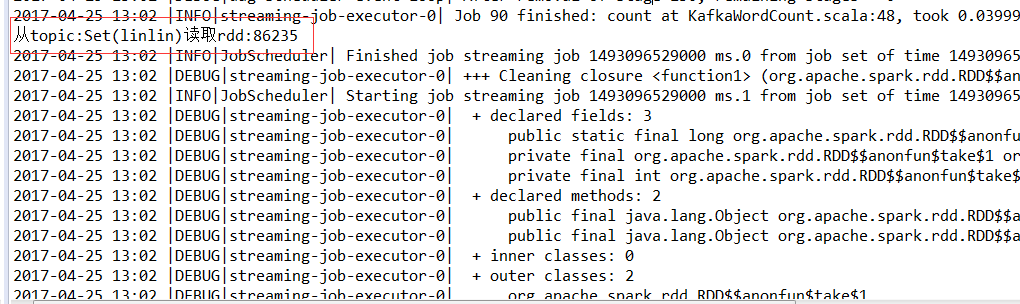
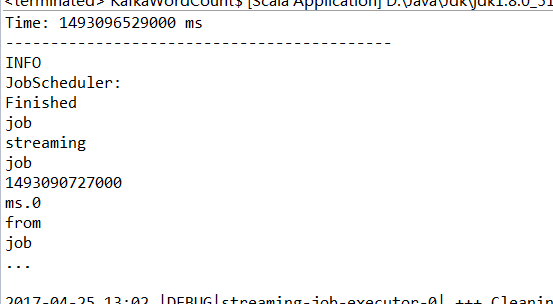
摘要:本文主要讲了一个Spark Streaming+Kafka整合的实例
本文工程下载:https://github.com/appleappleapple/BigDataLearning
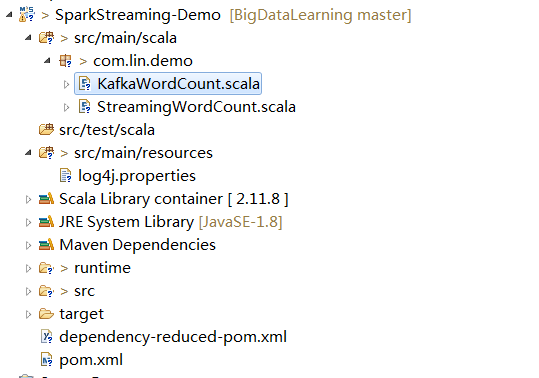
1、工程目录结构
2、引入依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.lin</groupId>
<artifactId>SparkStreaming-Demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>${project.artifactId}</name>
<description>My wonderfull scala app</description>
<inceptionYear>2015</inceptionYear>
<licenses>
<license>
<name>My License</name>
<url>http://....</url>
<distribution>repo</distribution>
</license>
</licenses>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.11.5</scala.version>
<scala.compat.version>2.11</scala.compat.version>
</properties>
<dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.8</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.11</artifactId>
<version>1.6.1</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<resources>
<resource>
<directory>src/main/resources</directory>
<targetPath>${basedir}/target/classes</targetPath>
<includes>
<include>**/*.properties</include>
<include>**/*.xml</include>
</includes>
<filtering>true</filtering>
</resource>
<resource>
<directory>src/main/resources</directory>
<targetPath>${basedir}/target/resources</targetPath>
<includes>
<include>**/*.properties</include>
<include>**/*.xml</include>
</includes>
<filtering>true</filtering>
</resource>
</resources>
<plugins>
<plugin>
<!-- see http://davidb.github.com/scala-maven-plugin -->
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<!-- <arg>-make:transitive</arg> -->
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
<configuration>
<useFile>false</useFile>
<disableXmlReport>true</disableXmlReport>
<includes>
<include>**/*Test.*</include>
<include>**/*Suite.*</include>
</includes>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.6</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
</plugins>
</build>
</project>
3、编写计算代码
package com.lin.demo
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Durations
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka.KafkaUtils
import kafka.serializer.StringDecoder
object KafkaWordCount {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("WordCount").setMaster("local[2]") //至少2个线程,一个DRecive接受监听端口数据,一个计算
val sc = new StreamingContext(sparkConf, Durations.seconds(3));
val kafkaParams = Map[String, String]("metadata.broker.list" -> "127.0.0.1:9092") // 然后创建一个set,里面放入你要读取的Topic,这个就是我们所说的,它给你做的很好,可以并行读取多个topic
var topics = Set[String]("linlin");
//kafka返回的数据时key/value形式,后面只要对value进行分割就ok了
val linerdd = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
sc, kafkaParams, topics)
val wordrdd = linerdd.flatMap { _._2.split(" ") }
wordrdd.foreachRDD(rdd => {
println("从topic:" + topics + "读取rdd:" + rdd.count())
})
wordrdd.print()
val resultrdd = wordrdd.map { x => (x, 1) }.reduceByKey { _ + _ }
resultrdd.print()
sc.start()
sc.awaitTermination()
sc.stop()
}
}4、启动zk和kafka
启动zk
启动kafka
5、发送消息
package com.lin.demo.producer;
import java.util.Properties;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
public class KafkaProducer {
private final Producer<String, String> producer;
public final static String TOPIC = "linlin";
private KafkaProducer() {
Properties props = new Properties();
// 此处配置的是kafka的端口
props.put("metadata.broker.list", "127.0.0.1:9092");
props.put("zk.connect", "127.0.0.1:2181");
// 配置value的序列化类
props.put("serializer.class", "kafka.serializer.StringEncoder");
// 配置key的序列化类
props.put("key.serializer.class", "kafka.serializer.StringEncoder");
props.put("request.required.acks", "-1");
producer = new Producer<String, String>(new ProducerConfig(props));
}
void produce() {
int messageNo = 1000;
final int COUNT = 10000;
while (true) {
String key = String.valueOf(messageNo);
String data = "INFO JobScheduler: Finished job streaming job 1493090727000 ms.0 from job set of time 1493090727000 ms" + key;
producer.send(new KeyedMessage<String, String>(TOPIC, key, data));
System.out.println(data);
messageNo++;
}
}
public static void main(String[] args) {
new KafkaProducer().produce();
}
}
6、验证
将3和6中的代码都跑起来