Spark Streaming实时计算实例
一、实验内容
编写Spark Steaming应用程序,实现实时词频统计。
二、实验步骤
1.运行nc,模拟数据源。nc -lk 9999启动服务端且监听Socket服务。
命令:
nc -lk 9999
2.创建一个Maven工程,在pom.xml文件中添加Spark Streaming依赖。
依赖代码:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>hw</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<scala.version>2.12.15</scala.version>
<hadoop.version>2.7.4</hadoop.version>
<spark.version>3.1.2</spark.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>1.1.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${
scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.4</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.8.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>2.7.4</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testOutputDirectory>src/test/scala</testOutputDirectory>
</build>
</project>
依赖需要根据自己的idea版本需求和电脑安装的插件来配置,配置完成会自己启动下载,如果没有下载,只需要点击idea右侧测定maevn就会自动下载了。
3.编写程序,使用updateStateByKey()方法对nc客户端不断输入的内容进行实时的词频统计。
上机操作
一、nc客户端
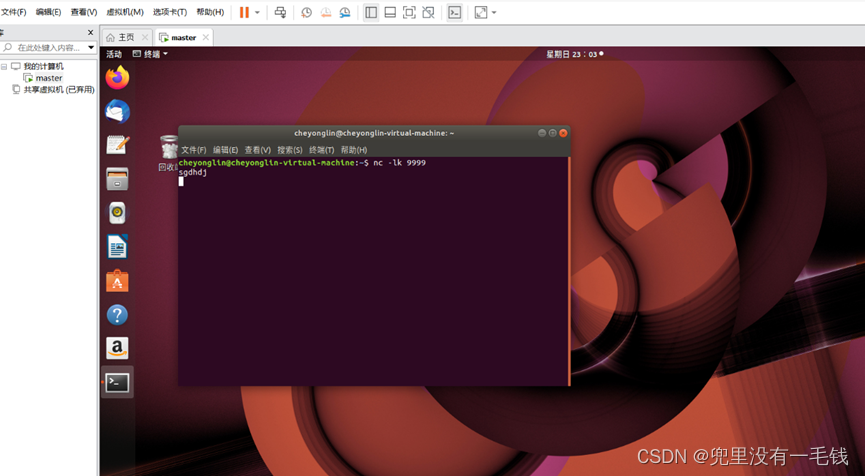
1. 在虚拟机linux中启动nc客户端的命令:
nc -lk 9999
输入:
sgdhdj
此处字母随便写。
2.nc客户端截图(要有数据)
二、实时词频统计客户端
- 程序(代码要有注释说明)
package cn.itcast.dstream
import org.apache.spark.streaming.dstream.{
DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{
Seconds, StreamingContext}
import org.apache.spark.{
SparkConf, SparkContext}
object UpdateSateByKeyTest {
//newValues 表示当前批次汇总成的(word,1)中相同单词的所有的1
def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
val newCount =runningCount.getOrElse(0)+newValues.sum
Some(newCount)
}
def main(args: Array[String]): Unit = {
//创建sparkConf参数
val sparkConf: SparkConf = new SparkConf().setAppName("UpdateSateByKeyTest").setMaster("local[2]")
//构建sparkContext对象,它是所有对象的源头
val sc: SparkContext = new SparkContext(sparkConf)
//设置日志的级别
sc.setLogLevel("WARN")
//构建StreamingContext对象,需要两个参数,每个批处理的时间间隔
val scc: StreamingContext = new StreamingContext(sc, Seconds(5))
//设置checkpoint路径,当前项目下有一个cy目录
scc.checkpoint("./cy")
//注册一个监听的IP地址和端口 用来收集数据
val lines: ReceiverInputDStream[String] = scc.socketTextStream("192.168.118.128", 9999)
//切分每一行记录
val word: DStream[String] = lines.flatMap(_.split(" "))
//每个单词记为1
val wordAndOne: DStream[(String, Int)] = word.map((_, 1))
//累计统计单词出现的次数
val result: DStream[(String, Int)] = wordAndOne.updateStateByKey(updateFunction)
result.print()
//打印输出结果
scc.start()
//开启流式计算
scc.awaitTermination()
//保持程序运行,除非被打断
}
}
2.客户端截图(要有实时计算的结果)
