
背景
围棋和强化学习组合一直是比较惊艳。之前是有MCTS发挥了巨大的威力。
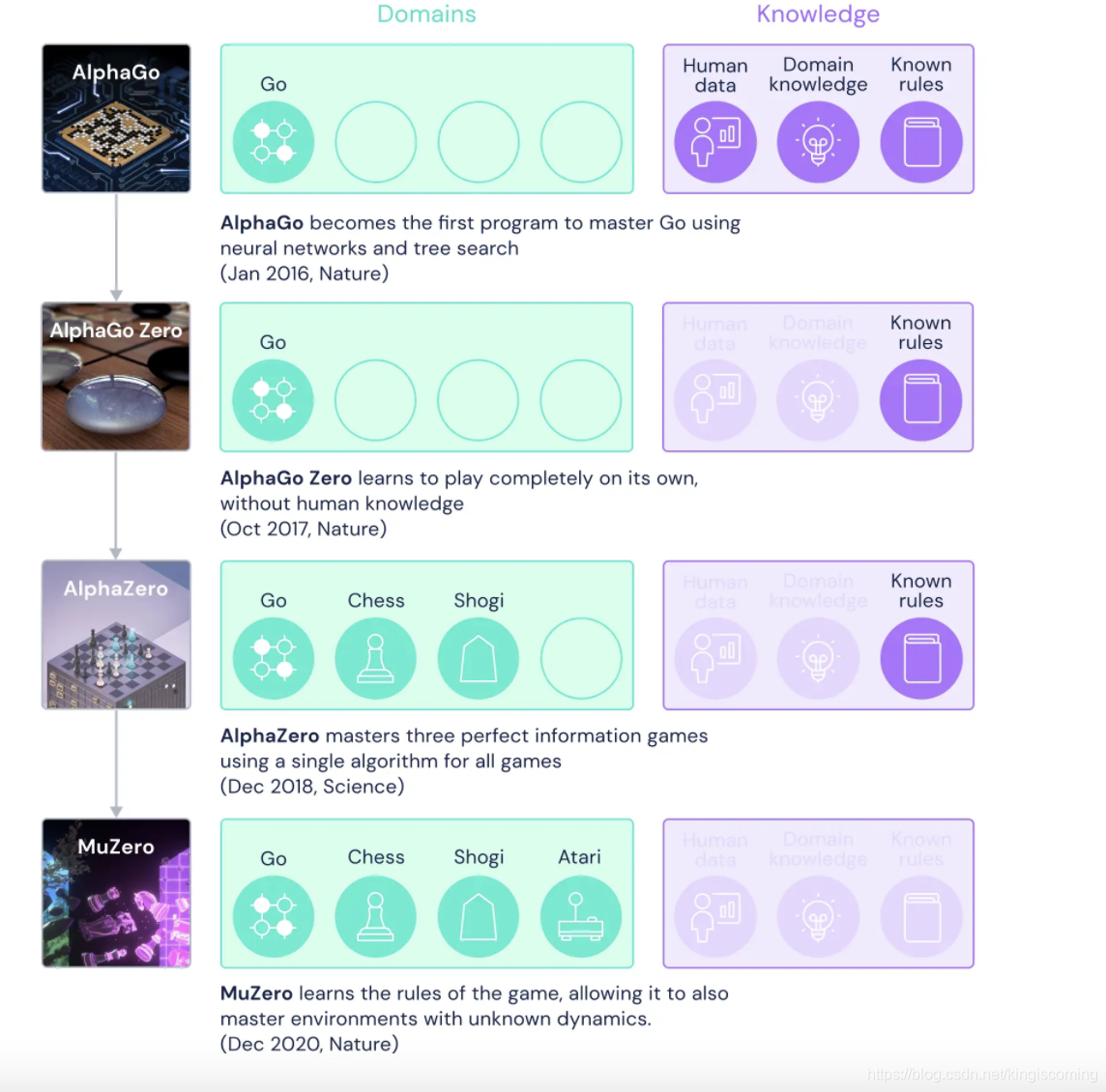
DeepMind一篇关于MuZero的论文“Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model”在Nature发表。与AlphaZero相比,MuZero多了玩Atari的功能,并且不需要知道规则(对交互进行了抽象)这一突破进展引起科研人员的广泛关注。
概览
MuZero迈出了最终的下一步。MuZero不仅否认自己的人类策略可以学习。甚至没有显示游戏规则。
换句话说,对于国际象棋,AlphaZero面临以下挑战:
了解如何独自玩游戏-这是规则手册,解释了每个棋子的移动方式以及哪些移动是合法的。此外,它还告诉您如何判断一个位置是否是同伴(或平局)。
另一方面,MuZero面临以下挑战:
了解如何独自玩游戏-我将告诉您当前位置上哪些动作合法,以及哪一方获胜(或平局),但我不会告诉您游戏的总体规则。
因此,除了制定制胜战略之外,MuZero还必须开发自己的动态环境模型,以便能够了解其选择的含义并制定未来的计划。
想象一下在一个从未被告知规则的游戏中试图变得比世界冠军更好。MuZero正是实现了这一目标。
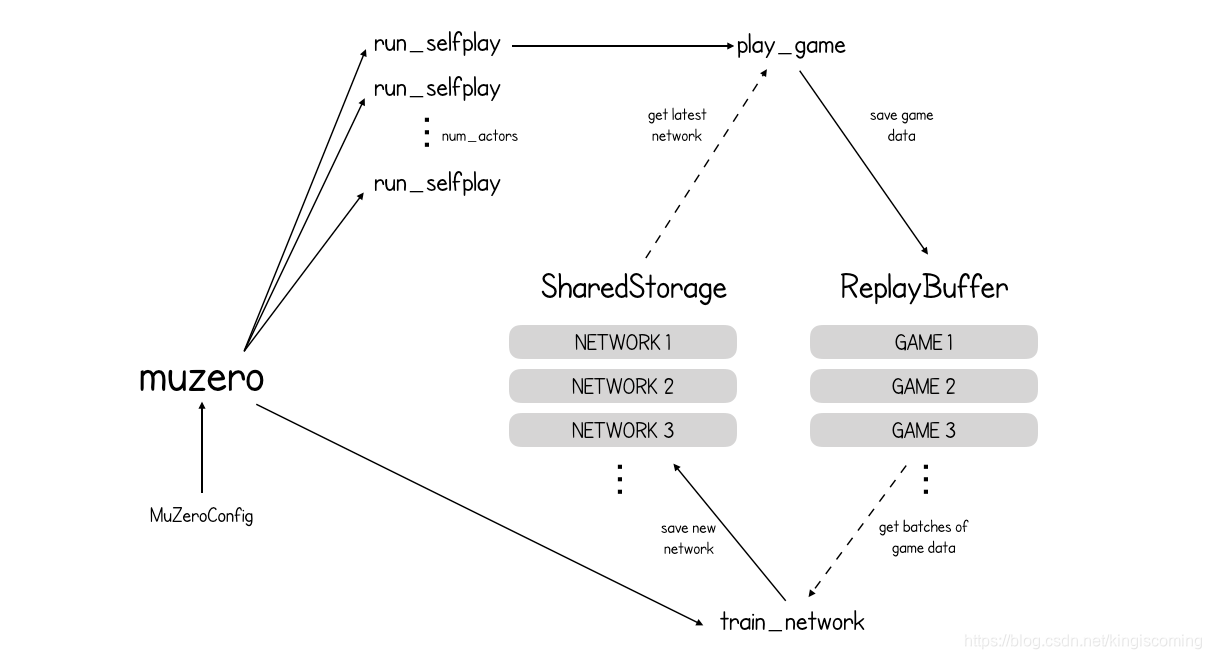
def muzero(config: MuZeroConfig):
storage = SharedStorage()
replay_buffer = ReplayBuffer(config)
for _ in range(config.num_actors):
launch_job(run_selfplay, config, storage, replay_buffer)
train_network(config, storage, replay_buffer)
return storage.latest_network()
Shared Storage
class SharedStorage(object):
def __init__(self):
self._networks = {}
def latest_network(self) -> Network:
if self._networks:
return self._networks[max(self._networks.keys())]
else:
# policy -> uniform, value -> 0, reward -> 0
return make_uniform_network()
def save_network(self, step: int, network: Network):
self._networks[step] = network
ReplayBuffer
class ReplayBuffer(object):
def __init__(self, config: MuZeroConfig):
self.window_size = config.window_size
self.batch_size = config.batch_size
self.buffer = []
def save_game(self, game):
if len(self.buffer) > self.window_size:
self.buffer.pop(0)
self.buffer.append(game)
...
window_size为最大游戏储存数量。
Self-play (run_selfplay)
# Each self-play job is independent of all others; it takes the latest network
# snapshot, produces a game and makes it available to the training job by
# writing it to a shared replay buffer.
def run_selfplay(config: MuZeroConfig, storage: SharedStorage,
replay_buffer: ReplayBuffer):
while True:
network = storage.latest_network()
game = play_game(config, network)
replay_buffer.save_game(game)
因此,总而言之,MuZero正在与自己对战数千场比赛,将这些比赛保存到缓冲区中,然后根据这些比赛中的数据进行训练。到目前为止,这与AlphaZero没什么不同。
现在到了最主要的区别之一。AlphaZero和MuZero之间的主要区别为什么MuZero具有三个神经网络,而AlphaZero只有一个神经网络?
MuZero和AlphaZero主要差异
AlphaZero和MuZero都利用称为蒙特卡洛树搜索(MCTS)的技术来选择下一个最佳动作。
这个想法是,为了选择下一个最佳动作,从当前位置“播出”可能的未来情景,使用神经网络评估其价值并选择使未来预期价值最大化的行动是有意义的。这似乎是人类下棋时脑子里正在做的事情,而AI也旨在利用这种技术。
但是,MuZero有一个问题。由于它不了解游戏规则,因此不知道给定的动作将如何影响游戏状态,因此无法想象MCTS中的未来情况。它甚至不知道如何从给定位置算出哪些举动是合法的,或者一方是否获胜。
MuZero论文的惊人发展表明,这无关紧要。MuZero通过在自己的想象中创建动态环境模型并在此模型中进行优化来学习如何玩游戏。
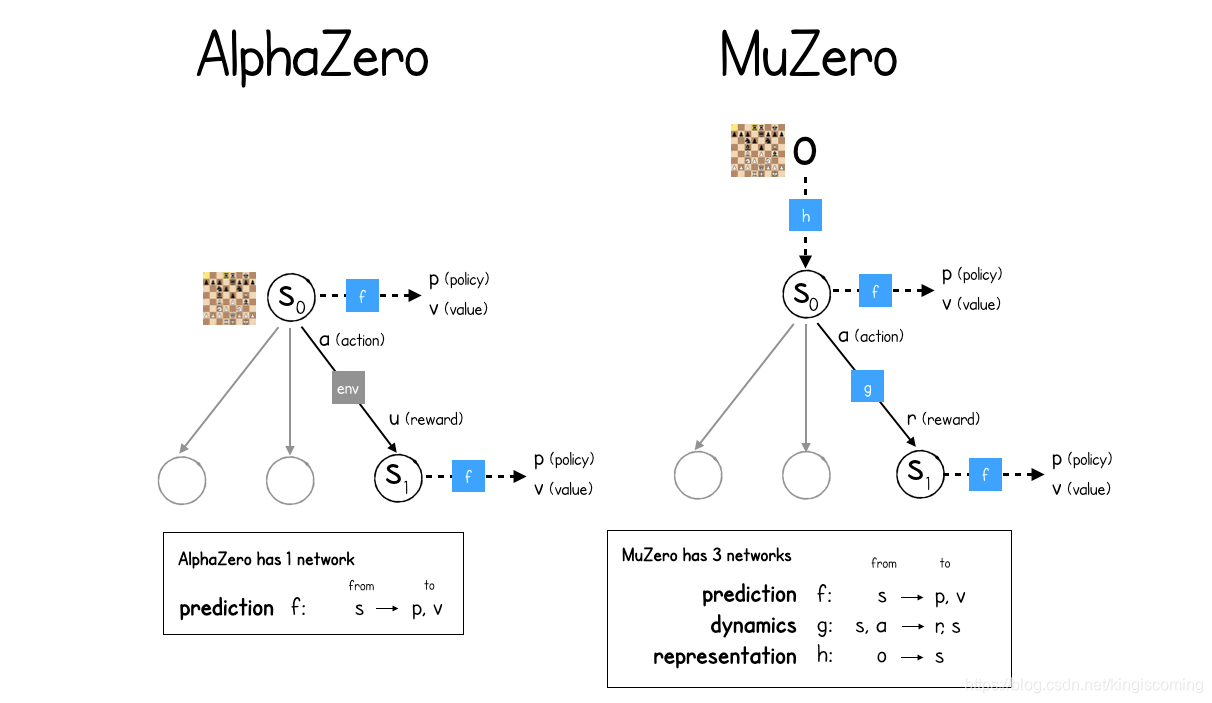
而AlphaZero只有一个神经网络(prediction),MuZero需要三个(prediction, dynamics, representation)
AlphaZero预测神经网络的工作f是预测给定游戏状态的策略p和价值v。该策略是所有动作的概率分布,其值只是估计未来奖励的单个数字。每当MCTS击中未探索的叶子节点时,都会进行此预测,以便可以立即将估计值分配给新位置,也可以为每个后续操作分配概率。这些值将回填到树中,再返回到根节点,以便在进行许多模拟之后,根节点已经探索了许多不同的未来,对当前状态的未来值有了很好的了解。
MuZero还具有预测神经网络f,但是现在它所运行的“游戏状态”是MuZero学习如何通过dynamics神经网络进行进化的隐藏表示g。dynamics网络采用当前的隐藏状态s和选定的动作,a并输出奖励r和新状态。请注意,在AlphaZero中,如何在MCTS树的状态之间移动只是询问环境的一种情况。MuZero没有这种奢侈,因此需要构建自己的动态模型!
最后,为了从当前观察到的游戏状态映射到初始表示,MuZero使用了第三表示神经网络h。
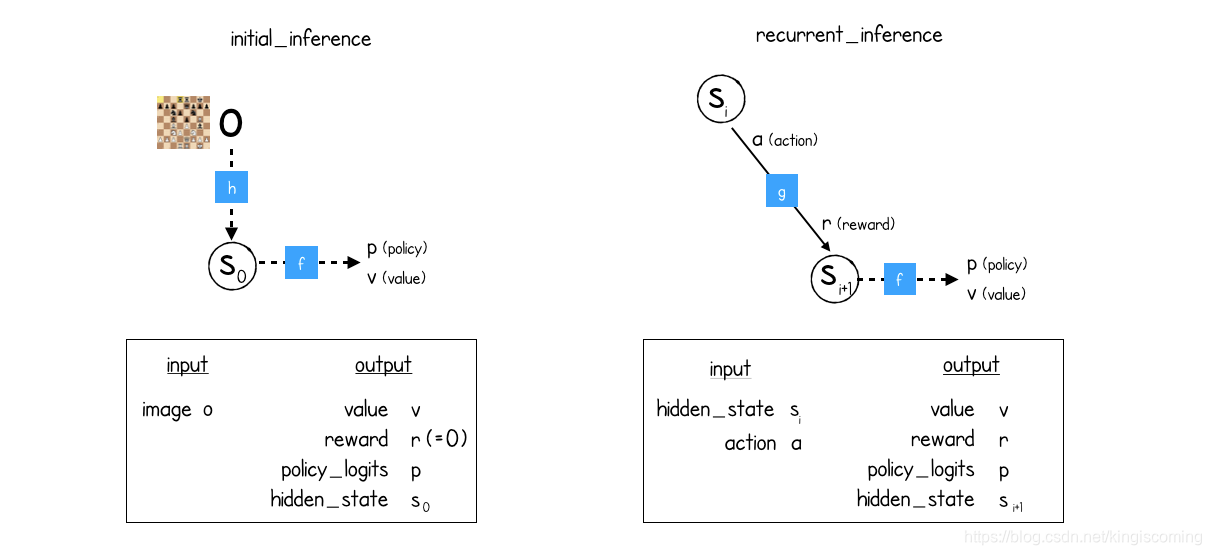
因此,为了遍历MCTS树进行预测,MuZero需要两个推理功能:
- initial_inference对于当前状态。h紧随其后的是f(表示然后是预测)。
- recurrent_inference用于在MCTS树内的状态之间移动。g其次是f(表示形式,然后是动态)。
class NetworkOutput(typing.NamedTuple):
value: float
reward: float
policy_logits: Dict[Action, float]
hidden_state: List[float]
class Network(object):
def initial_inference(self, image) -> NetworkOutput:
# representation + prediction function
return NetworkOutput(0, 0, {}, [])
def recurrent_inference(self, hidden_state, action) -> NetworkOutput:
# dynamics + prediction function
return NetworkOutput(0, 0, {}, [])
def get_weights(self):
# Returns the weights of this network.
return []
def training_steps(self) -> int:
# How many steps / batches the network has been trained for.
return 0
总而言之,在没有国际象棋实际规则的情况下,MuZero在自己的脑海中创造了一种新的游戏,它可以控制并使用它来计划未来。一起优化了这三个网络(预测,动态和表示),以使在设想的环境中表现良好的策略在实际环境中也表现良好。
reference
muzero-mastering-go-chess-shogi-and-atari-without-rules
Mastering Atari, Go, chess and shogi by planning with a learned model
how-to-build-your-own-deepmind-muzero-in-python