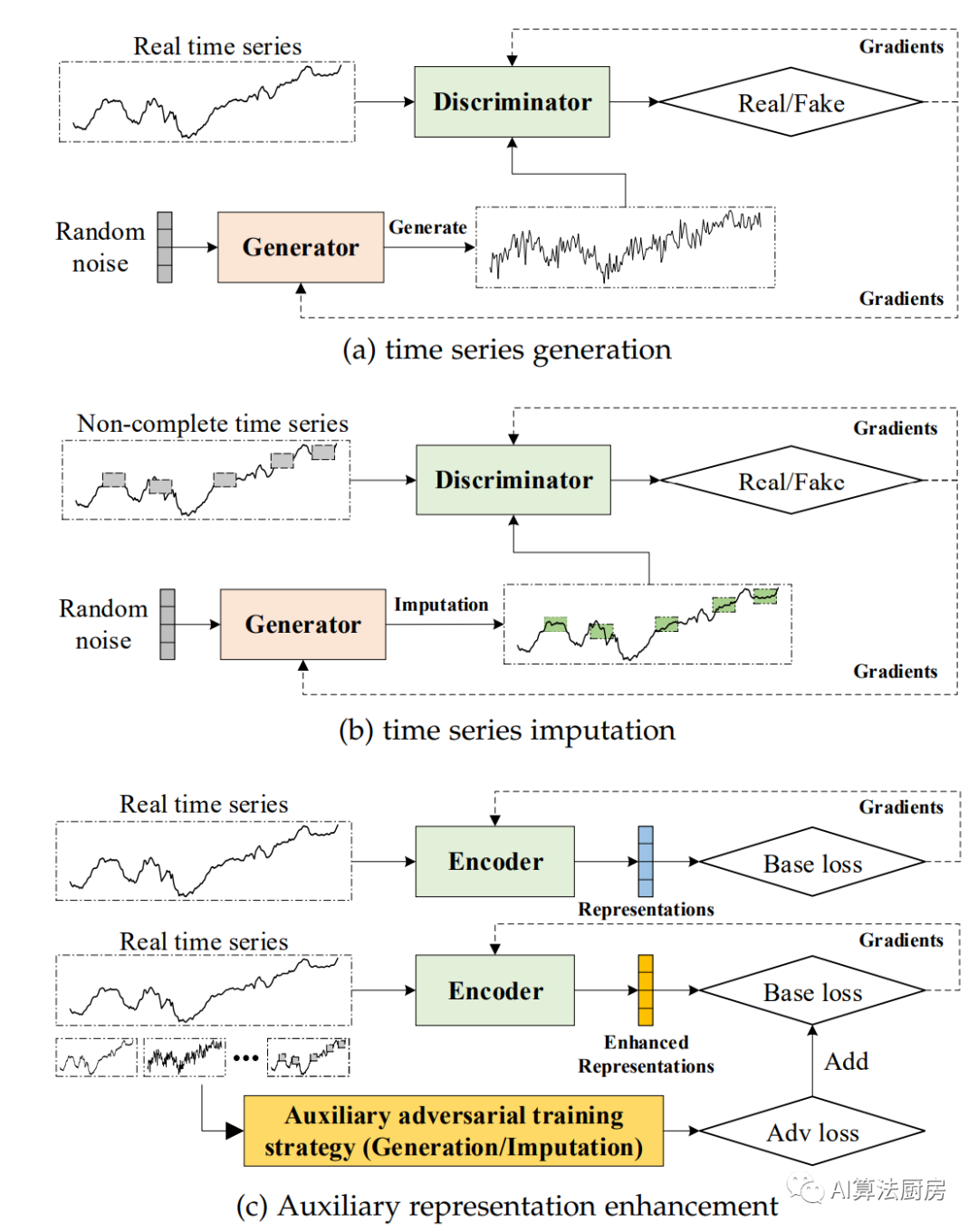
基于对抗的自监督表示学习方法使用生成对抗网络(GANs)来构建预文本任务。GAN包含一个生成器G和一个判别器D。生成器G负责生成与真实数据类似的合成数据,而判别器D负责判断生成的数据是真实数据还是合成数据。因此,生成器的目标是最大化判别器的决策失败率,判别器的目标是最小化其失败率。生成器G和判别器D是一种互相博弈的关系。
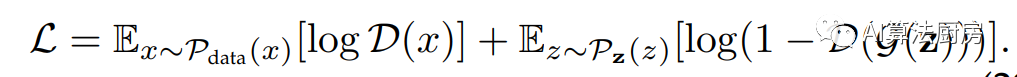
时间序列生成和插补
完全的时间序列生成是指在现有数据集中生成一个新的不存在的时间序列。新样本可以是单变量或多变量时间序列。C-RNN-GAN是使用GAN生成时间序列样本的早期方法。生成器是一个RNN,判别器是一个双向RNN。基于RNN的结构可以捕获多个时间步的动态依赖性,但忽略了数据的静态特征。TimeGAN是一个改进的时间序列生成框架,它将基本的GAN与自回归模型结合起来,允许保留序列的时间动态特征。TimeGAN还强调,静态特征和时间特征对于生成任务至关重要。
一些最近提出的方法考虑了更复杂的时间序列生成任务。例如,COSCI-GAN是一个考虑多变量时间序列中每个维度之间关系的时间序列生成框架。它包括Channel GANs和Central Discriminator。Channel GANs负责独立生成每个维度的数据,而Central Discriminator负责判断生成序列的不同维度之间的关系是否与原始序列相同。PSA-GAN是一个用于长时间序列生成的框架,并引入了自注意力机制。TTS-GAN探讨了具有不规则时空关系的时间序列数据的生成,该方法使用了Transformer来构建判别器和生成器,并将时间序列数据视为高度为一的图像数据。
不同于生成新的时间序列,时间序列插补的任务是给定一个不完整的时间序列样本(例如,某些时间步的数据缺失),需要基于上下文信息填补缺失的值。Luo等人将缺失值插补的问题视为数据生成任务,并使用生成对抗网络(GAN)来学习训练数据集的分布。为了更好地捕捉系列的动态特征,他们提出了GRUI模块。GRUI模块使用时间滞后矩阵来记录不完整时间序列数据有效值之间的时间滞后信息,这些信息遵循未知的非均匀分布,对于分析序列的动态特性非常有帮助。GRUI模块也进一步被用在E2GAN中。SSGAN是一个用于时间序列数据插补的半监督框架,它包括一个生成网络,一个判别网络和一个分类网络。不同于以前的框架,SSGAN的分类网络充分利用标签信息,这有助于模型实现更准确的插值。
辅助表示增强
除了生成和插补任务之外,基于对抗的表示学习策略可以作为额外的辅助学习模块添加到现有的学习框架中,我们将其称为基于对抗的辅助表示增强。辅助表示增强旨在通过添加基于对抗的学习策略,促使模型学习到更有信息含量的表示,以供下游任务使用。通常定义如下
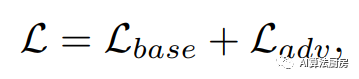
USAD是一个时间序列异常检测框架,其中包括两个BAE模型,这两个BAE分别被定义为AE1和AE2。USAD背后的核心思想是通过两个BAE之间的对抗性训练来放大重构误差。在USAD中,AE1被视为生成器,AE2被视为判别器。辅助目标是使用AE2区分AE1的重构数据和真实数据,并训练AE1欺骗AE2。
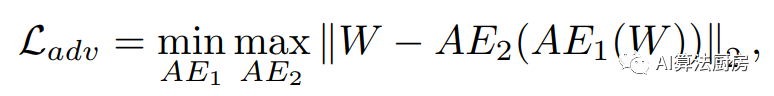
DUBCNs和CRLI分别用于系列检索和聚类任务。这两种方法都采用基于RNN的BAE作为模型,并将基于聚类的损失和基于对抗的损失添加到基本重构损失中。
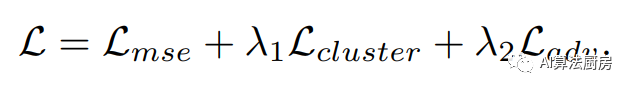
应用选型
自监督学习(SSL)在各种时间序列任务中都有广泛的应用,例如预测、分类、异常检测等。
异常检测
时间序列的异常检测问题主要是在一定的规范或常见信号的基础上,识别出异常的时间点或异常的时间序列。由于获取异常数据的标签具有挑战性,所以大多数时间序列异常检测方法都采用无监督学习框架。其中,基于自回归的预测和基于自编码器的重构是最常用的建模策略。例如,THOC 和GDN 使用基于自回归的预测的自监督学习框架,该框架假设异常的序列或时间点是不可预测的。而RANSynCoders,USAD,AnomalyTrans 和DAEMON 则使用基于自编码器的重构的自监督学习框架,该框架的原理是异常的数据是难以重构的。此外,VGCRN 和FuSAGNet 结合了两种框架,以实现更强健和准确的检测结果。在检测模型中引入基于对抗的自监督学习方法可以进一步扩大正常数据和异常数据之间的差异,如USAD 和 DAEMON。
预测
时间序列预测是通过使用统计和建模技术来分析时间序列数据,从而预测未来的时间窗口或时间点。基于自回归预测的预文字任务本质上就是一个时间序列预测任务。因此,已经提出了各种基于预测任务的模型,如Pyraformer,FilM,Quatformer,Informer,Triformer,Scaleformer,Crossformer,和Timesnet。我们发现,分解时间序列(如季节性和趋势),然后在分解的组件上进行学习和预测,可以提高最终预测的精度,如MICN 和 CoST。当时间序列中存在缺失值时,引入对抗性的自监督学习是可行的。例如,LGnet 引入了对抗训练以增强对全局时间分布的建模,这降低了缺失值对预测精度的影响。
分类和聚类
分类和聚类任务的目标是识别特定时间序列样本所属的真实类别。由于对比学习的核心是识别正样本和负样本,因此基于对比的自监督学习方法是这两个任务的最佳选择。具体来说,TSTCC 引入了时间对比和上下文对比,以获得更强健的表示。TS2Vec 和 MHCCL 在增强的视图上进行分层的对比学习策略,这使得获得更强健的表示成为可能。与异常检测和预测任务类似,基于对抗的自监督学习策略也可以引入到分类和聚类任务中。例如,DTCR 提出了一个假样本生成策略,以帮助编码器获得更有表现力的表示。
总结来说,基于生成的自监督学习更适合于异常检测和预测任务,而基于对比的自监督学习更适合于分类和聚类任务。基于对抗的自监督学习可以在各种任务中发挥作用,但在大多数情况下,它被用作一个额外的正则化项,以确保模型提取的特征更强健和信息丰富。
参考文献
Self-Supervised Learning for Time Series Analysis: Taxonomy, Progress, and Prospects
推荐阅读:
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步

发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书