简介
上一节中,介绍了图像分类任务中的两个关键部分:
1. 基于参数的评分函数。该函数将原始图像像素映射为分类评分值(例如:一个线性函数)。
2. 损失函数。该函数能够根据分类评分和训练集图像数据实际分类的一致性,衡量某个具体参数集的质量好坏。损失函数有多种版本和不同的实现方式(例如:Softmax或SVM)。
上节中,线性函数的形式是,而SVM实现的公式是:
对于图像数据,如果基于参数集
做出的分类预测与真实情况比较一致,那么计算出来的损失值
就很低。现在介绍第三个,也是最后一个关键部分:最优化Optimization。最优化是寻找能使得损失函数值最小化的参数
的过程。
铺垫:一旦理解了这三个部分是如何相互运作的,我们将会回到第一个部分(基于参数的函数映射),然后将其拓展为一个远比线性函数复杂的函数:首先是神经网络,然后是卷积神经网络。而损失函数和最优化过程这两个部分将会保持相对稳定。
-----------------------------------------------------------------------
损失函数可视化
本课中的损失函数一般都是定义在高维度的空间中(比如,在CIFAR-10中一个线性分类器的权重矩阵大小是[10x3073],就有30730个参数),这样要将其可视化就很困难。
然而办法还是有的,在1个维度或者2个维度的方向上对高维空间进行切片,就能得到一些直观感受。例如,随机生成一个权重矩阵,该矩阵就与高维空间中的一个点对应。然后沿着某个维度方向前进的同时记录损失函数值的变化。换句话说,就是生成一个随机的方向
并且沿着此方向计算损失值,计算方法是根据不同的
值来计算
。这个过程将生成一个图表,其x轴是
值,y轴是损失函数值。同样的方法还可以用在两个维度上,通过改变
来计算损失值
,从而给出二维的图像。在图像中,
可以分别用x和y轴表示,而损失函数的值可以用颜色变化表示:下图是一个无正则化的多类SVM的损失函数的图示。左边和中间只有一个样本数据,右边是CIFAR-10中的100个数据。
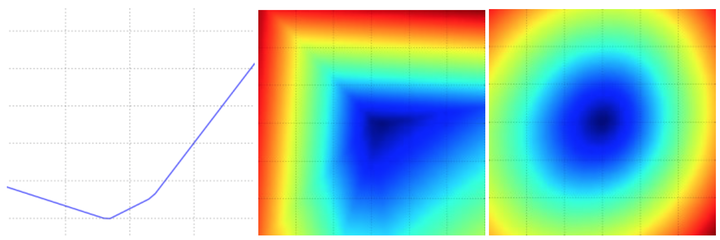
左:a值变化在某个维度方向上对应的的损失值变化。中和右:两个维度方向上的损失值切片图,蓝色部分是低损失值区域,红色部分是高损失值区域。注意损失函数的分段线性结构。多个样本的损失值是总体的平均值,所以右边的碗状结构是很多的分段线性结构的平均(比如中间这个就是其中之一)

我们可以通过数学公式来解释损失函数的分段线性结构。对于一个单独的数据,有损失函数的计算公式如下:
通过公式可见,每个样本的数据损失值是以为参数的线性函数的总和(零阈值来源于
函数)。
的每一行(即
),有时候它前面是一个正号(比如当它对应错误分类的时候),有时候它前面是一个负号(比如当它是是正确分类的时候)。为进一步阐明,假设有一个简单的数据集,其中包含有3个只有1个维度的点,数据集数据点有3个类别。那么完整的无正则化SVM的损失值计算如下:
因为这些例子都是一维的,所以数据和权重
都是数字。观察
,可以看到上面的式子中一些项是
的线性函数,且每一项都会与0比较,取两者的最大值。可作图如下:
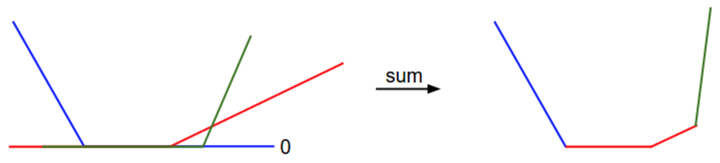 从一个维度方向上对数据损失值的展示。x轴方向就是一个权重,y轴就是损失值。数据损失是多个部分组合而成。其中每个部分要么是某个权重的独立部分,要么是该权重的线性函数与0阈值的比较。完整的SVM数据损失就是这个形状的30730维版本。
从一个维度方向上对数据损失值的展示。x轴方向就是一个权重,y轴就是损失值。数据损失是多个部分组合而成。其中每个部分要么是某个权重的独立部分,要么是该权重的线性函数与0阈值的比较。完整的SVM数据损失就是这个形状的30730维版本。
-----------------------------------------------------------------------
最优化 Optimization
重申一下:损失函数可以量化某个具体权重集W的质量。而最优化的目标就是找到能够最小化损失函数值的W 。我们现在就朝着这个目标前进,实现一个能够最优化损失函数的方法。
策略#1:一个差劲的初始方案:随机搜索
既然确认参数集W的好坏蛮简单的,那第一个想到的(差劲)方法,就是可以随机尝试很多不同的权重,然后看其中哪个最好。
我们尝试了若干随机生成的权重矩阵W,其中某些的损失值较小,而另一些的损失值大些。我们可以把这次随机搜索中找到的最好的权重W取出,然后去跑测试集,在验证集上表现最好的权重W跑测试集的准确率是15.5%,而完全随机猜的准确率是10%,如此看来,这个准确率对于这样一个不经过大脑的策略来说,还算不错嘛!
核心思路:迭代优化。当然,我们肯定能做得更好些。核心思路是:虽然找到最优的权重W非常困难,甚至是不可能的(尤其当W中存的是整个神经网络的权重的时候),但如果问题转化为:对一个权重矩阵集W取优,使其损失值稍微减少。那么问题的难度就大大降低了。换句话说,我们的方法从一个随机的W开始,然后对其迭代取优,每次都让它的损失值变得更小一点。
我们的策略是从随机权重开始,然后迭代取优,从而获得更低的损失值。
蒙眼徒步者的比喻:一个助于理解的比喻是把你自己想象成一个蒙着眼睛的徒步者,正走在山地地形上,目标是要慢慢走到山底。在CIFAR-10的例子中,这山是30730维的(因为W是3073x10)。我们在山上踩的每一点都对应一个的损失值,该损失值可以看做该点的海拔高度。
策略#2:随机本地搜索
第一个策略可以看做是每走一步都尝试几个随机方向,如果某个方向是向山下的,就向该方向走一步。这次我们从一个随机开始,然后生成一个随机的扰动
,只有当
的损失值变低,我们才会更新。
策略#3:跟随梯度
前两个策略中,我们是尝试在权重空间中找到一个方向,沿着该方向能降低损失函数的损失值。其实不需要随机寻找方向,因为可以直接计算出最好的方向,这就是从数学上计算出最陡峭的方向。这个方向就是损失函数的梯度(gradient)。在蒙眼徒步者的比喻中,这个方法就好比是感受我们脚下山体的倾斜程度,然后向着最陡峭的下降方向下山。
在一维函数中,斜率是函数在某一点的瞬时变化率。梯度是函数的斜率的一般化表达,它不是一个值,而是一个向量。在输入空间中,梯度是各个维度的斜率组成的向量(或者称为导数derivatives)。对一维函数的求导公式如下:
当函数有多个参数的时候,我们称导数为偏导数。而梯度就是在每个维度上偏导数所形成的向量。
-----------------------------------------------------------------------------------------------------------------
以上内容转载整理来自知乎专栏点击打开链接,侵删侵删。