说到爬虫,第一时间可能就会想到网易云音乐的评论。网易云音乐评论里藏了许多宝藏,那么让我们一起学习如何用 python 挖宝藏吧!

既然是宝藏,肯定是用要用钥匙加密的。打开 Chrome 分析 Headers 如下。
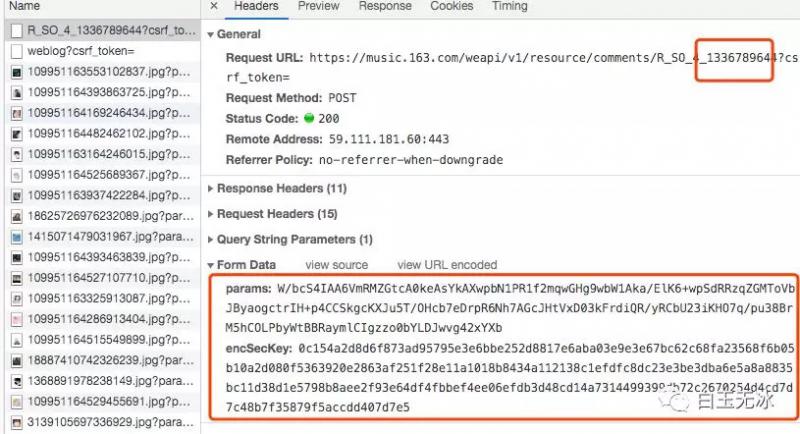
这参数看起来挺复杂的,我们就不用 requests 去调用这个链接了。
这次使用的是 selenium ! 一个浏览器自动化测试框架!通过它可以模拟手动操作浏览器!
为此我们要准备好驱动器 chromedriver 和 chrome 浏览器。

chromedriver 可以在淘宝镜像中下载,选择与 chrome 浏览器对应的版本进行下载。下载地址如下。
http://npm.taobao.org/mirrors/chromedriver
整个项目使用了 python3 与一些第三方库。参考如下。
from selenium import webdriver
import jieba
from wordcloud import WordCloud
from PIL import Image
import numpy as np然后配置 config.json

{
"id":"1336789644",
"page": 200,
"useCache": true,
"font_path": "SimHei.ttf",
"mask": "mask.png",
"chromedriver": "chromedriver"
}运行 sound.py 就会生成词云图。

以及所有的评论数据

看了使用方法,接下来进入分析环节!

找到网易云音乐的地址并发现规律,并使用 webdriver 打开!

driver = webdriver.Chrome(CONFIG['chromedriver'])
driver.get(f'https://music.163.com/#/song?id={SOUND_ID}')接着让 driver 跳入到评论框的 frame 里。
driver.switch_to.frame('g_iframe')为何这么做?因为在 frame 结构里无法用 xpath 解析到。而评论数据正好在这个 iframe 中。
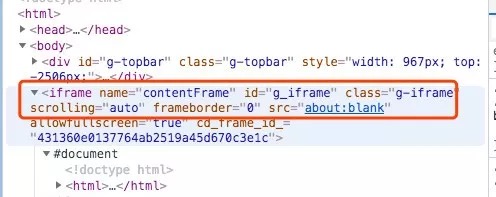
选中其中一个评论,分析其格式结构,可以看到都是在同一个 class 名内。

编写对应的 xpath ,得到所有的评论列表。
element_list = driver.find_elements_by_xpath('//div[@class="cnt f-brk"]')选择下一页按钮,分析其格式结构,可以看到 class 名是以一个前缀为开头的。

编写对应的 xpath ,得到下一页按钮,并在需要的时候模拟点击。
next_button = driver.find_element_by_xpath('//a[starts-with(@class,"zbtn znxt js-n-")]')
driver.execute_script('arguments[0].click();', next_button)数据分析结束后,该生成结果喽。

将评论列表保存为 json。
with open(filePath,'w') as f:
json.dump(comments_list,f, ensure_ascii=False, indent=4)使用 jieba 分词和 wordcloud 生成词云图。
# 词云处理
image_mask = np.array(Image.open(CONFIG['mask']))
wordlist = jieba.cut(';'.join(comments_list))
wordcloud = WordCloud(font_path=CONFIG['font_path'], background_color='white', mask=image_mask, scale=1.5).generate(' '.join(wordlist))
# 保存图
wordcloud.to_file(f'./result/{SOUND_ID}-{PAGES}.png')以上就是使用 selenium 爬取网易云音乐评论的整个步骤喽!
本文仅供个人学习交流使用,请勿用于其他用途!