Python爬取网易云音乐搜索并下载歌曲!
1.准备工作
我在网易云音乐试了一下,发现是它是一个动态网页,里面的内容都是JS生成的,所以不太好爬取。这时候就要有第三方网站“帮”我们爬取了。
我找了个第三方软件,可以用它来爬出歌曲ID,我们在爬取它的源代码,把ID取出来(好像有点绕口)
2.“实地”观察
我们进入到这个网站,发现这个网站一个有5个下载源可以搜索:
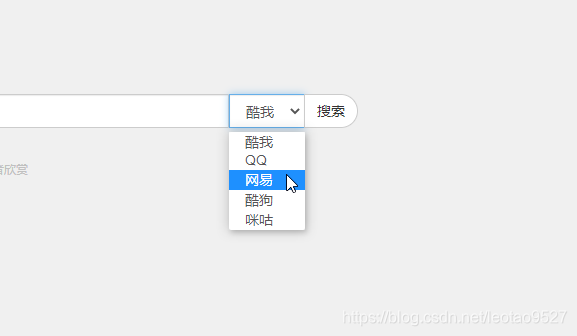
今天我们的目标是下载网易云音乐的歌曲,有兴趣的小伙伴可以试着爬取其他网站的歌曲,原理是一样的。我们随便搜索一个歌曲,查看网址。
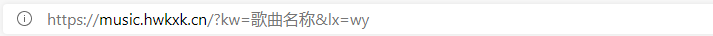
我们发现网址"kw="后面代表是歌曲的名称,而"lx="后面代表的是下载源。
我们再来看看源代码:
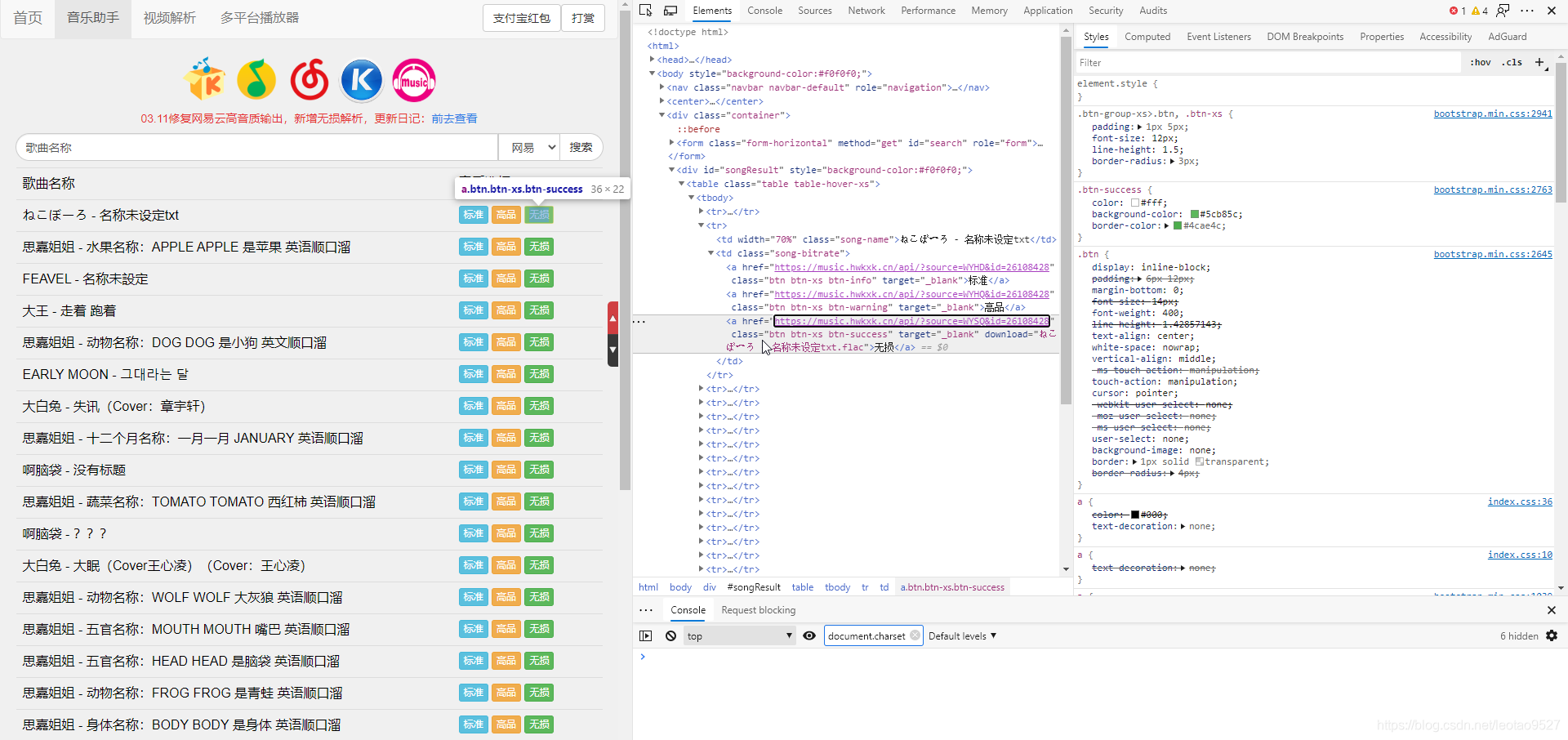
我们看到,一个a标签里面正有我们想要的东西:下载链接和歌曲名称。

有了下载链接和歌曲名称就好办了,接下来是码代码环节!
3.开始码代码!
我这里做了一个用户界面和UI,还有一个新的下载方式:链接下载。想看链接下载的小伙伴可以跳过本章,看第4章节:搜索并下载。
链接下载
首先,我们得知道一个网址:http://music.163.com/song/media/outer/url?id=?.mp3
这是什么呢?这是一个下载链接,在"id="处填上歌曲的ID就可以下载了。

我们随便打开一个音乐,发现网址上正好有"id=???"这样的格式,我们只要用正则表达式来提取ID,再在把ID填到上面的网址中就可以了,代码:
import re
import urllib.request
import tkinter.messagebox as box
# 设置下载函数
def urldownload():
url = lefturl.get() # 这里是我UI的输入框,不想用UI的可以直接input
try:
# 解析歌曲id
urlid = re.findall('id=(.*)', url)[0]
# 获取下载网页
durl = 'http://music.163.com/song/media/outer/url?id=%s.mp3' % urlid
# 下载歌曲
urllib.request.urlretrieve(durl, '绝对路径\名称.mp3')
# 提示下载完毕
box.showinfo(title='提示', message='音乐已下载完毕!\n已保存至download文件夹!')
except:
box.showerror(title='错误', message='下载链接错误!')
4.搜索并下载
想要得到下载链接和名称,我们首先得得到网页的源代码:
# 搜索函数
def searchdownload(name):
# 从网站的Requests Header中获取
url = 'https://music.hwkxk.cn/?kw=%s&lx=wy' % name
html = requests.get(url=url).text
print(html)
可是运行完后,输出的是乱码,这是怎么回事?
这时候,我们可以先把网页内容转成单字节编码,再转成UTF-8,修改如下:
import requests
# 搜索函数
def searchdownload(name):
# 从网站的Requests Header中获取
url = 'https://music.hwkxk.cn/?kw=%s&lx=wy' % name
html = requests.get(url=url).text
html = html.encode('ISO-8859-1')
html = html.decode('UTF-8')
print(html)
这时候,就没有乱码了。
接下来,就来爬取歌曲名称和下载链接:

我们看到,这个歌曲的a标签的class名是“btn btn-xs btn-success”,但是这只是一个歌曲的class,我们要找到"所有歌曲的class"。
我们看到右边的"styles",发现这个class才是"所有a标签的class"。
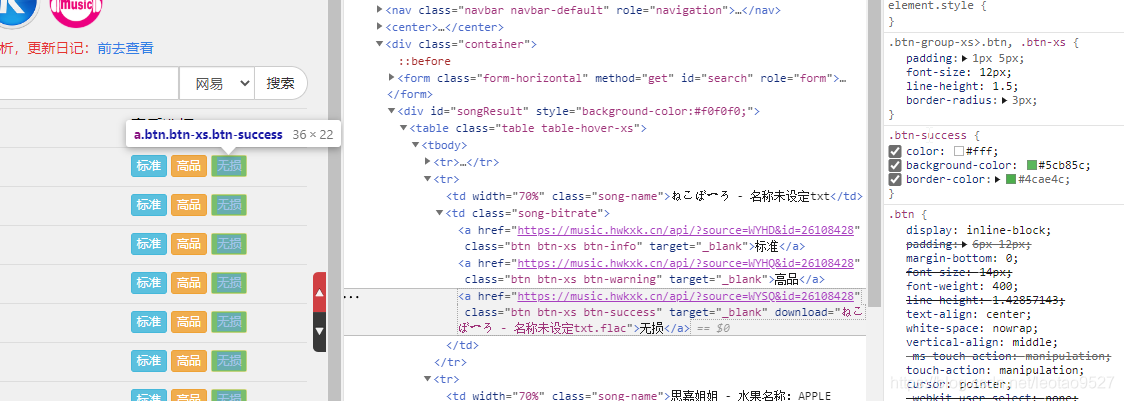
现在来码代码:
import bs4
import requests
# 搜索函数
def searchdownload(name):
# 从网站的Requests Header中获取
url = 'https://music.hwkxk.cn/?kw=%s&lx=wy' % name
html = requests.get(url=url).text
html = html.encode('ISO-8859-1')
html = html.decode('UTF-8')
# 解析网页
soup = bs4.BeautifulSoup(html, "lxml")
# 查找目标
link_0 = soup.select('.btn-success')
print(link_0)
运行函数后,Python返回了一个列表:
[<a class="btn btn-xs btn-success" download="久石譲 - Summer.flac" href="https://music.hwkxk.cn/api/?source=WYSQ&id=1417064063" target="_blank">无损</a>, <a class="btn btn-xs btn-success" download="久石譲 - Summer.flac" href="https://music.hwkxk.cn/api/?source=WYSQ&id=443242" target="_blank">无损</a>, <a class="btn btn-xs btn-success" download="keshi - summer.flac" href="https://music.hwkxk.cn/api/?source=WYSQ&id=1378192821" target="_blank">无损</a>, <a class="btn btn-xs btn-success" download="Calvin Harris - Summer.flac" href="https://music.hwkxk.cn/api/?source=WYSQ&id=28306554" target="_blank">无损</a>, <a class="btn btn-xs btn-success" download="Mazza - Summer Klaas Remix.flac" href="https://music.hwkxk.cn/api/?source=WYSQ&id=28729445" target="_blank">无损</a>, <a class="btn btn-xs btn-success" download="久石譲 - Summer.flac" href="https://music.hwkxk.cn/api/?source=WYSQ&id=444292" target="_blank">无损</a>, <a class="btn btn-xs btn-success" download="keshi - summer.flac" href="https://music.hwkxk.cn/api/?source=WYSQ&id=1361455890" target="_blank">无损</a>, <a class="btn btn-xs btn-success" download="徐梦圆 - summer.flac" href="https://music.hwkxk.cn/api/?source=WYSQ&id=34779102" target="_blank">无损</a>, <a class="btn btn-xs btn-success" download="LJY - Summer (夏).flac" href="https://music.hwkxk.cn/api/?source=WYSQ&id=485263993" target="_blank">无损</a>, <a class="btn btn-xs btn-success" download="Calvin Harris - Summer.flac" href="https://music.hwkxk.cn/api/?source=WYSQ&id=29460066" target="_blank">无损</a>, <a class="btn btn-xs btn-success" download="戈冧 - Summer.flac" href="https://music.hwkxk.cn/api/?source=WYSQ&id=1377103256" target="_blank">无损</a>, <a class="btn btn-xs btn-success" download="David Garrett - Summer.flac" href="https://music.hwkxk.cn/api/?source=WYSQ&id=17241229" target="_blank">无损</a>, <a class="btn btn-xs btn-success" download="cozy kev - summer.flac" href="https://music.hwkxk.cn/api/?source=WYSQ&id=1410153419" target="_blank">无损</a>, <a class="btn btn-xs btn-success" download="KMS - summer.flac" href="https://music.hwkxk.cn/api/?source=WYSQ&id=1418582038" target="_blank">无损</a>, <a class="btn btn-xs btn-success" download="Yogee New Waves - Summer.flac" href="https://music.hwkxk.cn/api/?source=WYSQ&id=29979351" target="_blank">无损</a>, <a class="btn btn-xs btn-success" download="Marshmello - SuMmeR.flac" href="https://music.hwkxk.cn/api/?source=WYSQ&id=39324020" target="_blank">无损</a>, <a class="btn btn-xs btn-success" download="Kesha - Summer.flac" href="https://music.hwkxk.cn/api/?source=WYSQ&id=1419676441" target="_blank">无损</a>, <a class="btn btn-xs btn-success" download="Calvin Harris - Summer R3hab Ummet Ozcan Remix.flac" href="https://music.hwkxk.cn/api/?source=WYSQ&id=28696074" target="_blank">无损</a>, <a class="btn btn-xs btn-success" download="BROCKHAMPTON - SUMMER.flac" href="https://music.hwkxk.cn/api/?source=WYSQ&id=502242134" target="_blank">无损</a>, <a class="btn btn-xs btn-success" download="Dan Martinez - 夏日狂欢.flac" href="https://music.hwkxk.cn/api/?source=WYSQ&id=1320098269" target="_blank">无损</a>]
这正是我们想要的,我们现在打印列表的第一个:
print(link_0[0])
输出:
<a class="btn btn-xs btn-success" download="久石譲 - Summer.flac" href="https://music.hwkxk.cn/api/?source=WYSQ&id=1417064063" target="_blank">无损</a>
再仔细观察,发现"download"是歌曲的名称,"href"是歌曲下载的链接。只要在"link_0[0]“的后面加上”.get(‘href’)[0]"就可以了,名称也是同理,要是没有就返回None。
# 查找目标
try:
link_0 = soup.select('.btn-success')[0].get('href')[0]
name_0 = soup.select('.btn-success')[0].get('download')
except:
link_0 = None
name_0 = None
try:
link_1 = soup.select('.btn-success')[1].get('href')[0]
name_1 = soup.select('.btn-success')[1].get('download')
except:
link_1 = None
name_1 = None
try:
link_2 = soup.select('.btn-success')[2].get('href')[0]
name_2 = soup.select('.btn-success')[2].get('download')
except:
link_2 = None
name_2 = None
try:
link_3 = soup.select('.btn-success')[3].get('href')[0]
name_3 = soup.select('.btn-success')[3].get('download')
except:
link_3 = None
name_3 = None
try:
link_4 = soup.select('.btn-success')[4].get('href')[0]
name_4 = soup.select('.btn-success')[4].get('download')
except:
link_4 = None
name_4 = None
最后再存到字典里,返回参数:
link_data = {
"0_0":link_0,
"0_1":name_0,
"1_0":link_1,
"1_1":name_1,
"2_0":link_2,
"2_1":name_2,
"3_0":link_3,
"3_1":name_3,
"4_0":link_4,
"4_1":name_4
}
return link_data
有了下载链接和名称,下载大家应该都会了吧,只要用urllib.request.urlretrieve()就可以了。
结束语
学习了今天的知识,你应该有了不少收获吧!我相信,你在学习Python的路上有更近了一步!
by taoxichen
只有在开水里,茶叶才能展开生命浓郁的香气。
