本文转载自:【CV】用于图像恢复的深度学习方法综述论文(2022年)
| 论文名称:A survey of deep learning approaches to image restoration |
Abstract
In this paper, we present an extensive review on deep learning methods for image restoration tasks. Deep learning techniques, led by convolutional neural networks, have received a great deal of attention in almost all areas of image processing, especially in image classification. However, image restoration is a fundamental and challenging topic and plays significant roles in image processing, understanding and representation. It typically addresses image deblurring, denoising, dehazing and super-resolution. There are substantial differences in the approaches and mechanisms in deep learning methods for image restoration. Discriminative learning based methods are able to deal with issues of learning a restoration mapping function effectively, while optimisation models based methods can further enhance the performance with certain learning constraints. In this paper, we offer a comparative study of deep learning techniques in image denoising, deblurring, dehazing, and super-resolution, and summarise the principles involved in these tasks from various supervised deep network architectures, residual or skip connection and receptive field to unsupervised autoencoder mechanisms. Image quality criteria are also reviewed and their roles in image restoration are assessed. Based on our analysis, we further present an efficient network for deblurring and a couple of multi-objective training functions for super-resolution restoration tasks. The proposed methods are compared extensively with the state-of-the-art methods with both quantitative and qualitative analyses. Finally, we point out potential challenges and directions for future research.
【研究意义】
在本文中,我们对用于图像恢复任务的深度学习方法进行了广泛的回顾。以卷积神经网络为首的深度学习技术在几乎所有图像处理领域,尤其是图像分类领域,都受到了广泛关注。然而,图像恢复是一个基本且具有挑战性的课题,在图像处理、理解和表示中起着重要作用。
【图像恢复的细分研究方向】
它通常处理图像去模糊 (image deblurring)、去噪 (denoising)、去雾 (dehazing) 和超分辨率 (super-resolution)。
【图像恢复方法】
用于图像恢复的深度学习方法的方法和机制存在很大差异。
-
基于判别学习的方法能够有效地处理学习恢复映射函数的问题。
-
基于优化模型的方法可以在一定的学习约束下进一步提高性能。
【本文工作】
在本文中,我们对图像去噪、去模糊、去雾和超分辨率中的深度学习技术进行了比较研究,
- 总结了这些任务所涉及的原理,从各种有监督的深度网络架构→残差或跳过连接→感受野→无监督自动编码器机制。
- 调查了图像质量标准 (Image quality criteria),并评估了它们在图像恢复中的作用。
- 基于我们的分析,我们进一步提出了一个有效的去模糊网络和几个用于超分辨率恢复任务的多目标训练函数。
【研究结果】
所提出的方法与定量和定性分析的最新方法进行了广泛的比较。最后,我们指出了未来研究的潜在挑战和方向。
1. Introduction
自上个世纪以来,图像恢复一直是数字图像处理的长期研究课题[1-5],并且近年来仍然是一个活跃的课题。图像恢复旨在从退化的观察中恢复干净的潜在图像,是一个典型的逆问题。多维退化观察 (multidimensional
degraded observations) 和恢复图像之间的无限可能映射决定了这种逆问题 (inverse problems) 的不适定性 (illposed nature)。对于映射已知且可逆的情况,对应的解很容易得到,但这种映射是唯一的,缺乏普遍性。在实践中,逆映射是未知的,因此解空间是无限的,需要应用正则化技术才能得出可行的最优解。因此,大多数图像恢复研究都致力于采用有效的分析模型和学习方案,以便找到精确映射的近似值来恢复退化的图像。
传统的图像恢复方法采用高等数学和概率模型来解决逆问题,主要基于迭代算法中的最大似然或贝叶斯方法 [6-8]。假设退化图像 Y 的一般公式是通过将干净图像 X 与模糊核 B 进行卷积并进一步添加噪声 N 的结果,如下所示,
先验可以根据各种任务进行调整,例如反卷积 [9-11]、超分辨率 [12-14]、修复 [15-17]、天文学领域 [18-20]、医学 [21-23]、显微镜 [24-26] 等。人们对利用连续图像帧之间的关系重建高质量干净图像和视频 [27-32] 的多帧和视频恢复的兴趣也越来越大。
在过去十年中,深度学习 (DL) 技术的迅速崛起极大地影响了各种计算机视觉任务,从识别和分类 [38-41] 到回归和生成 [42-45]。卷积神经网络(CNN)首先提高了分类和检测的性能[46],提出了许多网络架构来解决基准研究任务。
- VGGNet [47] 指出深度网络架构是有益的,而之前的研究主要集中在浅层网络 [48]。
- ResNet [39] 提供了图像恢复的基线结构,并成为以下几种方法的基本结构,如
- EDSR [49](用于超分辨率)
- DeepDeblur [50](用于图像去模糊)
- DnCNN [35](用于图像去噪)。
- DenseNet [51] 通过开发与密集连接的卷积层的残差链接来进一步提高网络性能。
深度学习方法为图像恢复带来了许多好处,例如,
- 基于学习的方法可以提高性能。在大多数基准数据集上,基于深度学习的方法通常明显优于传统方法。
- 深度学习使应用程序更加真实。人们可以通过考虑顺序帧或填充一些缺失的内容来恢复视频的退化,而退化过程不可能通过数学建模(例如,修复)。
- 通过使用图形处理单元 (GPU) 等并行处理单元,深度学习算法与计算机硬件自然契合,与使用 CPU 相比效率更高。
但是,仍然存在许多挑战:
- 从计算复杂度的角度来看,基于深度学习的方法具有相当大的计算成本,使得它们难以部署在实时处理中。此外,矩阵处理对计算机硬件的要求更高,在GPU和内存方面,工业上常用的嵌入式系统,例如微控制器单元(MCU)无法满足。
- 从性能上看,现有算法还有很大的提升空间。
- 从训练的角度来看,深度学习 CNN 需要大数据集,不易获取、不易标注,可能与实际情况不匹配。例如,许多去模糊或超分辨率应用更关注人脸,但大多数现有的训练数据集包含的人脸样本相对较少,而汽车或建筑物等许多其他样本可能对特定应用没有帮助。
还有一些与图像恢复高度相关的任务,例如 3D 重建 [52] 和图像修复 [53]。图像恢复中的想法和新方法可以使上述任务受益,反之亦然。
本调查旨在及时更新和概述图像恢复的深度学习方法,组织如下。
- 第 2 节总体上回顾了现有的用于图像恢复的深度神经网络,然后详细回顾了用于去模糊、去噪和超分辨率任务的模型。还审查和讨论了各种图像质量评估标准。
- 第 3 节回顾和分析了典型的网络架构和学习策略。简要考虑了最新的模型。然后,我们提出了一些用于去模糊和超分辨率任务的网络,以及与最先进模型的广泛实验和比较。
- 最后一节讨论了这些网络、性能和结果,以及剩余的挑战并总结了工作。还提出了未来的工作和研究方向。
2. Deep Networks for Image Restoration
2.1. Image Restoration
有几种方法可以在数字图像恢复中应用深度学习。通过深度学习神经网络学习图像先验或内核 [54–56,17] 是一种流行的方法。与复杂的手工图像先验和为推导此类先验所做的大量工作相比,通过深度学习神经网络学习先验作为不适定问题 (ill-posed problems) 的有效正则化项更有效。学习到的先验被集成到下一阶段的优化中,以通过可变分裂技术(例如 ADMM(乘法器的交替方向方法)[57] 和 HQS(半二次分裂)[58])恢复退化的图像,并有助于实现比那些基于分析模型的先验更优越的性能。此外,深度学习方法采用各种架构 [59,60,56,61] 和学习策略 [62,63],以便通过利用强大的学习能力从海量训练数据中提取重要信息来获得更好的解决方案。已经进行了大量的研究以将流行的深度学习技术应用于解决图像恢复任务。
最近,基于生成对抗网络 (GAN) 的方法已经占据主导地位,并超越了一般的基于 CNN 的方法,提升了最先进的性能 [64-66]。GAN 模型的强大兼容性和容量减轻了为特定应用专门设计网络的负担,但代价是更大和更深的网络和训练问题 [67-69]。此外,这些先进的网络在各种应用中取得了重大进展,包括水下成像 [63,70]、光场成像 ( fluorescence) [60]、荧光 ( fluorescence) 图像重建 [71] 和计算机断层扫描 (computerised tomography) 超分辨率 [72]。
2.2. Image Deblurring
模糊图像 (Blurry images) 在实践中是常见的,并且由于各种因素,如长曝光时间内不可避免的运动、成像设备的物理限制和不完善的系统、未知的退化过程等,这些退化图像的恢复是困难的 (intractable)。研究人员付出了许多努力,并致力于开发有效和新颖的方法来解决这些挑战性的问题。
动态场景模糊 (Dynamic scene blurs) 在现实生活的图像捕捉中普遍存在。模糊可能是由相机运动、物体运动和场景深度变化的混合造成的。相机运动有两类六个自由度,平移和旋转运动。平移运动与深度变化有关 [73,74],而旋转相机运动和物体运动是独立的因素,也会导致图像中的不均匀模糊。由于这些运动模糊在空间上是变化的,因此对成像和退化过程建模不是一项简单的任务,尤其是当只有单个模糊图像可用时。许多尝试有助于通过使用先验知识和对图像的额外观察来建立近似真实模糊核的模型。
有研究回顾了代表性的作品并比较了单个图像去模糊的性能。Wang等人[75]对图像去模糊的传统方法进行了回顾,定义了常见成像中出现的模糊,并根据各自的特征将方法分为五个主要框架。由于基于学习的方法当时还没有得到很好的发展,神经网络只是被认为是一个有希望进一步研究的课题。Lai等人[76]使用他们自己的真实世界模糊图像和人类受试者研究(Amazon Turk)评估和比较了13种单一图像去模糊算法。最近的NTIRE(图像恢复和增强的新趋势)2020图像和视频去模糊挑战介绍了最先进的方法,并提供了公平的排名和性能比较[77]。Koh等人[78]提供的最新调查回顾了自2013年以来基于深度学习的非盲和盲去模糊技术的发展。在该论文中,一项比较研究阐明了知觉损失引起的伪影、显式图像先验的优越性和无监督学习的潜力。
有研究回顾了代表性作品并比较了单张图像去模糊的性能。
- Wang et al. [75] 对传统的图像去模糊方法进行了回顾,定义了常见成像中发生的模糊,并根据各自的特征将方法分类为五个主要框架。由于当时基于学习的方法还没有得到很好的发展,神经网络只是被认为是一个有前途的进一步研究的课题。
- Lai et al. [76] 通过使用他们自己的真实世界模糊图像和人类主题研究 (Amazon Turk) 评估和比较了 13 种单图像去模糊算法。
- 最近的 NTIRE(图像恢复和增强的新趋势)2020 年图像和视频去模糊挑战介绍了最先进的方法,并提供了公平的排名和性能比较 [77]。
- Koh et al. [78] 提供的最新调查。回顾了自 2013 年以来基于深度学习的非盲和盲去模糊技术的发展。在论文中,一项比较研究说明了由感知损失引起的伪影 (artifacts),显式图像先验的优越性和无监督学习的潜力。
多尺度去模糊网络 (Multi-scale deblurring networks) 使用“从粗到细”的结构通过几个步骤来恢复图像。
- 它最早是在[50]中提出的,它应用了 Eigen et al. [79] 开发的多尺度结构。
- Tao et al. [80] and Gao et al. [81] 开发了多尺度去模糊网络,Zhang et al. [82] 在采用时对结构和机制进行了根本性的后续更改,与其他三种方法相比存在显着差异。
DeblurGAN 由 [33] 提出,这是 条件GAN 首次用于去模糊问题。
-
该方法使用残差网络块 [39] 作为生成器的主要组件。
-
DeblurGAN-v2[64] 是 DeblurGAN 的更新版本,使用最初提出用于对象检测 [83,84] 的特征金字塔网络 (FPN) 作为生成器。
-
[85] 的作者提出了一个由无监督 CNN 组成的端到端去模糊网络。以前,有监督的深度学习网络广泛依赖于大量的配对数据,这对获取要求很高且具有挑战性,而无监督的训练方案可以实现与非配对数据相当的性能。
-
[86] 提出了另一种基于分离表示的无监督网络,用于特定领域的单图像去模糊。
[87] 的作者提出了一种称为 Dr-Net 的新型网络。他们使用 Douglas-Rachford 迭代来解决去模糊问题,因为它比近似梯度下降算法更适用的优化过程。 [88] 报告说,受严重模糊影响的图像的恢复需要具有大感受野的网络设计,并提出了一种由区域自适应密集可变形模块组成的新架构,该架构可以隐式地发现导致输入图像中不均匀模糊的空间变化移位,并学习调制滤波器。
表1、表2和表3给出了各种不同方法的比较。
2.3. Image Denoising
图像去噪是图像恢复中的另一项重要任务,从多方面对低层次视觉具有非凡的价值。首先,在各种计算机视觉任务中去除噪声通常是必不可少的预处理步骤。其次,图像去噪是从贝叶斯角度评估图像先验模型和优化方法的理想测试平台[94]。传统上,BM3D [91] 是一种主流方法,通过将相似的 2-D 图像片段(例如,块)分组到 3-D 数据阵列中来增强稀疏性。基于学习的去噪不仅关注深度学习,还关注其他机器学习方法。这种差异是由于噪声机制广泛适用于许多信号处理方法。在本文中,我们专注于基于 DL 的去噪及其与其他图像处理任务(如去雾和去噪)的共性。有关基于学习的图像去噪的概述,请参见 [109]。在数学上,噪声图像 Y 可以表示为
其中 X 表示真实图像,N 表示被 X 破坏的加性噪声。噪声本质上也可以是乘法的。深度 CNN 于 2015 年开始应用于图像去噪[110,111]。第一个重要的工作是 [112],它首先应用了一个非常深的带有跳跃连接的 CNN。 [93] 开发了一种具有核喷射 (kernel-splatting) 架构的蒙特卡罗去噪方法。
根据噪声的类型,图像去噪可分为四类:
- 加性白噪声图像(additive white noise image, AWNI)去噪
- 真实噪声图像去噪
- 盲去噪
- 混合图像去噪
在这些类别中,AWNI 最受关注。然而,AWNI 的流行并不能反映真实的噪声图像。因此,虽然AWNI去噪包括高斯、泊松、盐 (salt)、椒 (pepper) 和乘性噪声,但与实际应用场景仍有差距。
可以在最近的概述 [109] 中找到相关的。在本小节中,我们的目标是比较基于学习的去噪方法以及其他图像恢复任务。为去噪开发的许多想法和技巧也适用于其他图像逆问题,反之亦然,许多重要的去噪网络都受到现有低级视觉工作的启发。例如,DnCNN [35]首先提出了图像恢复中的残差学习。这里的残差学习学习不同于 ResNet [39]。它采用单个残差单元来预测残差图像。一般来说,DnCNN 使用长残差链接将输入图像直接连接到输出,这样网络只需要学习残差图像,而不必关注图像的内容。残差学习方法对图像恢复有很大的影响,自 DnCNN 以来,大多数去模糊和超分辨率网络都使用残差链接。综合图像去噪方法的比较见表 4。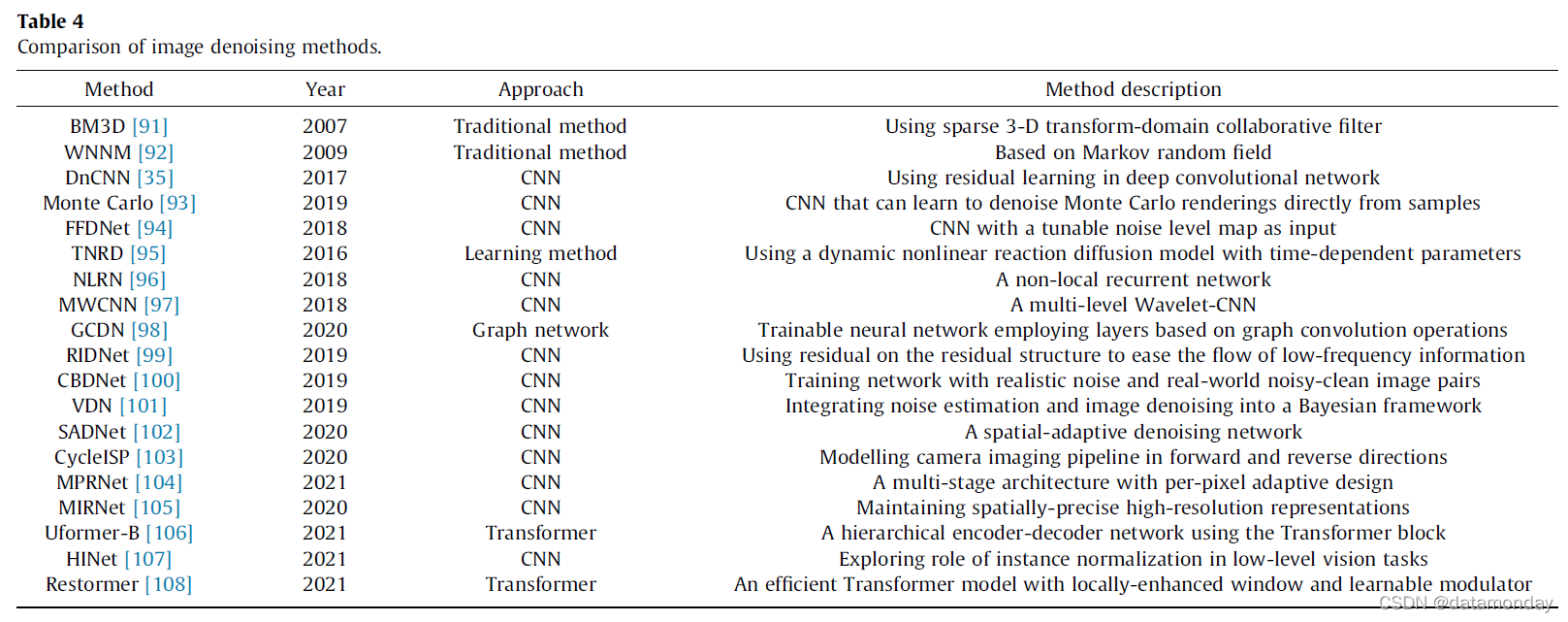
2.4. Image Dehazing
大气散射模型是模糊图像生成的经典描述:
其中 Y 是观察到的有雾图像,X 是要恢复的无雾场景辐射度。有两个关键参数:A 表示全局大气光,t 是透射矩阵,定义为:
其中b是大气的散射系数,d是物体与相机之间的距离。
由于雾、尘等混浊介质的存在,雾霾的存在导致照片的可见度差,并为图像增加了数据相关、复杂和非线性的噪声,使去雾成为一个不适定且极具挑战性的恢复问题。许多计算机视觉算法只能在没有雾霾的场景辐射度上运行良好。
- [113]重新构建了一个图像形成模型,该模型除了传输函数之外还考虑了表面阴影。
- [114] 基于室外无雾图像的图像块通常具有低强度值的假设,提出了暗通道先验 (DCP) 从单个图像中去除雾。
- [115] 是一种基于早期学习的方法。
- [116] 提出了一种基于重新制定的大气散射模型,通过轻量级 CNN 直接生成干净图像的一体化方法。
- [117] 通过使用鉴别器引导生成器在粗略的尺度上创建伪逼真图像,引入了用于去雾的GAN,而生成器之后的增强器则需要在精细尺度上产生逼真的去雾图像。
- [118] 采用平滑扩张技术并利用门控子网络融合不同层次的特征。
- MSRL-DehazeNet [119] 依赖于多尺度残差学习和图像分解。
- RYF-Net [120] 使用传输图融合网络来整合两个传输图,并为雾霾图像估计鲁棒准确的场景传输图。
- [121]包含一个监督学习分支和一个无监督学习分支。
- DCP-Loss [122] 使用暗通道先验作为损失函数。
- [123] 的作者提出了一种基于异构 GAN 的方法,该方法由用于生成清晰图像的 CycleGAN 和用于保留纹理细节的条件 GAN 组成。
- Cycle-dehaze [124] 中可以看到类似的工作。
- FAMED-Net [125] 包括三个尺度的编码器和一个融合模块,以有效和直接地学习无雾图像。
- [126]提出了一种域适应范式,由一个图像翻译模块和两个图像去雾模块组成。
- [127] 的作者采用了一种新颖的基于融合的策略,通过应用白平衡 (WB)、对比度增强 (CE) 和伽马校正 (GC) 从原始模糊图像中获取三个输入。
- 与许多图像去模糊网络类似,DCPDN [128] 采用密集连接结构。
表 5 给出了基于学习的图像去雾方法的比较。见图 1。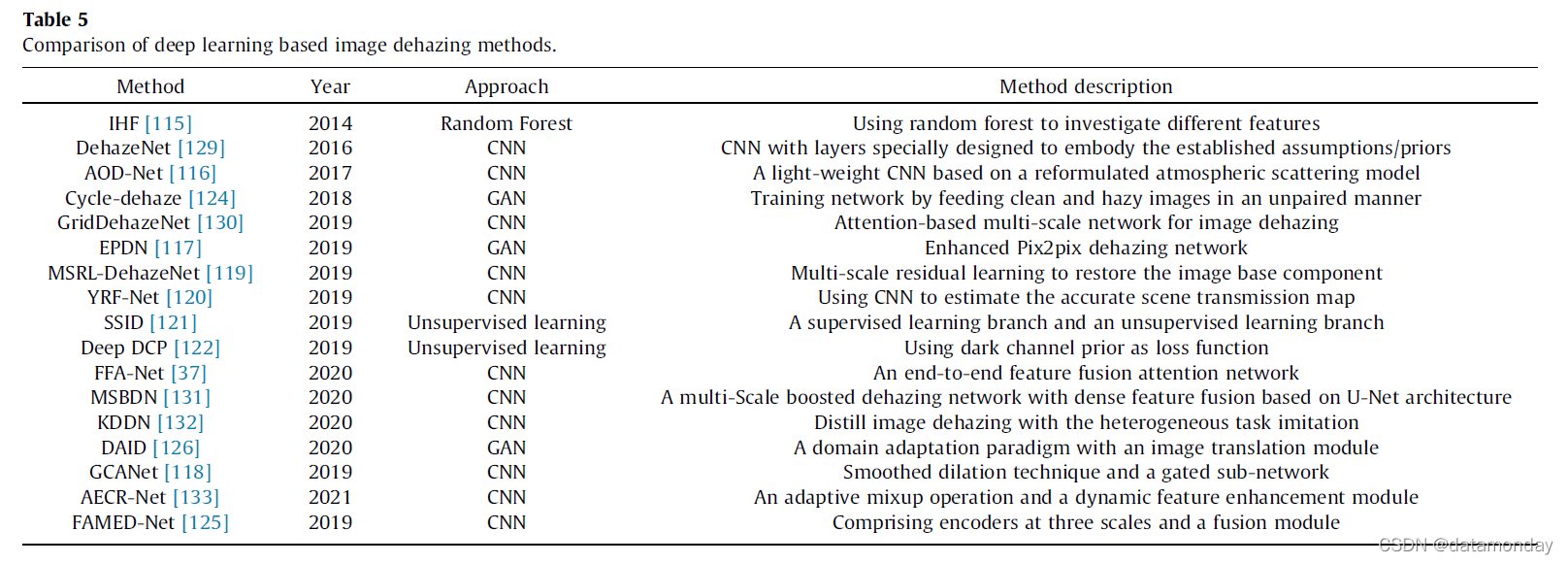

2.5. Image Super-resolution
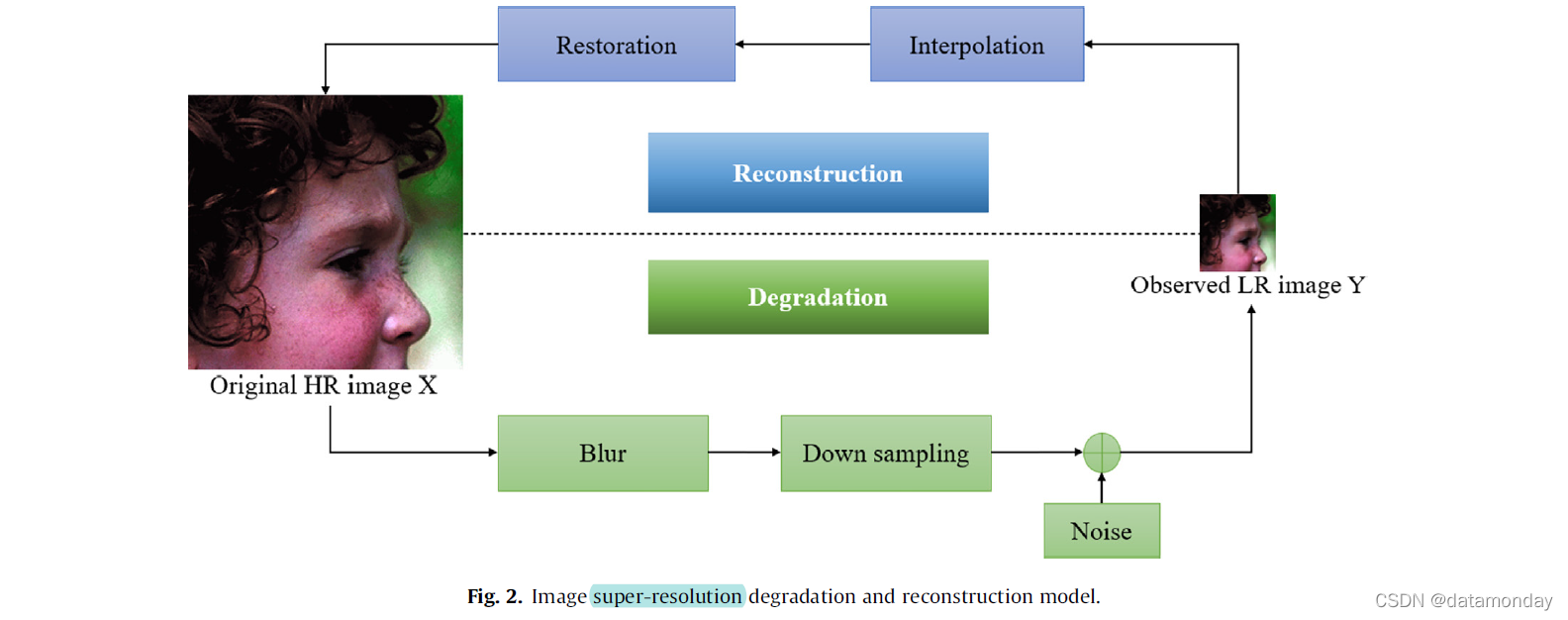
超分辨率(SR)是一种重建高分辨率图像的技术,它有效地克服了成像系统的固有局限性[134]。由于其在广泛的应用中的实用价值而引起了广泛的关注。在超分辨率发展的早期阶段,多个低分辨率(LR)图像的可用性被认为是基本前提,恢复和插值技术是先决条件,它们共同有助于获得高分辨率(HR)图像。当只有一张 LR 图像可用时,该问题变得更具挑战性,被称为单图像超分辨率 (SISR)。与其他恢复任务不同,在去模糊之后,SR 中需要额外的上采样过程来增加图像维度并获得 HR 图像。在方程 1 的基础上,退化 (degradation) 在模糊后应用下采样算子 D,如公式 7 所示。观测模型如图 2 所示。
2.6. Image Quality Assessments
图像质量评估 (Image qualitu assessment, IQA) 对于确定图像质量、图像处理算法和成像系统至关重要。只有提供统一的质量度量,才能进行公平的比较,以令人信服和可靠的证据反映算法和系统的特征和属性。最初,图像质量测量 (IQM) 主要用于评估图像压缩和采集技术,然后推广到其他图像处理任务和图像通信网络 [153]。由于图像的最终接收者是人类,因此对图像视觉质量最可靠的评估是通过收集大量测试示例的评分的主观人类研究。但是,进行此类研究以在实践中为每个案例提供质量评估是耗时且通常过于昂贵的。因此,非常需要一种旨在有效预测感知质量同时与人类视觉系统 (HVS) 响应相关的客观 IQA。
客观质量测量最常见的分类是根据参考图像的可用性,即
- 全参考 (full-reference, FR) 质量测量:计算失真图像和参考图像之间的相似性。
- 减少参考 (reduced-reference, RR) 质量测量:当参考图像的部分信息可用时应用 RR 测量。
- 无参考 (no-rederence, NR) 质量测量:NR 测量利用图像统计来评估图像质量,因为参考图像的信息完全不可用。
最简单的客观 FR 测量是峰值信噪比 (peak signal-to-noise ratio, PSNR),基于参考图像和退化图像之间的均方误差 (MSE)。
-
尽管被广泛采用,但众所周知,像 PSNR 这样的图像保真度测量无法很好地与视觉质量相关联[154,155]。
-
[156] 介绍了结构相似性指数测量(Structural similarity index measure, SSIM)。进一步近似 HVS 的质量评估,利用其在结构信息变化中的敏感性。 SSIM 有一些变体,如多尺度 SSIM [157]、三分量 SSIM [158] 和四分量 SSIM [159],进一步发展以进行泛化。
-
此外,还可以引入信息论来推导图像质量评估,例如 [160] 提出的信息保真度标准 (IFC)。
-
随后是视觉信息保真度测量 (VIF) [161] 的扩展工作。
-
此外,诸如特征相似性指数测量 (FSIM) [162]、DCTune [163]、基于小波的失真测量 [164]、基于 Haar 小波的感知相似性指数 (HaarPSI) [165] 等测量,利用来自其他域的图像特征来近似响应的 HVS。
-
许多研究对 FR IQA [166–168, 160,169–171] 提供了有价值的评论。
-
RR IQA 措施适用于存在参考图像或退化过程的部分信息时,并且可以被视为中间情况,灵感来自 FR 和 NR IQA 措施 [172-175]。
表 6 中给出了具有方程的代表性 FR 和 RR 方法。
当原始参考图像无法用于质量评估时,NR IQA 措施很有用。大多数 NR IQA 措施采用的一个共同特征是自然场景统计(natural scene statistics, NSS)[177,178],它对各种退化和图像内容具有不变的属性,这些措施包括:
-
盲/无参考图像空间质量评估器(BRISQUE)[179]
-
基于失真识别的图像真实性和完整性评估器(DIIVINE)[180]
-
自然图像质量评估器(NIQE)[181]。
图 3 提供了代表性 NR 方法的流程:BRISQUE、BLIINDS-II [182]、DIIVINE 和 NIQE。 NR IQA 还采用了其他功能,例如 DCT 域中的 NSS [183,182],多元高斯模型中的 NSS [184],梯度幅度[185,186]等。[187]中提出的感知指数(PI)结合了两种NR方法([181,188]),用于对生成的图像进行感知评估。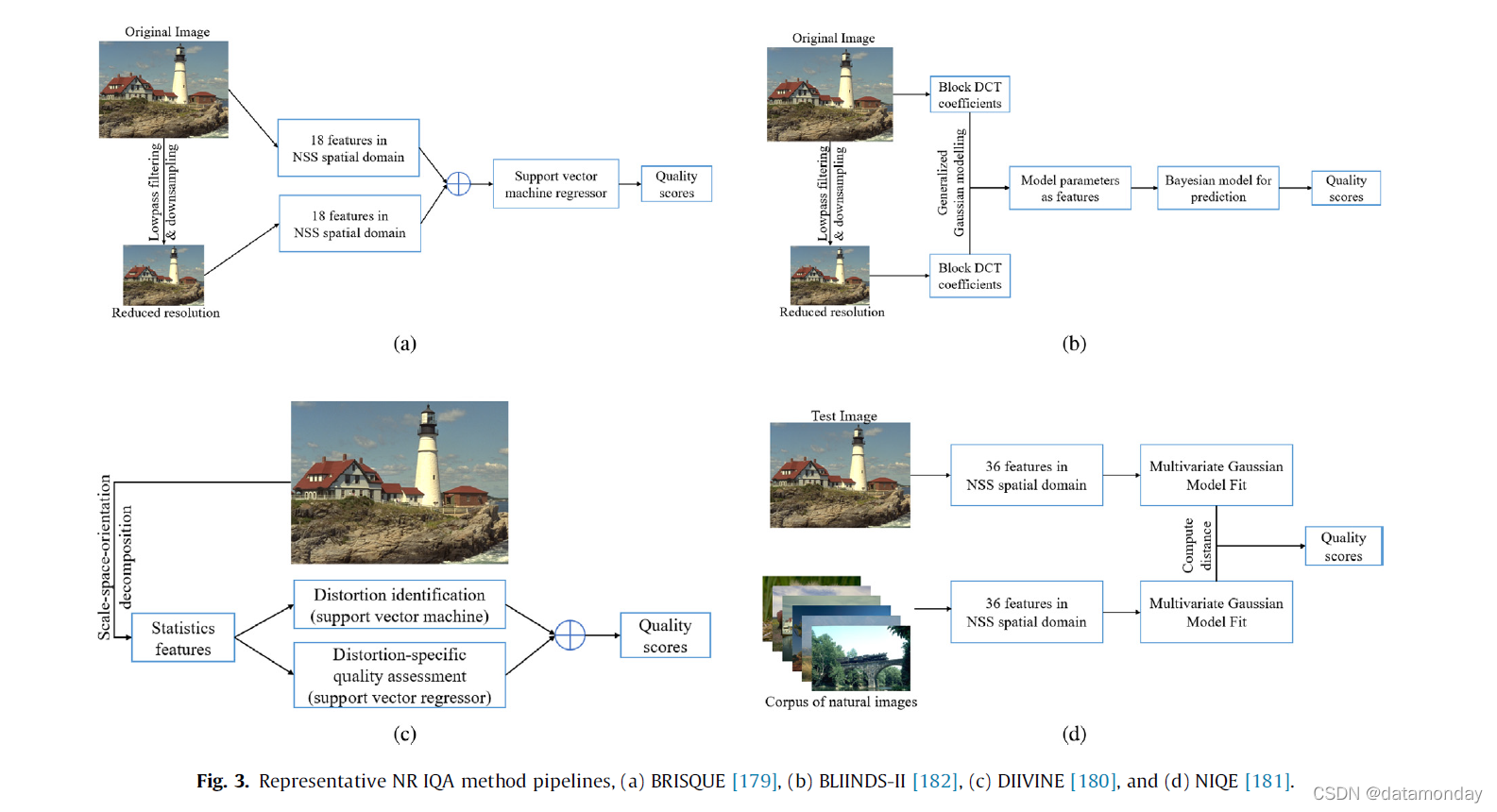
在 IQA 测量的开发过程中,许多研究报告了基于失真的测量和感知质量测量之间的冲突。因此,在 [189] 中系统地说明了感知和失真之间的权衡。已经进行了相关研究来分析这种权衡[190,191],并且讨论得出的结论是,可以在保真度或感知质量方面提高图像质量,但会相互牺牲。
最近,深度学习被开发为 IQA 的替代范式,该范式通过人类主观质量评估(即平均意见分数(MOS)或差分平均意见分数(DMOS))学习将图像映射到来自训练集的失真图像的数值分数 [192 –200]。端到端训练使深度神经网络能够实现比以前的手工方法更好的预测精度。但考虑到采集ground truth MOS/DMOS值的难度,性能优化和泛化能力受限于有限的训练集。模型复杂性和微调网络超参数对于推广基于深度学习的方法来说也是一项重要且关键的任务。
3. Network Architectures and Learning Strategies
3.1. Baseline Models
多层感知器 (MLP) [201] 是最早用于图像恢复的人工神经网络之一 [202-206]。恢复需要相同维度的输入和输出图像,MLP 框架(图 4a)遵循全连接网络的结构,并且能够学习退化的输入图像和清晰的潜在图像之间的高维映射。然而,由于大量参数的冗余给计算资源和存储带来负担,MLP 效率低下。此外,MLP 忽略了跨通道的空间信息和多维图像的内容,这是进一步发展的另一个障碍。
考虑到图像的结构特性和 MLP 的不足,采用卷积神经网络(图 4b)(例如 [207])并为图像恢复提供更合适的解决方案。卷积神经网络 (CNN) 具有共享权重、架构稀疏性、训练稳定性和分层特征提取等优点,因此实现了非凡的性能并成为新的最先进的方法。尽管观察到增加网络深度通过大感受野和有意义的层次特征有利于 CNN 的模型性能,但训练稳定性和计算资源成为棘手的问题。因此许多先进的技术来处理这些问题。发明了残差学习和跳跃连接来稳定训练[39]。残差块(图 4c)可有效提高性能,并成为许多深度残差网络的新构建块(图 4d)。其他网络范例包括无监督学习方案下的编码器-解码器、自动编码器和变分自动编码器,旨在从训练数据中学习高级稀疏表示(图 4e)。多尺度网络(图 4f)专门处理各种尺度的退化。生成对抗网络 (GAN)(图 4g)[208] 所示,结合了生成建模和对抗学习的优势,在生成的图像中产生似是而非的纹理。由于基于 GAN 的模型中所需的配对训练图像难以获得,因此提出了非配对训练,例如cycleGAN [209],将循环一致性损失设计为一种生成高质量图像的正则化技术(图 4h)。为了防止模式崩溃问题,[210](图 4i)中采用了解缠结表示(disentanglement representation),以提供一种新的替代方案,在没有对齐的训练数据的情况下生成不同的输出图像。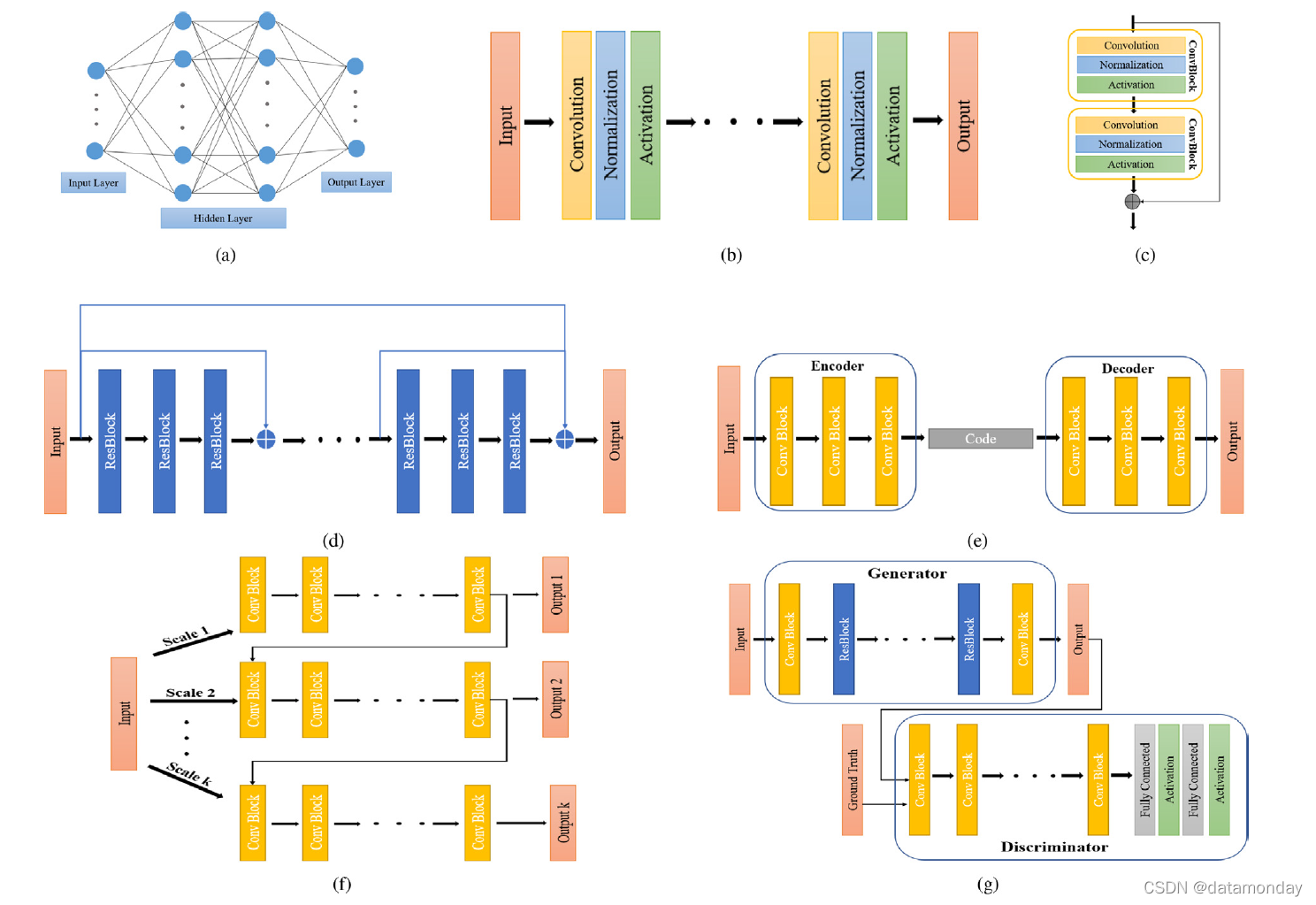
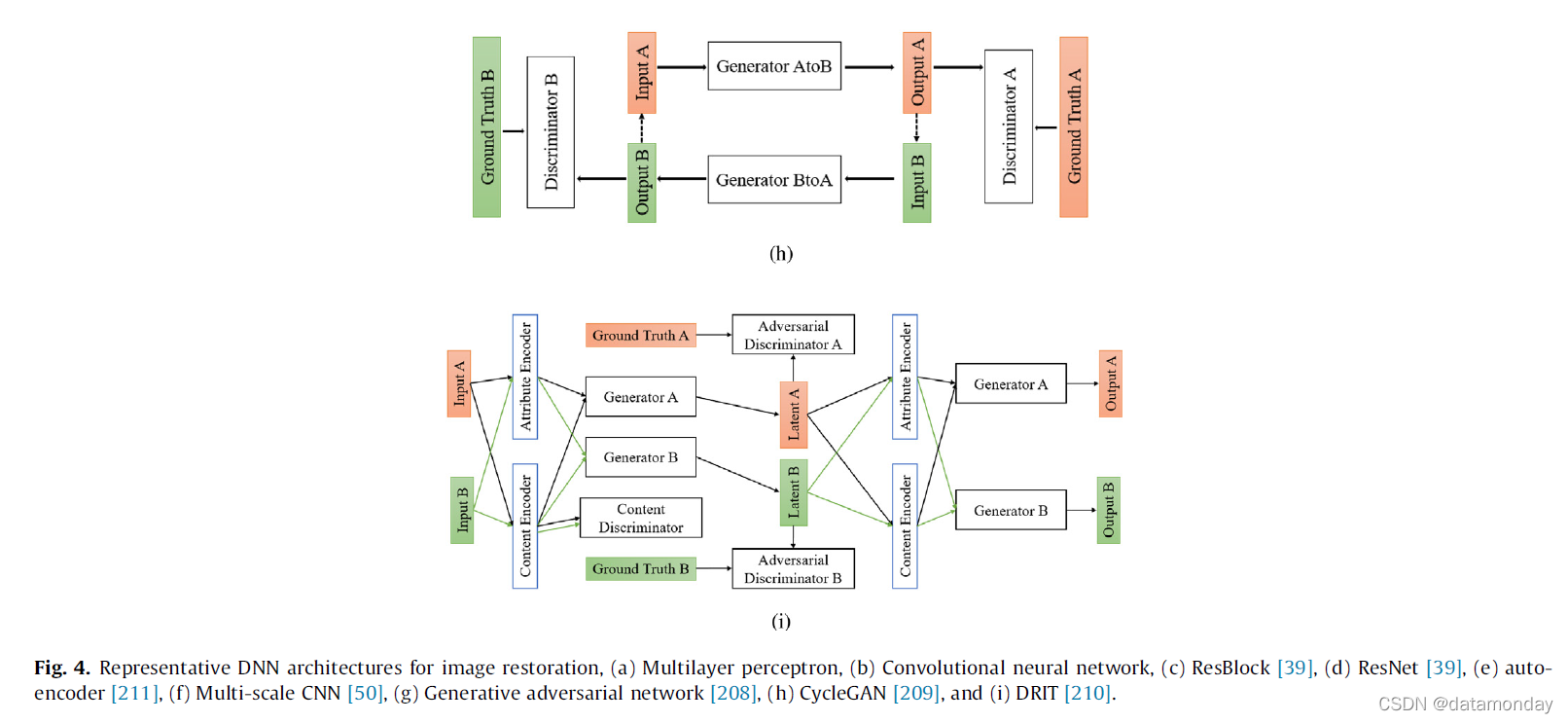
3.2. Learning Strategies
3.2.1. Supervised, semi-supervised and unsupervised learning
只要有标记的数据可用,采用监督学习来训练神经网络是常见且直接的。通过网络层最小化成本函数和反向传播可在有效监督下实现强大的学习能力。它鼓励网络向目标分布收敛并产生所需的输出。典型的应用是分类和回归,目的是预测或推理。然而,对于训练深度神经网络,由于复杂的底层映射函数和有限的训练数据,监督学习容易过度拟合和/或泛化能力差。为了缓解这些问题,早期停止 [212]、dropout [213] 和权重共享 [214] 等技术用于规范模型复杂性,这些技术在当今设计和训练深度神经网络中变得必要。此外,收集匹配的图像对以训练图像恢复中的深度网络非常耗时。
无监督学习可以发现数据中的底层结构和模式,从而提供输入和输出之间映射的潜在见解。因此,首先学习代表性特征是有用的,然后学习的特征可以用于监督学习下的其他任务或生成模型[215-217,210,218,209]。原始输入和重建输出之间的重建损失对于无监督学习利用深度网络的表示能力很重要。通过降维和重构,自动编码器采用编码器-解码器结构来学习图像的稀疏表示 [112,219]。对于像图像到图像转换这样的域迁移任务,无监督机制是必不可少的[220-222]。在实践中,标记或配对训练数据的数量总是稀缺的。为了利用大量未标记数据和少量标记数据,半监督学习[223]利用了监督和非监督学习的内在优势。在监督下,深度网络能够从训练数据中生成所需的输出,但性能也受到限制。未标记的数据便宜且易于获取,无监督和半监督学习使用它们来提高网络在准确性和泛化能力方面的性能。并且表明,在预先指定的假设下,对于某些类别的问题,无监督学习能够胜过监督学习[224-230]。 [121] 的作者在 CNN 中采用了半监督学习,该 CNN 包含一个监督分支和一个无监督分支,用于单图像去雾。 [231] 中的作者使用半监督学习来训练深度 CNN 以去除单幅图像雨水,并取得了比最先进的方法更优越的性能。
3.2.2. Autoencoder and adversarial networks
自动编码器:自动编码器是一种神经网络,用于以无监督或自监督的方式学习有效的数据编码或表示。自动编码器的目的是在降维空间中学习一组数据的表示。与降维一起,自动编码器的重建部分尝试从降维编码中生成尽可能接近其原始输入的表示。自动编码器存在许多变体,旨在强制学习的表示假设有用的属性。例如,正则化自动编码器(稀疏、去噪和收缩),它们在学习后续分类任务的表示方面是有效的。 Autoencoders 和 aariational auto-encoders 可以用作生成模型的一个组成部分。自编码器广泛用于图像去噪[232,233]和超分辨率[234-236]。像 [237] 这样的去模糊网络也与自动编码器有关。具体来说,作者使用 GAN 生成模糊图像作为给定输入清晰图像的表示,并将自动编码器的重建部分用作去模糊网络。
对抗网络:Goodfellow 等人 [208] 介绍的生成对抗网络,是定义两个竞争网络之间的博弈:鉴别器和生成器。生成器从输入接收信息并生成样本。鉴别器从真实样本和生成样本中学习,并尝试区分它们。生成器的目标是通过生成无法与真实样本区分开的感知上令人信服的样本来欺骗鉴别器。生成器 G 和判别器 D 之间的博弈具有以下极小极大目标: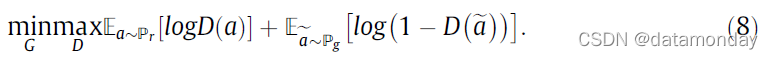
其中 Pr 是数据或真实样本分布,Pg 是生成器模型分布。 GAN 以其在视觉任务中生成具有良好感知质量的样本的能力而闻名。然而,GAN 的 vanilla 版本的训练通常会遇到许多问题,例如模式崩溃和梯度消失,如 [67] 中所述。最小化 GAN 中的值函数等于最小化 a 上数据和模型分布之间的 Jensen-Shannon (JS) 散度。[238] 讨论了由 JS-散度 近似引起的GAN训练困难,并提出使用 Earth-Mover(也称为 Wasserstein-1)距离 W ( q , p ) W(q,p)W(q,p)。 Wasserstein-GAN 的价值函数是使用 Kantorovich-Rubinstein 对偶[239]构建的: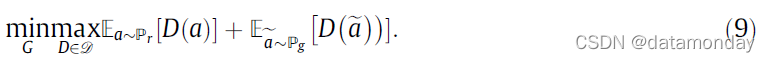
其中 D 是 1-Lipschitz 函数的集合,Pg 是模型分布。
这里的想法是批评价值接近 K × W ( P r , P θ ) K \times W(P_r,P_{\theta})K×W(Pr,Pθ),其中 K 是 Lipschitz 常数,W Pr; W ( P r , P θ ) W(P_r,P_{\theta})W(Pr,Pθ) 是 Wasserstein 距离。在这种情况下,鉴别器网络称为 critic,它近似于样本之间的距离。为了在 WGAN 中强制执行 Lipschitz 约束, [238] 为 [-c, c] 添加了权重裁剪;[240] 建议在值函数中添加梯度惩罚项,作为强制 Lipschitz 约束的替代方法:
这种方法对于生成器架构的选择是稳健的,并且几乎不需要超参数调整。这对于图像去模糊至关重要,因为它允许使用轻量级架构,而不是之前用于图像去模糊 [50] 的标准 Deep ResNet 架构 [39]。基于 GAN 的方法在去噪 [241-245] 和超分辨率 [36,246-250] 中也很流行。
3.3. State-of-the-Art models
基于学习的单幅图像恢复仍然是一个活跃的话题。除了运动去模糊,散焦去模糊 (defocus deblur) 引起了越来越多的关注。例如,[251] 利用了大多数现代相机上的双像素(DP)传感器上可用的数据,[252] 提出通过将经典的 Wiener 反卷积框架与学习的深度特征相结合,在特征空间中执行显式反卷积过程。
图像恢复进一步发展的一个重要方向是结合图像处理和深度学习/机器学习方法。对于图像超分辨率,研究人员开始关注不同的场景。例如,使用内部数据可以像使用单个图像一样训练超分辨率网络,这称为零样本 (zero-short) 超分辨率(ZSSR)[253],MZSR [254] 通过添加元-训练阶段,加快训练速度。图神经网络也开始在超分辨率方面让路[255]。对于图像去噪,[256] 引入了一个名为 Nose2Siame 的自监督去噪框架,通过推导典型监督损失的自监督上限,提出了一种新的自监督损失。 Nose2Siame 既不需要 J 不变性(这可能导致更差的去噪模型),也不需要关于噪声模型的额外信息,因此可以用于更广泛的应用。
4. Proposed Networks
4.1. Super-resolution
由于训练目标函数中涉及多个损失分量,因此需要同时最小化各种损失。线性组合是最直接的手段,但加权和加法后的组合损失可能不是凸的,难以通过梯度下降推导出最优解。我们假设多个损失分量自然形成的多维损失空间是欧式的,每个单独的损失代表空间中相互独立的一个维度。我们建议最小化的训练目标可以定义为损失位置和原点之间的欧几里得距离,或者由损失和损失边界限制的超体积(图 5)。因此,复杂的多目标优化问题转化为单目标优化。表 7 描述了数学公式。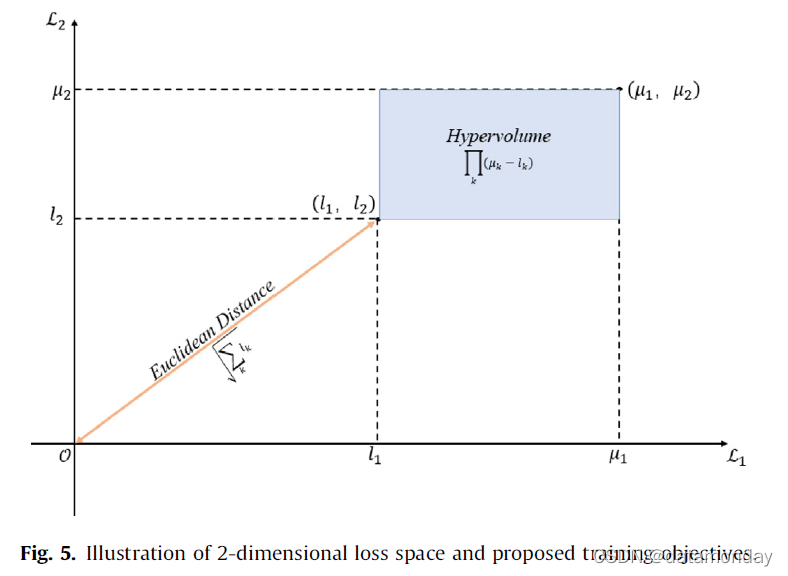

[257] 中提出的 Ed 和 Hypervol 公式的共同特征是在训练过程中学习的梯度加权,以及对每个单独损失的自动重要性分配。与大多数现有方法采用的手动微调加权参数相比,所提出的训练目标函数的 Ed 公式提供了一种优化给定模型结构的模型性能的替代方案。
这两种方法的梯度加权因子不同。基于欧几里得距离的方案利用个体损失在原点和损失位置之间的欧几里得距离上的投影。而 Hypervol 公式的梯度加权因子计算损失和相应损失界限之间距离的倒数。从表 7 可以看出,Ed 公式的方程更加简洁,没有额外的超参数需要预定义,而 Hypervol 公式需要在实现之前确定损失边界 lk。
我们在基线模型 SRGAN [36] 上应用了提出的方法,并采用了与 SRGAN 论文中相同的实现细节。在原论文[36]给出的对抗性损失Ladv和感知损失LX的基础上,我们还加入了 MSE 损失LMSE 和 SSIM 损失 LSSIM 作为附加约束,形成多维损失空间。损失函数如下,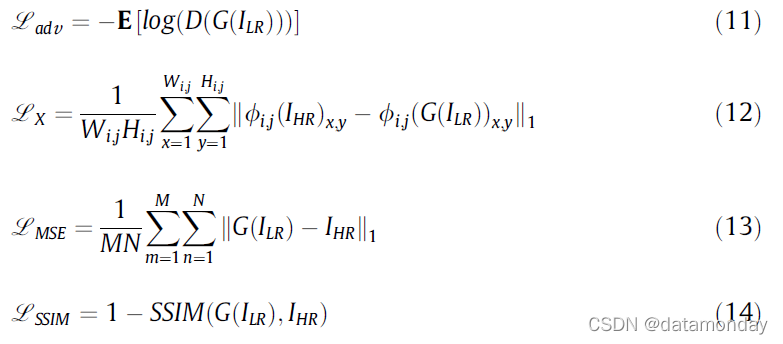 其中 ILR 表示输入低分辨率图像,IHR 表示高分辨率图像,ϕ i ; j \phi_{i;j}ϕi;j 是VGG19网络中第 i 个最大池化层之前第 j 个卷积激活后得到的特征图。Wi;j 和 Hi;j 是特征图的维度。
其中 ILR 表示输入低分辨率图像,IHR 表示高分辨率图像,ϕ i ; j \phi_{i;j}ϕi;j 是VGG19网络中第 i 个最大池化层之前第 j 个卷积激活后得到的特征图。Wi;j 和 Hi;j 是特征图的维度。
对于训练目标函数的原始公式,在[36]中给出的方程的基础上,L = 10^-3 Ladv + LX,加入加权为 10^-2 的 MSE 损失 LMSE 或 SSIM 损失 LSSIM,构成多目标训练函数,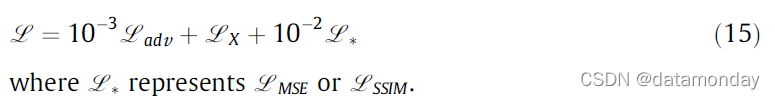
我们在四个 SR 数据集 Set5 [258]、BSDS100 [259]、DIV2K 验证集 [260] 和 RealSR [261] 上测试了我们的方法。定量结果在表 8 中给出。对于视觉比较,示例测试图像和补丁如图 6 所示。我们使用了四种质量评估措施:基于失真的 PSNR、SSIM 和基于感知的 VIF、PI。对于 PSNR、SSIM 和 VIF 指标,测量值越高,测试图像的质量越好,而 PI(感知指数)越低质量越好。 PSNR、SSIM 和 VIF 指标的描述和计算见表 6,PI 使用 Ma 的分数 [188] 和 NIQE [181] 计算如下,
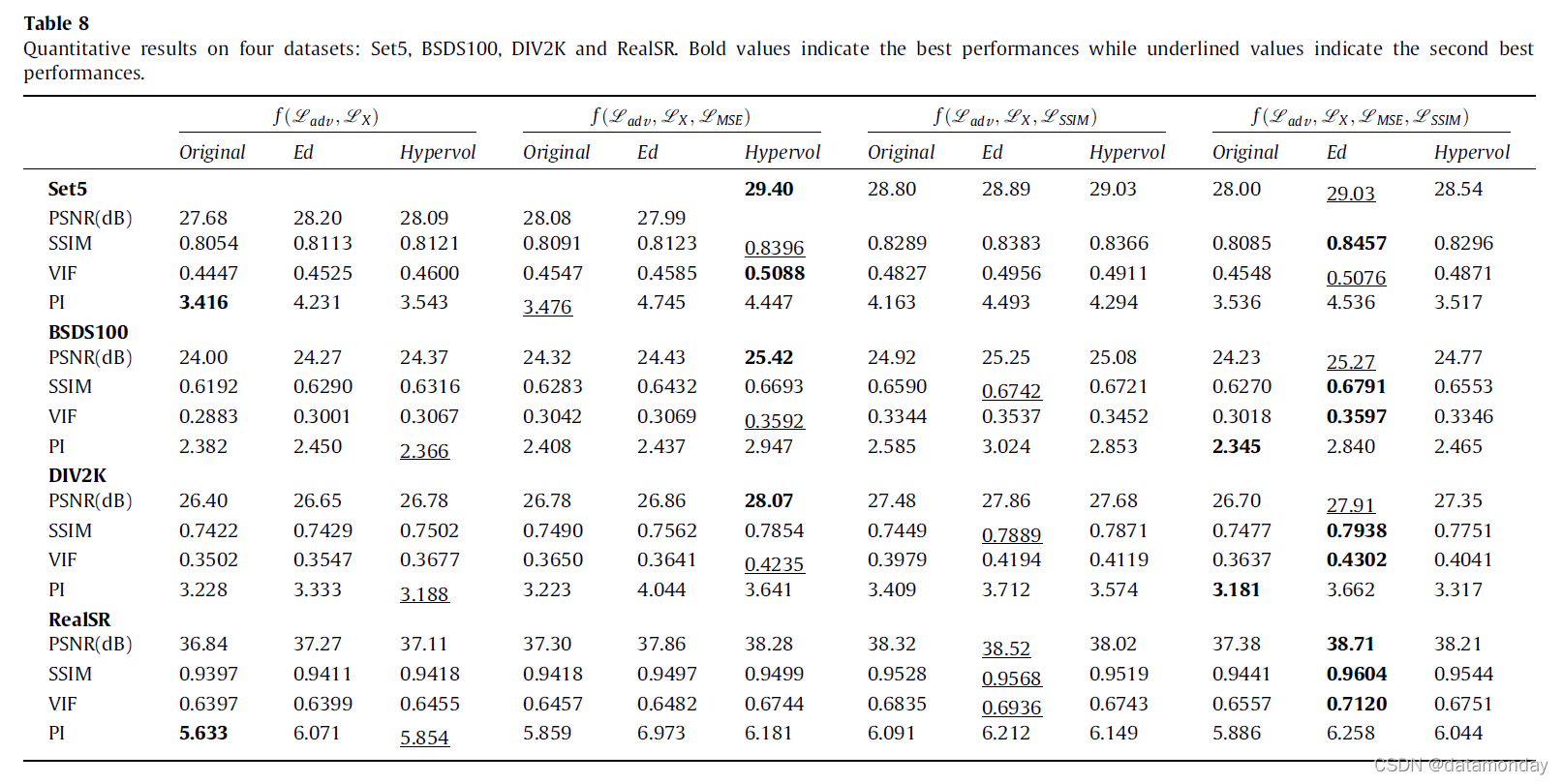
从表 8 中,我们可以发现所提出的训练目标函数 Ed 公式在提升模型性能方面是有效的。与使用固定损失权重定义的原始公式相比,所提出的方法和 Hypervol 公式很好地利用了自适应权重并获得了更好的性能。此外,研究表明,将其他损失作为正则化的额外约束是有益且必要的。其中,SSIM 损失是训练 GAN 模型生成高质量图像最有意义的损失。正如对使用不同训练目标函数训练的模型生成的图像的质量评估所反映的那样,使用训练目标函数 f ( L a d v , L X , L S S I M ) f(L_{adv}, L_X, L_{SSIM})f(Ladv,LX,LSSIM) 的模型;通常产生的图像比使用训练目标函数 f ( L a d v , L X , L M S E ) f(L_{adv}, L_X, L_{MSE})f(Ladv,LX,LMSE) 的图像得分更高。来自训练目标函数 f ( L a d v , L X , L M S E , L S S I M ) f(L_{adv}, L_X, L_{MSE}, L_{SSIM})f(Ladv,LX,LMSE,LSSIM) 的实验,我们可以发现,与多个损失分量的线性组合相比,所提出的 Ed 公式提供了有效的替代方案来提高生成图像的质量。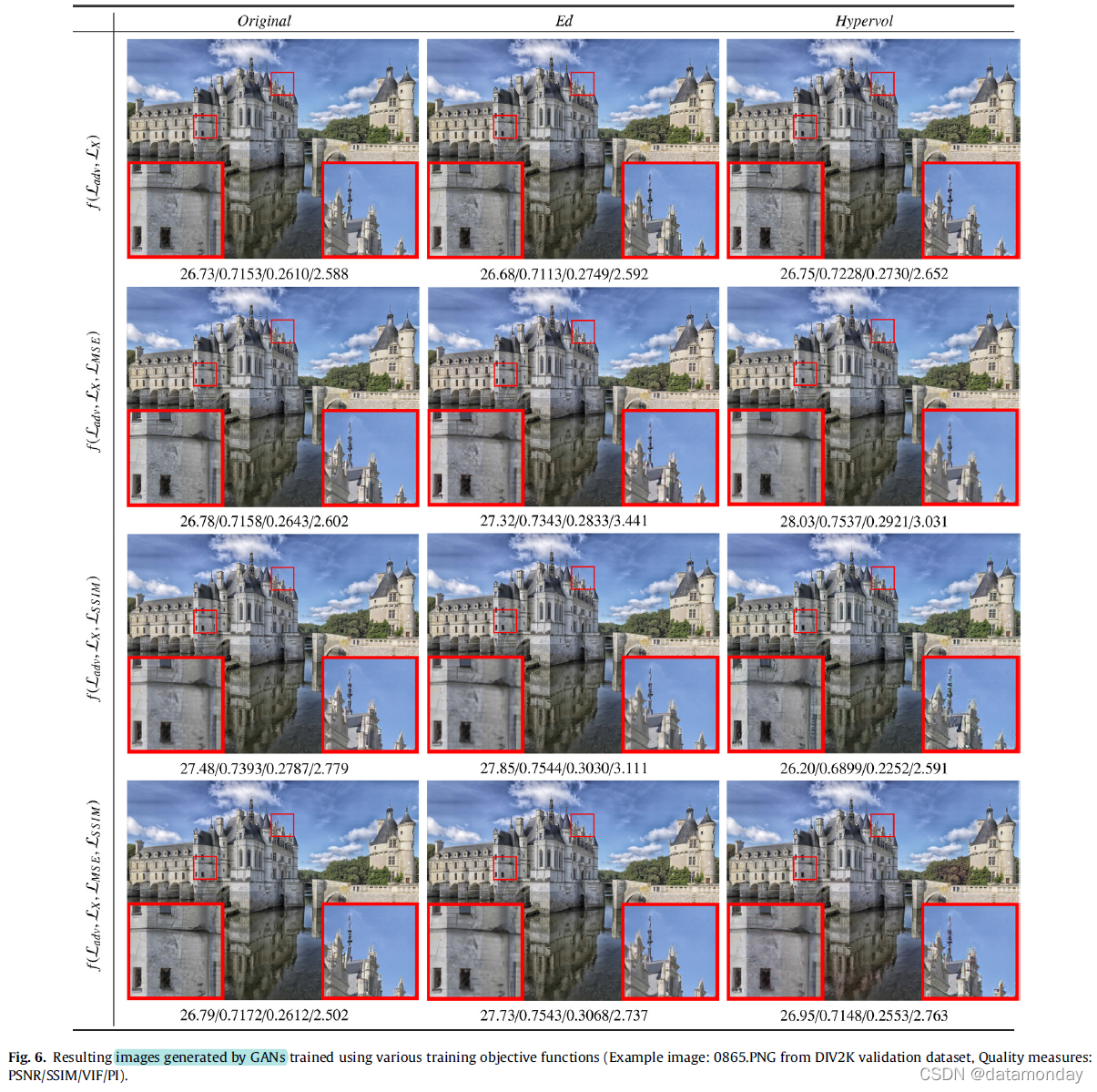
对于视觉评估,图 6 包含用于纹理细节观察的提取补丁的示例结果(放大时可以找到更精细的细节),因为整体视觉差异太微不足道而无法区分。我们可以观察到 Ed 公式引入了模糊伪影,而 Hypervol 公式能够恢复更精细的细节。此外,虽然 SSIM 损失对于定量提高图像质量很有用,视觉图像质量并没有从参与中受益,因为奇怪的伪影明显存在于小块中。而 MSE 损失更适合在各种配方中采用并生成高质量的图像。
4.2. Deblurring
在本文中,我们还提出了一个名为 MixNet 的去模糊网络。我们采用密集连接的编码器-解码器结构来追求强大的去模糊性能。我们删除了 [81] 中使用的所有参数共享。这并不意味着参数共享没有用,但是参数共享在尺度内、跨尺度和多尺度结构中的组合会导致对共享参数的优化产生更多的遏制,从而可能导致性能变差。此外,我们移除了多尺度结构以进一步简化网络。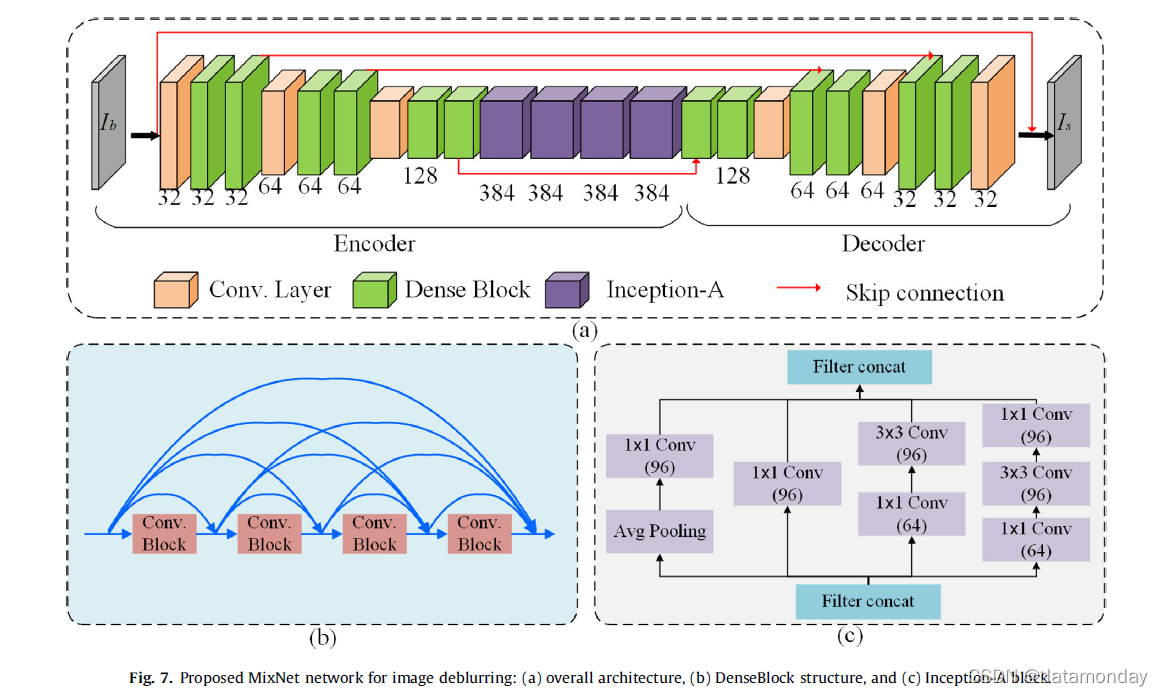
网络架构:如图 7 所示,网络由卷积层、DenseBlocks 和 Inception-A 块组成,其中 Ib 和 Is 分别表示输入模糊图像和输出图像。网络的主干采用 DenseBlocks 和 ResBlock 作为增强感受野的元素。默认情况下,每个非线性 DenseBlock 模块有四个处理单元。使用的 ResBlock 的结构如图 7 所示,包括两个卷积层。对于框架,我们去除了多尺度结构和参数共享机制,从而简化了网络。编码器-解码器结构基于 12 个具有独立参数的 DenseBlock。我们在网络中间添加了四个 Inception-A 块,以扩大特征图。 Inception-A 是 Inception-v4 的组件之一,具有适合图像恢复的输入大小和特征图宽度,包含 382 个通道。对于 Inception-v4,有五种类型的块:Inception-A、Reduction-A、Inception-B、Reduction-B 和 Inception-C。但是这些块,除了 Inception-A,有超过 1000 个特征,因此不适合图像重建。通过采用 inception-A,所提出的网络具有来自 DenseNet 和 Inception-A 网络的混合特征提取机制,因此被称为MixNet。与使用 5 × 5 的内核大小不同 [50,80],我们使用 3 × 3 的内核大小来控制模型大小,因为 2 层有 3 × 3 个内核可以覆盖与 5 个层相同的感受野 5 × 5 个内核,但节省了大约 25% 的参数。
损失函数是图像去模糊网络的另一个重要元素。根据第 2 节的回顾,MSE 损失被称为图像去模糊最重要的损失。它与 PSNR 直接相关,PSNR 是性能评估中最重要的衡量标准之一,如下所示:
因此,在这项工作中,我们采用 MSE 损失作为损失函数。根据我们的经验,添加其他辅助损失(例如 SSIM 损失或对抗性损失)可能并不总是对去模糊产生显著影响。
实施:我们在 NVIDIA Tesla P100 GPU 上实施了 TensorFlow [264] 提出的 MixNet。从一个模糊的 256×256 区域和它在同一位置的被随机裁剪出来的真实图像作为训练输入。在训练期间将批量大小设置为 16。使用 Xavier 方法 [265] 初始化所有权重,并将偏差初始化为零。使用默认设置 beta1=0.9, beta2=0.999, epsilon=10^-8 的 Adam 方法 [266] 优化网络。学习率最初设置为 0.0001,然后使用 0.3 的幂指数衰减到 0。根据实验,2000 个 epoch 足以使网络收敛。
结果和比较:我们对提出的 MixNet 进行了实验,并与 GoPro 数据集上动态场景去模糊和非均匀去模糊的最新方法进行了比较。比较的方法包括 DeepDeblur [50]、Scale Recurrent Network (SRN-Deblur) [80]、DSHMN [82]、DeblurGAN [33]、DeblurGANv2 [64]、无监督去模糊 [85]、域空间 [86]、SVRNN [ 89]、Dual Residual [90]、Douglas-Rachford 网络 [87]、区域自适应 [88] 和 Blur2Flow [262]。结果由在默认 GoPro 训练数据集上训练的模型生成,然后在 GoPro 测试数据集上进行测试。对于无监督学习方法、无监督去模糊和特定领域,我们使用了训练数据集中的模糊图像,以及分辨率更高的新 GoPro 数据集中的清晰图像。对于基于核的方法,包括 Blur2Flow 和基于优化的方法,我们在其发布的模型代码上对其进行了测试。定量结果和评价见表 9。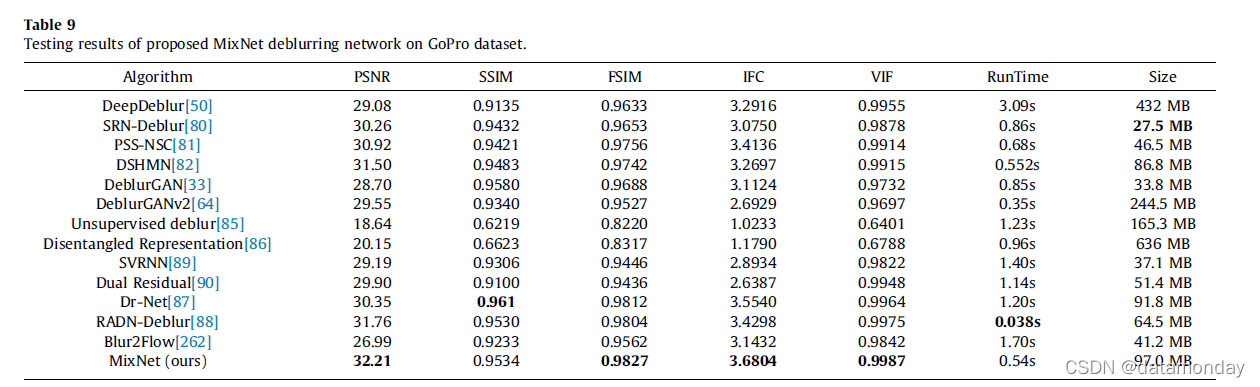
一般来说,无监督学习方法会导致低 PSNR 和 SSIM,正如预期的那样,由于不涉及监督(基本事实)并且无监督学习的数据集大小有限。此外,这些网络主要是为了探索这种训练机制而开发的,而网络结构在很大程度上是不发达的。尽管 Dr-Net 的 SSIM 性能最好,所提出的 MixNet 在所有其他评估标准上都达到了最先进的性能。此外,我们的 MixNet 在运行时间和性能方面取得了很好的平衡,而 Dr-Net 的运行时间是 MixNet 的两倍。 GoPro 评估数据集的视觉比较如图 8 所示。如图所示,所提出的模型通常比其他方法产生更好的结果。域特定网络是无监督去模糊的代表,显然它在颜色上有一定的失真。
我们还在 HIDE 数据集上评估和比较了我们的方法,定量结果如表 10 所示。这些结果是由在默认 HIDE 训练数据集上训练的模型生成的。如图所示,所提出的 MixNet 在所有这些评估标准中都优于或匹配这些最先进的方法。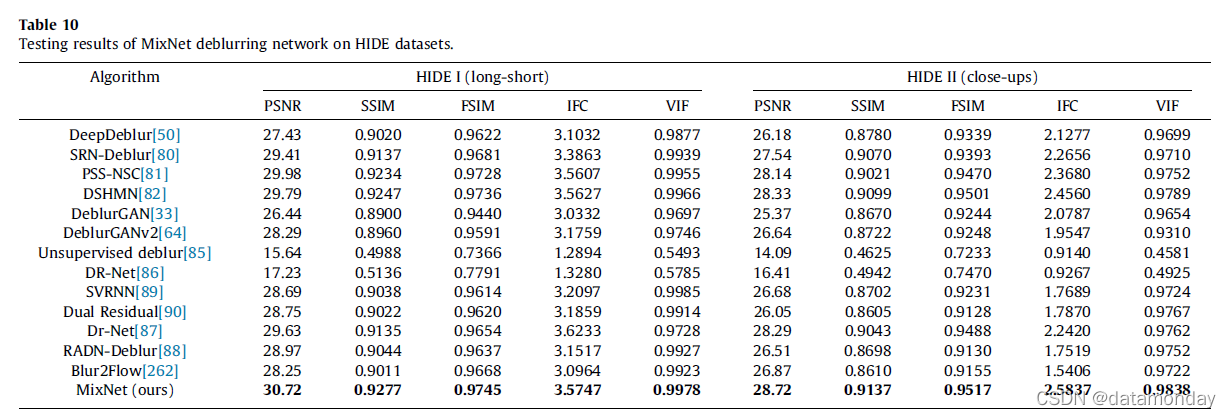
4.3. Contributions
在这里,我们总结了本文的主要贡献。
-
Comprehensive review
对图像恢复、图像去模糊、图像去噪、图像去雾、超分辨率和图像质量评估进行了全面的文献综述。还审查了所有相应的基线深度模型。
-
超分辨率和去模糊的新方法
提出了用于超分辨率的 GAN 训练目标函数的新公式,作为 Hypervol 公式的扩展 [257]。提出了一种新的平衡图像去模糊方法——MixNet。
-
实验验证
进行了广泛的实验,将 Ed 和 Hypervol 公式应用于 SRGAN 的各种训练目标函数以实现超分辨率,并获得了改进。进行了实验以将提出的 MixNet 与最先进的去模糊方法进行比较,结果表明,与主流图像去模糊网络相比,MixNet 具有更好的性能。
5. Conclusions and Discussion
图像恢复(Image denoising)是一项具有挑战性的图像处理任务,因为它具有不适定性(ill-posed nature)。传统方法依赖于手工模型来构建退化机制和噪声模型。在实践中,退化机制和噪声模型很少是简单和统一的。因此,基于学习的方法变得更加适用,并且通常明显优于传统方法。深度学习网络特别流行,从去模糊、去噪和去雾到超分辨率,已经有大量的研究。我们全面回顾了这些任务的方法,并总结了典型和有用的机制及其对各种恢复任务的好处。我们还提出了某些训练目标和超分辨率的新公式,以及用于盲单图像去模糊的有效深度网络。实验结果证明了它们相对于最先进的方法的好处和改进的性能。
图像去噪(Image denoising)对于低级视觉和信号处理具有非凡的价值,可以作为从贝叶斯角度评估图像先验和优化方法的理想测试平台。传统上,图像去噪方法受到现有信号去噪方法的启发。基于学习的方法可以显着提高性能并在几乎没有先验知识的情况下恢复清晰的图像。然而,最近的研究主要基于合成的噪声图像而不是真实世界的噪声图像,其分布是未知的,并且很少像通常假设的那样是高斯分布。现实世界的图像去噪仍将是一个挑战。
精细细节重建(Fine-detail reconstruction)是图像去模糊的最终目的,使用自然场景统计等专家知识或深度神经网络学习的特征。这些图像先验被用作解决图像去模糊问题的正则化技术,添加到成本函数中以在优化期间最小化。由于动态场景模糊在整个图像中本质上是变化的,因此很难采用手工方法来估计内核以进行恢复。相反,训练端到端的深度神经网络具有强大的学习能力,可以逼近退化的输入图像和干净的输出图像之间的映射。然而,仔细校准网络架构和参数是必要的,并且需要付出专门的努力才能优化模型性能。
从退化的低分辨率版本重建高分辨率图像不仅涉及维数增加,还涉及反卷积。在给定图像的基础上,通过经典双三次函数或深度神经网络学习来估计要插值的像素。深度学习神经网络已被证明可以产生卓越的性能。深度神经网络中的非采样层会插入子像素并增加图像维度,从而可以重新缩放图像并通过更精细的细节和纹理进一步提高质量。此外,由于训练目标函数经常使用各种损失作为解空间的约束,它还决定了优化的方向,从而决定了性能。基于图像质量度量的损失被证明可以有效地提高模型性能,并且采用简单方便。
尽管大多数深度学习方法都基于监督学习,但无监督或半监督学习也可以在更好的数据表示方面有利于图像恢复,因此越来越多地与监督机制相结合。在这个方向上的进一步开发可以使恢复任务更加高效和有效。图和自组织结构可以集成到深度网络中的监督学习方案中,使不适定逆问题(ill-posed inverse problems)更站得住脚,更有效,并且更少依赖大量配对训练样本。