介绍:Spark是一个类似于MapReduce的分布式计算框架,其核心是弹性分布式数据集,提供了比MapReduce更丰富的模型,可以在快速在内存中对数据集进行多次迭代,以支持复杂的数据挖掘算法和图形计算算法。Spark Streaming是一种构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力。
文章目录
- 一、任务概述
- 二、window操作
- 三、虚拟机操作
- 效果展示
一、任务概述
windown与虚拟机连接实现实时计算词频统计
虚拟机---输入
window---计算
二、window操作
1.引入Streaming
直接创建maven工程,在pom文件下从apache直接添加依赖Streaming
示例代码如下
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.12</artifactId> <version>2.4.5</version> </dependency>
2,编写与虚拟机连接与实时计算的代码
详细代码如下,每一步都非常详细:(开发工具IDEA)也可用其他
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object jikou{
//newValues 表示当前批次汇总成的(word,1)中相同单词的所有1
//runningCount 表示历史的所有相同key的value总和
def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
val newCount =runningCount.getOrElse(0)+newValues.sum
Some(newCount)
}
def main(args: Array[String]): Unit = {
//1.创建SparkConf对象 设置appName和master地址 local[2] 表示本地采用2个线程运行任务
val sparkConf: SparkConf = new SparkConf().setAppName("WordCount").setMaster("local[2]")
//2.创建SparkContext对象,它是所有任务计算的源头,它会创建DAGScheduler和TaskScheduler
val sc: SparkContext = new SparkContext(sparkConf)
//3.设置日志级别helloo'
sc.setLogLevel("WARN")
//4.创建StreamingContext,需要2个参数,一个是SparkContext,一个是批处理的时间间隔
val ssc: StreamingContext = new StreamingContext(sc,Seconds(5))
//5.配置检查点目录,使用updateStateByKey方法必须配置检查点目录
ssc.checkpoint("./")
//6.对接socket数据创建DStream对象,需要socket服务的地址、端口号及存储级别(默认的)
val dstream: ReceiverInputDStream[String] = ssc.socketTextStream("自己虚拟机的IP地址",8888)
//7.按空格进行切分每一行,并将切分的单词出现次数记录为1
val wordAndOne: DStream[(String, Int)] = dstream.flatMap(_.split(" ")).map(word =>(word,1))
//8.调用updateStateByKey操作,统计单词在全局中出现的次数
var result: DStream[(String, Int)] = wordAndOne.updateStateByKey(updateFunction)
//9.打印输出结果
result.print()
//10.开启流式计算
ssc.start()
//11.让程序一直运行,除非人为干预停止
ssc.awaitTermination()
}
}
三.虚拟机操作
扫描二维码关注公众号,回复:
16948462 查看本文章

首先需要下载nc
命令:yum install nc
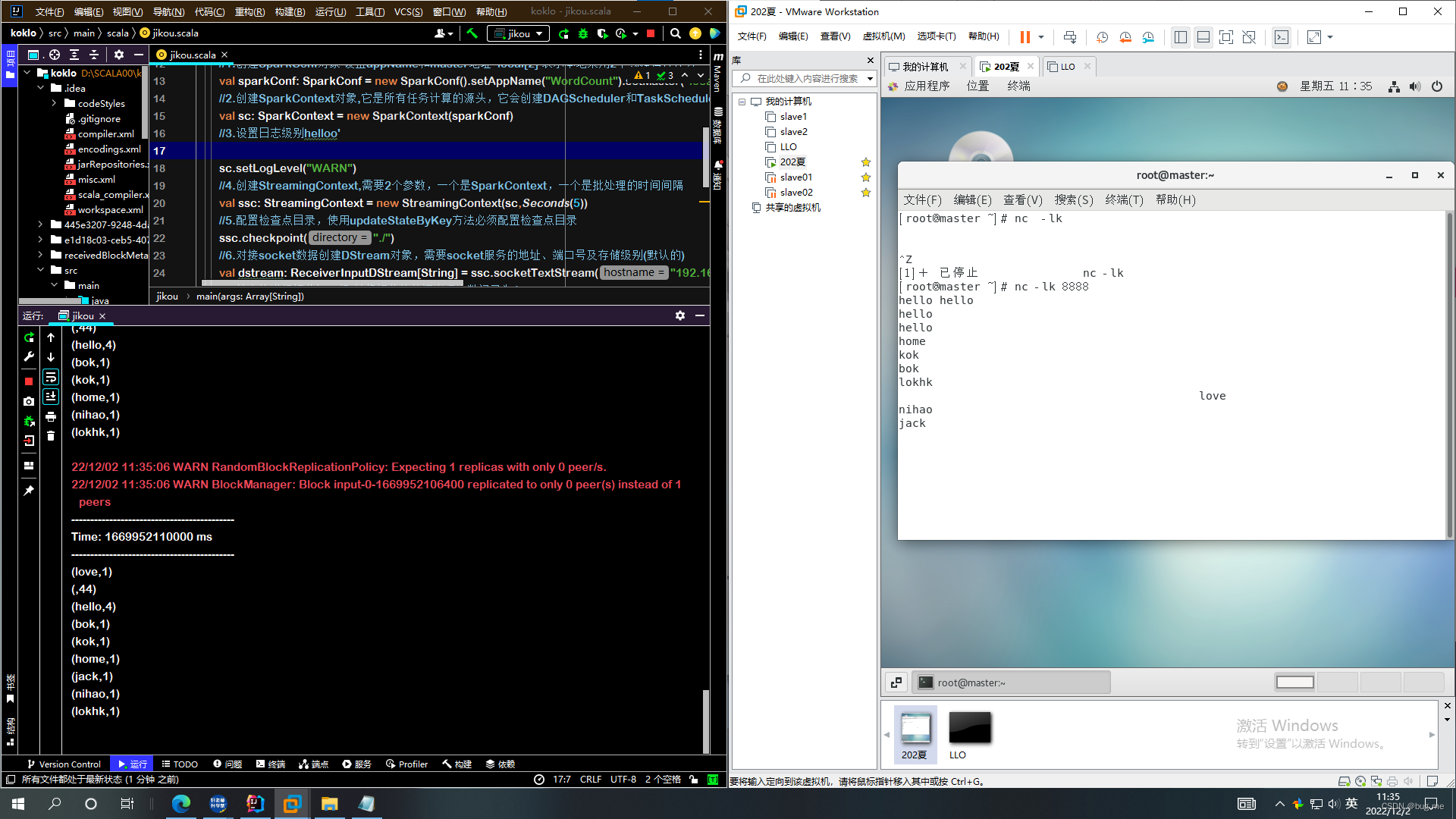
打开虚拟机终端直接输入: nc -lk 8888
然后输入你要统计的单词就可以啦!
注意:window上IP地址一定要和虚拟机上一致
效果图片展示!